Improving model performance through human participation
Certain industries, such as medicine and finance, are sensitive to false positives. Using human input in the model inference loop can increase the final precision and recall. Here, we describe how to incorporate human feedback at inference time, so that Machines + Humans = Higher Precision & Recall.
By Preetam Joshi, Sr. SW Engineer at Netflix and Mudit Jain, SW Engineer at Google.

Humans + AI (Image credit: Pixabay).
Certain domains are highly sensitive to false positives. An example of this is credit card fraud detection, where falsely classifying an activity as fraudulent can have a significant negative impact on the reputation of the financial institution that issued the credit card [1]. Another example is automated chatbots that use language models (think GPT-3) to generate text responses to customer questions [2]. Vetting the text generated is important to ensure that, at the very least, inappropriate language is not being generated (like hate speech, foul words etc.).
Another highly sensitive domain is the medical field, where something like a cancer diagnosis is extremely sensitive to false positives [3]. In the sections below, we will first describe a system that uses an ML model for inference and then detail the modifications needed to include human agents in the inference loop.
Model-Based Inference
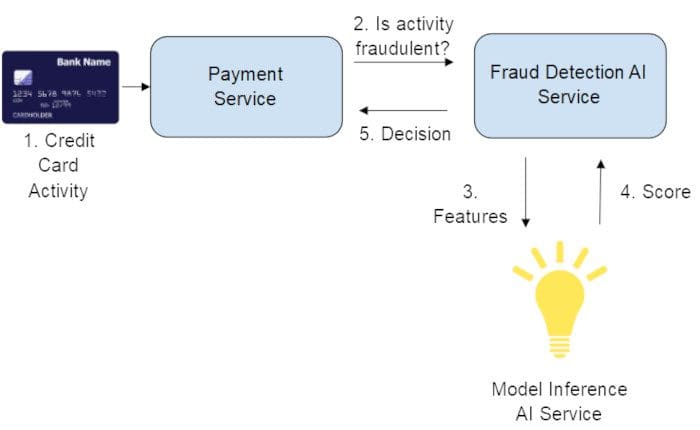
Fig. 1. Classic model inference system.
Let’s start with a typical system that serves a machine learning model for the credit card fraud use case. Fig. 1 shows a simplified view of a system and the sequence of events where the model alone is responsible for making a decision on whether a given activity is fraudulent.
How to choose the threshold?
The threshold is chosen based on the requirements for precision and recall [5]. In the example shown in Fig. 1, Precision is defined as the number of correctly predicted fraudulent activities (true positives) divided by the total number of activities predicted to be fraudulent (true positives + false positives). Recall is defined as the number of correctly predicted fraudulent activities (true positives) divided by the sum of the number of activities correctly predicted as fraud, and the number of actual fraudulent activities predicted to be non-fraudulent (true positives + false negatives). In most cases, a trade-off between precision and recall needs to be made to achieve the goals of the system. A useful tool that helps with this trade-off is the Precision-Recall curve. Fig. 2 illustrates a Precision-Recall curve.

Fig. 2. Precision-Recall curve.
Notice how precision decreases at higher levels of recall. At a recall of 0.72, the precision tapers down to approximately 0.4. To catch 70% of fraud cases, we would incur a high number of false positives at a precision of 40%. For our case, the number of false positives is not acceptable as that would lead to a very bad customer experience. We need higher precision at reasonable amounts of recall. Note that what qualifies as a reasonable number of false positives is subjective. For our use case, from Fig. 1, we would require a precision greater than 0.99.
Although we made a trade-off in favor of higher precision, at 0.99 precision, the recall is 0.15, which is not sufficient. To achieve higher recall, we will get lower precision that is not acceptable for the business. In the next section, we will discuss how human input can be leveraged to achieve higher levels of overall precision at higher recall.
Human Participation
Fig. 3 shows a modified system that includes human interaction.

Fig. 3. Improving model performance with human interaction.
One way to increase recall is to involve human agents in the inference loop. In this setup, a subset of activities where the model confidence is low is sent to a human agent for manual inspection. When choosing a threshold that determines the subset of predictions that qualify as low confidence/ambiguous predictions, it is important to consider the volume of ambiguous activities that will be sent to human agents since the latter is a scarce resource. To aid in choosing the threshold, the precision-recall-threshold graph can be used (Fig. 4).
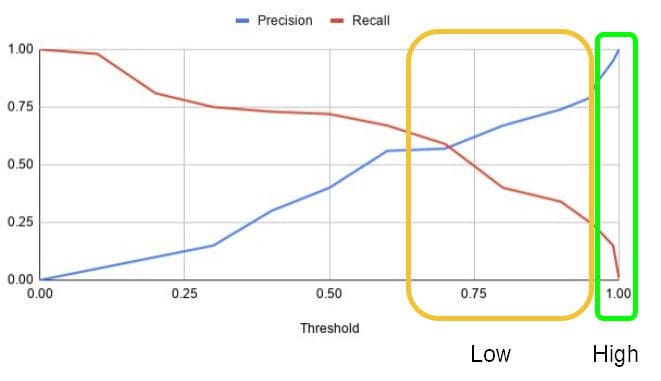
Fig. 4. Precision-Recall-Threshold curve.
In our case, let’s assume that a score closer to 1.0 denotes a positive label (fraud), and a score closer to 0.0 denotes a negative label (non-fraud). There are two regions highlighted in Fig. 4:
- The green region denotes the high confidence region for a positive label, i.e., where automated model decisions are allowed, and the resulting model precision is acceptable (the low rate of false positives is generally well tolerated by the end-users being affected).
- The yellow region denotes an area of low confidence for positive labels where automated model decisions have precision levels that are not acceptable (the high rate of false positives result in a significant negative impact on the business)
The yellow region is the area that is a good candidate for using human agents to increase precision via manual inspection. The same process can be used to reason about the negative labels - the area closer to 0.0 is a high confidence region, and above a certain threshold, the outcome is fuzzy. Either all items or a subset of items from the yellow regions can be sent for manual inspection. During a manual inspection, the human agent spends time deciding the final outcome of the activity - in our case, fraud or not - using their discretion and judgment developed through a rigorous training process. The key assumption here is that human agents are better than the ML model in terms of making decisions on ambiguous cases.
As mentioned earlier, human resources are scarce. Hence, the volume of the requests sent to the human agents is an important consideration when choosing the threshold. Fig. 5 shows an example of volume and recall plotted against the threshold. Volume is defined as the number of items per hour that will be sent to the human agents for review. From Fig. 5, the volume at a threshold of 0.7 is 16K items (per hour).
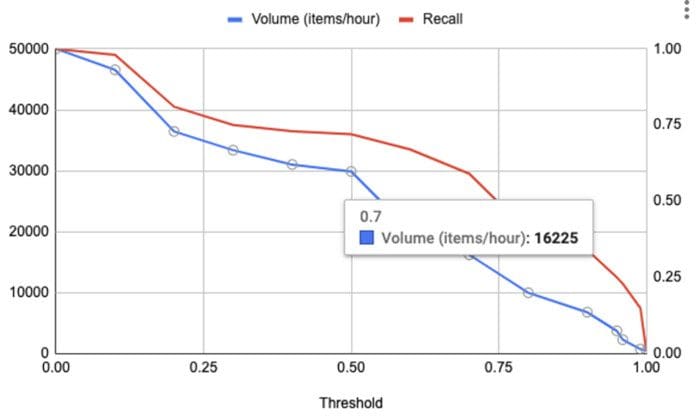
Fig. 5. Plot of Volume (num requests/hour) and Recall against Threshold.
Both the graphs depicted in Fig. 4 and Fig. 5 can be used to pick the right threshold for the desired recall at an acceptable human review volume. Let’s do a quick exercise in determining the threshold from these two plots. At a recall level of 0.59 (threshold of 0.7), the volume (see Fig. 5) would be about 16K items/hour. The model precision is about 0.6 (see Fig. 4) at the same recall level. Assuming the human agent pool is able to handle the volume of 16K items/hour and also assuming that the precision and recall of a human agent is 95%, the resulting precision after human review at a recall level of 0.59 will be between 0.95 and 0.99. In sum, using this setup, we were able to increase recall to 0.56 (0.59 [model] * 0.95 [human]) from 0.15 while maintaining a precision level greater than 0.95.
Best Practices when using Human Agents
In order to achieve high-quality human reviews, it is important to set up a well-defined training process for the human agents who will be responsible for reviewing items manually. A well-thought-out training plan and a regular feedback loop for the human agents will help maintain the high-quality bar of the manually reviewed items over time. This rigorous training and feedback loop help minimize human error in addition to helping maintain SLA requirements for per item decisions.
Another strategy that is slightly more expensive is to use a best-of-3 approach for each item that is manually reviewed, i.e., use 3 agents to review the same item and take the majority vote from the 3 agents to decide the final outcome. In addition, log the disagreements between the agents so that the teams can retrospect on these disagreements to refine their judging policies.
Best practices applicable to microservices apply here as well. This includes appropriate monitoring of the following:
- End-to-end latency of an item from the time it was received in the system to the time a decision was made on it
- Overall health of the agent pool
- Volume of items sent for human review
- Hourly statistics on the classification of items
Finally, model precision and recall can shift over time due to various reasons [4]. It is important to revisit the chosen thresholds by keeping track of the precision/recall.
Conclusion
We reviewed how an ML inference system involving human agents could help increase recall while maintaining high levels of precision. This approach is particularly useful in use cases that are sensitive to false positives. A precision-recall-threshold curve is a great tool in choosing the threshold for human review and automated model decisions. Involving human agents, however, does incur an increase in cost and could cause bottlenecks in scaling a system that is experiencing hyper growth. Carefully making trade-offs on these aspects is important when considering such a system.
References
- FCase Article https://fcase.io/a-major-challenge-false-positives/#twelve
- The famous issue with the Microsoft chatbot https://spectrum.ieee.org/tech-talk/artificial-intelligence/machine-learning/in-2016-microsofts-racist-chatbot-revealed-the-dangers-of-online-conversation
- False-positive cancer screenings may affect a patient’s willingness to obtain future screening https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5992010/
- “Can You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift”, Yaniv Ovadia et al. https://arxiv.org/abs/1906.02530
- Precision and Recall https://en.wikipedia.org/wiki/Precision_and_recall
Bios: Preetam Joshi is a Senior Software Engineer at Netflix working on applied machine learning and machine learning infrastructure. He has worked at Thumbtack and Yahoo in the past. He received his Masters of Science degree from the College of Computing at Georgia Tech.
Mudit Jain is a Software Engineer at Google working on AutoML NLP for the Google Cloud Platform. He has worked at Microsoft in the past. He received his Bachelor of Technology degree in Computer Science and Engineering from the Indian Institute of Technology, Kanpur.
Related: