 What’s ETL?
What’s ETL?By Omer Mahmood, Head of Cloud Customer Engineering, CPG & Travel at Google
In my last post, I talked about what it means to move machine learning (ML) models into production by introducing the concept of MLOps. This time we’re going to look at the opposite end of the data science steps for ML — data extraction and integration.
The TL;DR
ETL stands for Extract-Transform-Load, it usually involves moving data from one or more sources, making some changes, and then loading it into a new single destination.
- In most companies data tends to be in silos, stored in various formats and is often inaccurate or inconsistent
- This situation is far from ideal if we want to be able to easily analyse and get insights from that data or use it for data science
???????? How we got here
Most ML algorithms require large amounts of training data in order to produce models that can make accurate predictions. They also require good quality training data, representative of the problem we are trying to solve.
To reinforce this point there is a great example I came across, analogous to ‘Maslow’s hierarchy of needs’ that highlights the importance of data collection and storage as it relates to data science:

Figure 1: The Data Science Hierarchy of Needs Pyramid, SOURCE: “THE AI HIERARCHY OF NEEDS” MONICA ROGATI[1]
At the bottom of the pyramid is the basic need to gather the right data, in the right formats and systems, and in the right quantity.
Any application of AI and ML will only be as good as the quality of data collected.
So, let’s say you’ve framed your problem and determined that it’s a good fit for ML. You know what data you need, at least to start experimenting. But unfortunately it’s sitting in different systems and scattered across your organisation.
The next step is to figure out how to bring that data together, transform it as needed, and then land it somewhere as a single integrated dataset. You can only begin to explore the data, carry out feature engineering, and model training once it is accessible — this is where our friendly acronym ETL comes into play!
???? How does it work?
To make it a bit more concrete, let’s use a modern real world ETL example.
Imagine you are an online retailer that uses a Customer Relationship Management (CRM) system such as SalesForce to keep track of your registered customers.
You also use a payment processor such as Stripe to handle and store details of sales transactions made via your e-commerce website.
Suppose your goal is to improve your conversion rate by using data about what your customers purchased historically, to make better product recommendations when they are browsing your website.
You could certainly use an ML model to power a recommendation engine to achieve this goal. But the challenge is that the data you need is sitting in two different systems. The solution in our case is to use an ETL process to extract, transform and combine them into a data warehouse:
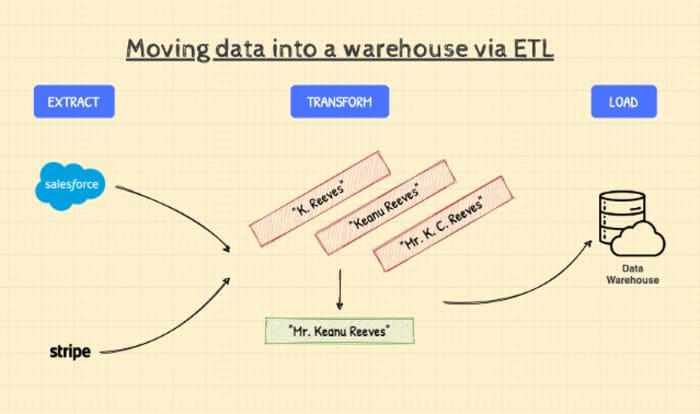
Figure 2: The process of moving data from different sources to a warehouse using ETL. Illustration by the author.
Let’s break down what’s happening in the diagram above:
1. Extract — this part of the process involves retrieving data from our two sources, SalesForce and Stripe. Once the data has been retrieved, the ETL tool will load it into a staging area in preparation for the next step.
2. Transform — this is a critical step, because it handles the specifics of how our data will be integrated. Any cleansing, reformatting, deduplication, and blending of data happens here before it can move further down the pipeline.
In our case, let’s say in one system a customer record is stored with the name “K. Reeves”, in another system that same customer record is stored against the name “Keanu Reeves”.
Assume we know it’s the same customer (based on their shipping address), but the system still needs to reconcile the two, so we don’t end up with duplicate records.
➡️ ETL frameworks and tools provide us with the logic needed to automate this sort of transformation, and can cater for many other scenarios too.
3. Load — involves successfully inserting the incoming data into the target database, data store, or in our case a data warehouse.
So there you have it, we have collected our data, integrated it using an ETL pipeline and loaded it somewhere that is accessible for data science.
???? Side note ????
ETL vs. ELT
You might have also come across the term ‘ELT’. Extract, load, and transform (ELT) differs from ETL solely in where the transformation takes place. In the ELT process, the data transformation occurs in the destination data store.
This can simplify the architecture by removing what is sometimes a separate or intermediate staging system that hosts the data transformation. The other advantage is that you can benefit from the additional scale and compute performance usually present in destinations such as cloud data warehouses.
???? Side note ????
???? Common challenges
OK, all this ETL stuff sounds pretty simple, right? Here are some ‘gotchas’ to look out for:
☄️ Scaling
The amount of data businesses produce is only expected to grow — 175 Zettabytes by 2025 according to a report by IDC[2]. So you should ensure that the ETL tool you choose has the ability to scale to not just your current but also future needs. You may move data in batches now, but will that always be the case? How many jobs can you run in parallel?
Moving to the cloud is a pretty safe bet if you want to future-proof your ETL processes — by having access to theoretically limitless scalability of storage and compute while also reducing your IT capital expenditure.
???? Data Accuracy
Another big ETL challenge is ensuring that the data you transform is accurate and complete. Manual coding and changes or failure to plan and test before running an ETL job can sometimes introduce errors, including loading duplicates, missing data, and other issues.
An ETL tool will definitely reduce the need for hand-coding and help cut down on errors. Data accuracy testing can help spot inconsistencies and duplicates, and monitoring features can help identify instances where you are dealing with incompatible data types and other data management issues.
???? Diversity of Data Sources
Data is growing in volume. But more importantly, it’s growing in complexity. One enterprise could be handling diverse data from hundreds — or even thousands — of data sources. These can include structured and semi-structured sources, real-time sources, flat files, CSVs, object buckets, streaming sources, and whatever new comes along.
Some of this data is best transformed in batches, while for others, streaming, continuous data transformation works better.
Having a strategy for how you intend to cope with different data sources is key. Some modern ETL tools can offer support for a wide variety, including batch and streaming in one place.
????????♀️ So how do I get started?
At this point you should have a good idea why and when you might need to use ETL in your data science workflow. We also covered common challenges to look out for as you begin thinking about your ETL processes.
I’ll close with a simple methodology for choosing an ETL tool, and some other useful resources.
????????♀️ Which ETL tool should I use, and when?
So we understand what happens during ETL, but what does it mean in more practical terms?
You will need to design an ETL pipeline that explicitly describes:
- What data sources to extract from and how to connect to them
- What transformations to carry out on the data once you have it, and finally
- Where to load the data once the pipeline is complete
ETL pipelines can be expressed using a code based framework, or a more popular choice these days is to use ETL tools that provide a ‘drag and drop’ user interface that lets you define the steps in your pipeline in a visual way.
Once you’ve implemented your ETL pipeline, it typically needs to run somewhere i.e. using an ETL tool that will execute your pipeline, and an environment that will provide the resources required to temporarily store and transform your data.
I have tried to simplify the decision-making steps for you in the diagram below (click to zoom in):
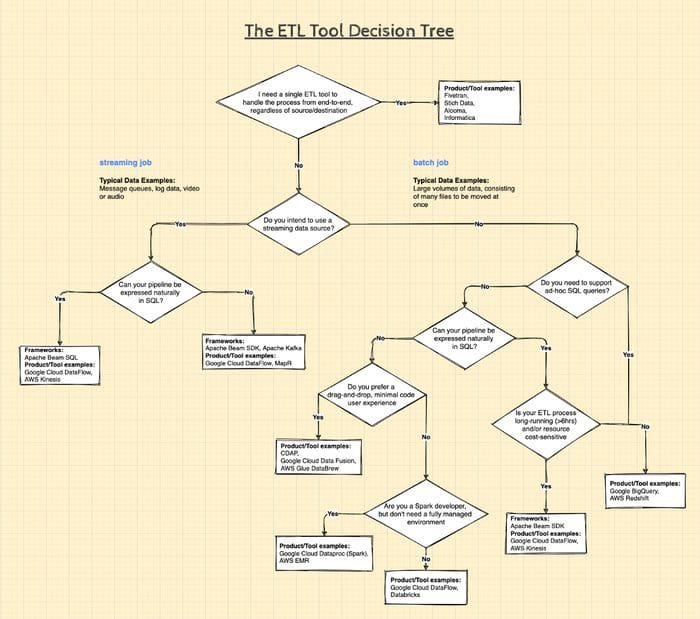
Figure 3: Which ETL tool to use and when. Illustration by the author.
NB. This decision tree is by no means an exhaustive list of either; the decisions you will need to make, frameworks or products available.
Indeed for every intermediate ETL step, there are dozens of open source and proprietary offerings. Ranging from orchestration to scheduling — we’re not going to be able to cover everything here.
The aim of this post was to serve as a springboard into the world of ETL! Good luck on your data integration journey! ????
???? Useful resources and further reading
Links
- Data Preparation and Feature Engineering for Machine Learning
- Gartner — Data Integration Tools Reviews and Ratings
Books
- The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data, Wiley, Authors: Ralph Kimball, Joe Caserta
- Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing, O’Reilly, Authors: Tyler Akidau, Slava Chernyak, Reuven Lax
Data Agnostic ETL tools
???? References
[1] The AI Hierarchy of Needs, Monica Rogati
https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
[2] 175 Zettabytes By 2025, Forbes, Tom Coughlin
https://www.forbes.com/sites/tomcoughlin/2018/11/27/175-zettabytes-by-2025/?sh=6a5d2e7a5459
Bio: Omer Mahmood is Head of Cloud Customer Engineering, CPG & Travel at Google.
Original. Reposted with permission.
Related:
- Introducing dbt, the ETL and ELT Disrupter
- The Role of the Data Engineer is Changing
- Why the Future of ETL Is Not ELT, But EL(T)