The NoSQL Know-It-All Compendium
Are you a NoSQL beginner, but want to become a NoSQL Know-It-All? Well, this is the place for you. Get up to speed on NoSQL technologies from a beginner's point of view, with this collection of related progressive posts on the subject. NoSQL? No problem!
Editor's note: This is a collection of excerpts from KDnuggets articles written by author Alex Williams covering NoSQL topics and concepts for beginners, with links to the full articles for further reading.

What is NoSQL?
NoSQL is essentially the response to SQL’s rigid structure. First created in the early 1970s, NoSQL didn’t really take off until the late 2000s, when Amazon and Google both put a lot of research and development into it. Since then, it’s taken off to be an integral part of the modern world, with many big websites around the world using some form of NoSQL.
So what is NoSQL exactly? Essentially it is a philosophy for creating databases that does not require a schema nor does it store data in a relational model. In fact, NoSQL has a variety of NoSQL Databases to pick from, each with their own specialization and use cases. As such, NoSQL is incredibly diverse when it comes to filling niches, and you can almost certainly find a NoSQL data model to fit your needs.
While SQL is a specific database and language, NoSQL isn’t, but that doesn’t mean that we can’t look at the general philosophies and differences between the two.
Continue reading NoSQL For Beginners.
SQL vs NoSQL
Developers are all too aware of the need for continuing education. Whether there’s a new framework to pick up or a new service to learn, innovation and adaptation are fundamental to development. One of the hottest topics for today is the decision to go with the standard SQL database or to move to a NoSQL database.
NoSQL databases have been around for decades, thanks to the innovation of Carlo Strozzi. However, these databases weren’t in the news much until the early 2000s’. At this time, companies like Google and Amazon began putting more effort into developing NoSQL databases. Despite their recent popularity, many developers, architects, and designers may not be fully up to date with what NoSQL databases offer.
Thus, for a rundown on the differences between the two databases, check out the following 7 key takeaways that every developer should know.
Continue reading SQL vs NoSQL: 7 Key Takeaways.

NoSQL has become increasingly popular as a complementary tool to traditional SQL approaches to databases and database management. As we know, NoSQL doesn’t follow the same relational model that SQL does, which allows it to do quite a lot of powerful things. More importantly, it’s very flexible and scalable, which is excellent for newer projects that don’t have the time or budget to spend on designing an SQL database.
As such, we’re going to take a bit of a deeper look at how different data models work.
Column-Oriented Databases
At a very surface level, column-store databases do exactly what is advertised on the tin: namely, that instead of organizing information into rows, it does so in columns. This essentially makes them function the same way that tables work in relational databases. Of course, since this is a NoSQL database, this data model makes them much more flexible.
More specifically, column databases use the concept of keyspace, which is sort of like a schema in relational models. This keyspace contains all the column families, which then contain rows, which then contain columns. It’s a bit tricky to wrap your head around at first but it’s relatively straightforward.
By taking a quick look, we can see that a column family has several rows. Within each row, there can be several different columns, with different names, links, and even sizes (meaning they don’t need to adhere to a standard). Furthermore, these columns only exist within their own row and can contain a value pair, name, and a timestamp.

Continue reading Column-Oriented Databases, Explained.
Graph Databases
Ironically for a non-relational database, graphs primarily work on the concept of multi-relational data ‘pathways’.
Graph databases are generally straightforward in how they’re structured though. They primarily are composed of two components:
- The Node: This is the actual piece of data itself. It can be the number of viewers of a youtube video, the number of people who have read a tweet, or it could even be basic information such as people’s names, addresses, and so forth.
- The Edge: This explains the actual relationship between two nodes. Interestingly enough, edges can also have their own pieces of information, such as the nature of the relation between two nodes. Similarly, edges might also have directions describing the flow of said data.
Continue reading Graph Databases, Explained.
Document Databases
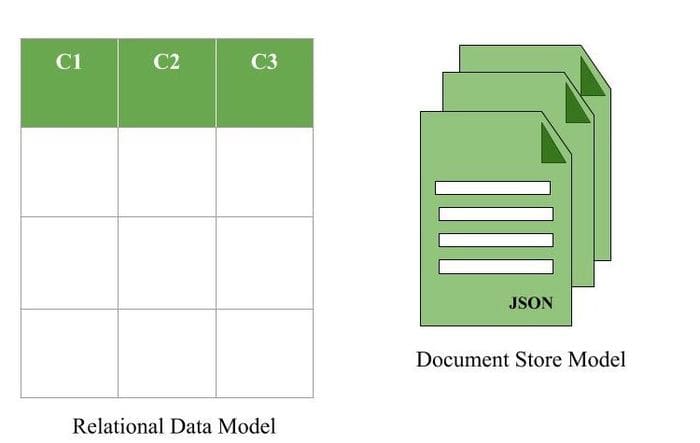
Ostensibly the idea behind document databases is that you can store any sort of information in a document. That means you can mix and match whatever sort of data you want without really having to worry about the database not being able to parse it. Of course, in practice, most document databases still tend to use some form of schema with a file format and some kind of predetermined structure.
Compared to an SQL database which is both tubular and relational, document store doesn’t have the same foibles and restrictions that SQL does. This means it’s much easier to work with the information at hand, and queries can be much easier to carry out. Ironically, the same sort of actions you can perform in an SQL database, you can also perform in a document-store such as deleting, adding, and querying.
As alluded to earlier, each document needs some sort of key, which is provided to it through a unique ID. When the unique ID is provided in any process, the information in the document itself is read and dealt with directly, rather than being taken out on a column by column basis.
Continue reading Document Databases, Explained.
Key-Value Databases
Key-value stores are actually pretty straightforward. A value, which can be basically any piece of data or information, is stored with a key that identifies its location. In fact, this is a design concept that exists in pretty much every piece of programming as an array or map object. The difference here is that it’s stored persistently in a database management system.
What makes key-value stores so popular is that the way information is stored is as a sort of opaque blob, rather than discrete data. As such, there’s really no need to index the database to make it perform faster. Instead, it performs faster on its own due to the way it’s structured. Similarly, it doesn’t really have a language of its own, instead relying on simple get, put and delete commands.
Of course, this comes with the downside that the information you get from a request isn’t filtered. This lack of control of the data can be problematic under certain circumstances but for the most part, it’s worth the exchange. Since key-value stores are fast and reliable, most programmers work around any filter/control issues they may come up against.
Continue reading Key-Value Databases, Explained.
Bio: Alex Williams is a seasoned full-stack developer and the owner of Hosting Data UK. After graduating from the University of London, majoring in IT, Alex worked as a developer leading various projects for clients from all over the world for almost 10 years. Recently, Alex switched to being an independent IT consultant and started his own blog. There, he explores web development, data management, digital marketing, and solutions for online business owners just starting out.
Related: