Graph Databases, Explained
Between the four main NoSQL database types, graph databases are widely appreciated for their application in handling large sets of unstructured data coming from various sources. Let’s talk about how graph databases work and what are their practical uses.
While SQL is a great RDBM and has been used for decades to effectively deal with large quantities of data, the original hardware barriers that created it are no longer around. As such, NoSQL has quickly become the king of modern database management, and many of the biggest sites we rely on today are run off NoSQL, such as Amazon’s DynamoDB, and Twitter’s use of FlockDB.
In fact, that last example, FlockDB, is the type of data model that we’ll look at today: Graph.
Graph databases are an incredible tool for quickly parsing information that a human being can easily consume. By storing data in a way that allows us to represent information on a graph easily, we can get a quicker understanding of the data and gain insights we might not have otherwise had. It also functions great as a database for high-performance, threaded data structures like Twitter.
How does a Graph Database Work?
Ironically for a non-relational database, graphs primarily work on the concept of multi-relational data ‘pathways’.
Graph databases are generally straightforward in how they’re structured though. They primarily are composed of two components:
- The Node: This is the actual piece of data itself. It can be the number of viewers of a youtube video, the number of people who have read a tweet, or it could even be basic information such as people’s names, addresses, and so forth.
- The Edge: This explains the actual relationship between two nodes. Interestingly enough, edges can also have their own pieces of information, such as the nature of the relation between two nodes. Similarly, edges might also have directions describing the flow of said data.
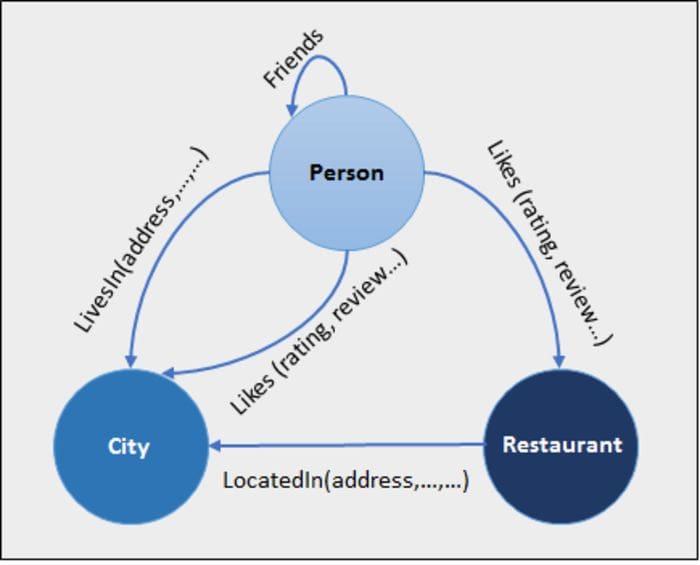
The information used in graph databases can be essentially anything, and as you can see from the structure above, are pretty simple to plot out and to understand at a fundamental level. In fact, a lot of modern graph databases are starting to include this sort of quick visualization that doesn’t require complex database language knowledge, with a good recent example being MongoDB.
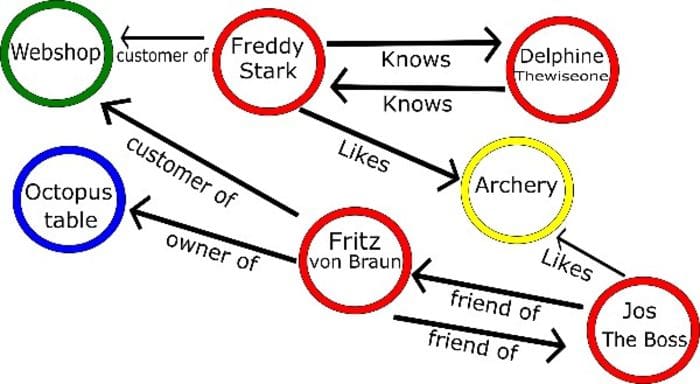
Taking a look at a more specific example, as you can see in the image above, graph databases can not only describe the complex relationship between a group of people but also their interests, likes, their friendships, and businesses. Of course, the sky (and hardware) is the limit here, and you can get pretty complex when building a graph database.
Examples of Graph Databases
While graph databases aren’t as incredibly popular as some other NoSQL databases, there are a few that have become pretty standard when talking about NoSQL:
Neo4j: One of the top graph databases in the world, it’s both open-source and interestingly built on Java. It also has its own language, called Cypher, which is similar to declarative SQL language, but made to fit graphs. It also supports popular languages besides Java, such as Python, .NET, JavaScript, and a few more.
Neo4j is ideal for things such as data center management and fraud detection.
RedisGraph: RedisGraph is actually a graph module built into Redis, which itself is a key-value NoSQL database. Because Redis itself is built on in-memory data structures, RedisGraph is made to have data stored in Ram. This leads to a high-performance graph database, with fast querying and indexing.
RedisGraph also uses Cypher, which is great if you want to get more database flexibility as a programmer or data scientist. Primary uses are any application that requires truly lightning-fast performance.
OrientDB: Interestingly enough, OrientDB is a mix of different types of data models, and supports graph, document store, key-value store, and object-based. That being said, the relationships are all stored using the graph model that uses direct connections between databases.
Much like the previous two graph databases, OrientDB is also open-source, and like Neo4j, it’s written in Java (although unfortunately, it doesn’t use Cypher). The idea behind OrientDB is for use where multiple data models are required and is therefore optimized for data consistency, as well as keeping data complexity down.
Conclusion
As you can see, graph databases can be really versatile when it comes to showing how different sets of data relate to each other. Beyond just expression information in a graphical and efficient manner, graph databases can also be used to deliver content in high-performance situations, while creating threads that are easy to understand for the average user (such as in the case of Twitter).
Bio: Alex Williams is a seasoned full-stack developer and the owner of Hosting Data UK. After graduating from the University of London, majoring in IT, Alex worked as a developer leading various projects for clients from all over the world for almost 10 years. Recently, Alex switched to being an independent IT consultant and started his own blog. There, he explores web development, data management, digital marketing, and solutions for online business owners just starting out.
Related: