 Know your data much faster with the new Sweetviz Python library
Know your data much faster with the new Sweetviz Python library
 Know your data much faster with the new Sweetviz Python library
Know your data much faster with the new Sweetviz Python libraryOne of the latest exploratory data analysis libraries is a new open-source Python library called Sweetviz, for just the purposes of finding out data types, missing information, distribution of values, correlations, etc. Find out more about the library and how to use it here.
By Francois Bertrand, Designer for data visualization and games
This is the second article on Sweetviz, which goes into more detail on comparative analysis, new features, general use cases, and also uses a different dataset. You can find the original article here.
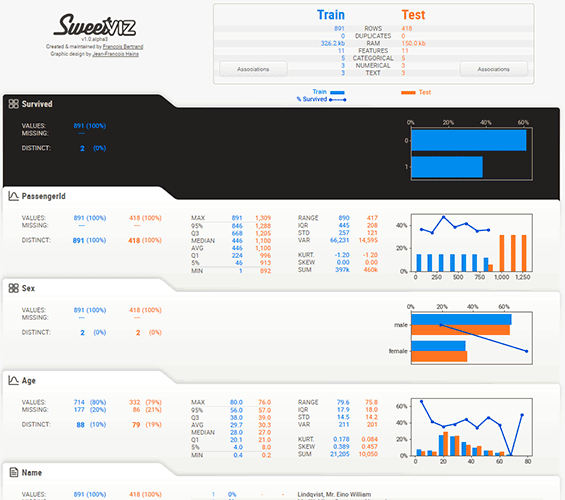
Exploratory data analysis (EDA) is an essential early step in most data science projects and it often consists of taking the same steps to characterize a dataset (e.g. find out data types, missing information, distribution of values, correlations, etc.). Given the repetitiveness and similarity of such tasks, there are a few libraries that automate and help kickstart the process.
One of the latest is a new open-source Python library called Sweetviz (GitHub), created by a few contributors and myself for just that purpose. It takes pandas dataframes and creates a self-contained HTML report that can be viewed by itself in a browser or integrated into notebooks.
It packs a powerful punch; in addition to creating insightful and beautiful visualizations with just two lines of code, it provides analysis that would take a lot more time to generate manually, including some that no other library provides so quickly such as:
- Target analysis: shows how a target value (e.g. "Survived" in the Titanic dataset) relates to other features
- Dataset comparisons: between datasets (e.g. "Train vs Test") and intra-set (e.g. "Male vs Female")
- Correlation/associations: full integration of numerical and categorical data correlations and associations, all in one graph and table
Other references/examples:
- Google Colab notebook with documentation & examples of integration
- Sample report for the well-known sample Titanic Survivor dataset
- GitHub page (full docs & usage)
EDA made… fun?!
Being able to get so much information so quickly about the target value and compare different areas of the dataset transforms this initial step from being tedious to being faster, interesting and even to some degree… fun! (to this data geek, at least!) Of course EDA is a much longer process but at least that first step is a lot smoother. Let’s see how it works out with an actual dataset.
Creating a report
Once your data is loaded, creating a report is a quick 2-line process.
For this article, we will be using a cleaned-up version of the Credit Card Customers dataset described here. You can download the cleaned-up dataset here. The cleanup simply consisted of removing the last 2 columns as mentioned in the description, and the "Attrition_Flag" variable was turned into a boolean, as intended.
After installation of Sweetviz (using pip install sweetviz), load the pandas dataframe(s) as you normally would:
import sweetviz
import pandas as pd
df = pd.read_csv("BankChurners_clean.csv")
Step 1: create the report
To create a report, you can call either:
- analyze() for a single dataset
- compare() to compare 2 datasets (e.g. Test versus Train)
- compare_intra() to compare 2 sub-populations within a same dataset
In our case, we have a single dataset, so let's analyze() it. Importantly, we would like to get information on our target variable "Attrition_Flag", so let's specify it:
report = sweetviz.analyze(df, "Attrition_Flag")
Step 2: generate output
Once we have our report object, it can generate a standalone HTML application (HTML page) or embed the report inside a Notebook. You can refer to the usage examples/documentation (here & here) for more details. Now, let's generate a standalone HTML application:
report.show_html()
With the default options, this will create a file "SWEETVIZ_REPORT.html" and pop open a browser. You can consult the full report generated here. If you are operating inside a notebook, that file will be generated but the browser may not pop up (using show_notebook() is recommended for notebooks, see documentation).
Output options include:
- Layout (widescreen or vertical)
- Scaling
- Window size (for notebooks)
The Sweetviz report
I could (and actually might!) spend an entire article on specific components of the Sweetviz report, since they each bring their own unique insights. For now, here's a quick overview of all its components for this example case.
Overview
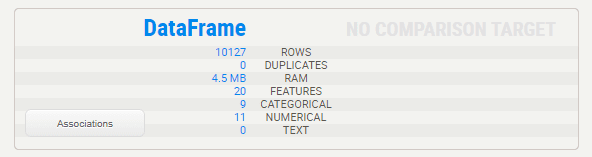
On top of the report, a simple overview of the dataset (along with comparison if comparing). For each feature, Sweetviz will do a best guess at determining the data type of each column, between:
- numerical
- categorical/boolean
- text (default/fallback)
Note that these can be overridden using "FeatureConfig" (see documentation).
Associations/correlations
The "Associations" button unlocks a very powerful analysis of associations and correlations. This graph is a composite of the visuals from Drazen Zaric: Better Heatmaps and Correlation Matrix Plots in Python and concepts from Shaked Zychlinski: The Search for Categorical Correlation.
Basically, in addition to showing the traditional numerical correlations, it unifies in a single graph both numerical correlation, the uncertainty coefficient (for categorical-categorical) and correlation ratio (for categorical-numerical). Note that the trivial diagonal is left empty, for clarity.
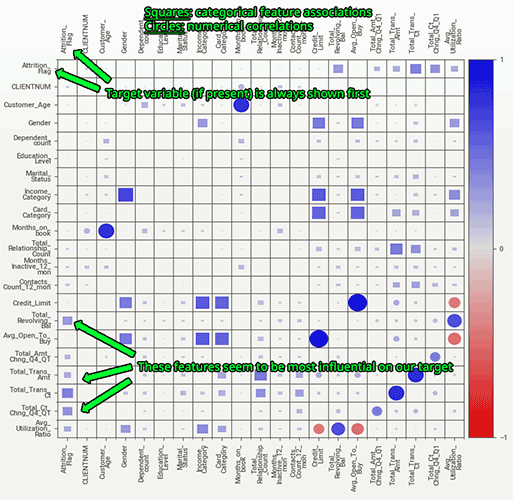

The same data is also found in the "detail" pane of each variable (more on it later):
It is worth noting these correlation/association methods should not be taken as absolute, as they make some assumptions on the underlying distribution of data and relationships. However they can be a very useful starting point.
Target analysis
When analyzing a dataset that has a target variable, this feature is incredibly insightful.
If we specify a target variable (only boolean and numerical are supported currently), it is displayed prominently as the first variable and uses black coloring.

Most importantly, its value is overlaid on top of every other graph, quickly giving an insight on the distribution of the target with regard to every other variable.
At a glance, you can immediately spot how the target value is influenced by other variables. As expected, this generally follows what is found in the "Associations" graph, but gives you specifics for each variable. Here is an example:

IMPORTANT TIP: remember that you can use Target Analysis to analyze ANY feature with respect to all the others. This can be of great assistance to understand how features relate to each other, even if there is no "actual" target variable in the data you are analyzing.
General feature analysis
The bulk of the report is the summary and detail information for each feature:
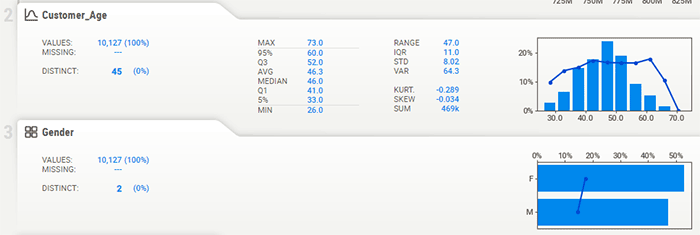
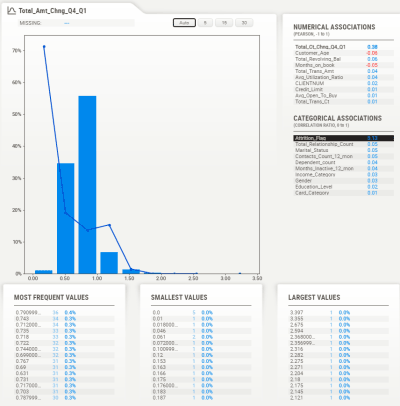
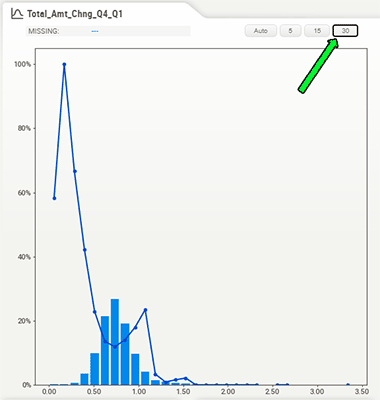
Note that for numerical data, you can change the number of "bins" in the graph, to better gauge distribution, as well as how the target feature correlates. For example, in the above screenshot if we changed the number of bins to 30, we can get a clearer picture of how the target changes with this feature:
Comparing datasets and sub-populations (e.g. Male vs Female)
Sweetviz can compare two different datasets which can be extremely useful (e.g. Train vs Test data). But even if you are only looking at a single dataset, you can study the characteristics of different subpopulations within that dataset.
Let's do an example using the above feature that looked interesting. It seems that when the value of "Total_Ct_Chng_Q4_Q1" is below about 0.6, the Attrition_Flag is significantly higher.
We can isolate that population by using the compare_intra() function and give that condition to split the population (as well as give the low/high populations a more descriptive name):
report = sweetviz.compare_intra(df, df["Total_Ct_Chng_Q4_Q1"] < 0.6, ["Low_Ct_Chng_Q1Q4", "High_Ct_Chng_Q1Q4"], "Attrition_Flag")
This will output the following report, which quickly gives us a lot of new insights on the data. Just looking at the first two variables, we can immediately see that Customer_Age and Gender behave very differently when populations are split using this "Total_Ct_Chng_Q4_Q1" feature, as compared to their general distributions:
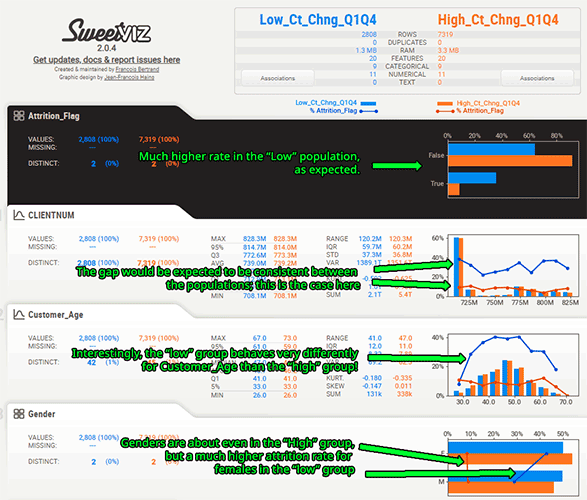
You can access the full report here.
Usage scenarios & conclusion
With target analysis, dataset/intra-set comparisons, full feature analysis and unified association/correlation data, Sweetviz provides an unparalleled wealth of insights with just 2 lines of code.
Of course, analyzing a dataset is a longer and artful process, but Sweetviz can bring early insights and save hours of work, especially in the initial, often tedious stages of EDA.
After the EDA, Sweetviz keep providing value by helping with:
- Feature engineering: visualize how engineered features perform/correlate relative to other features and the target variable
- Testing: confirm the makeup & balance of testing/validation sets
- Interpretation/communication: the generated graphs can provide insights that are easily interpretable (e.g. screenshots above) and can be passed amongst a team or to clients quickly, without any extra work
I enjoy using the library and how it helps throughout my workflow, and I hope you will find it as useful as I do!
Bio: Francois Bertrand is a 20-year veteran coder & designer for data visualization and games.
Related:
- Powerful Exploratory Data Analysis in just two lines of code
- How to create stunning visualizations using python from scratch
- Beautiful decision tree visualizations with dtreeviz