Top NoSQL Database Engines
An overview of the top 5 NoSQL database engines in use today, including examples of key-value, column-oriented, graph, and document paradigms.
I am not a fan of the term NoSQL. Many others are, however, and it has become a permanent part of the collective data storage nomenclature, meant to describe schema-less, non-relational data storage schemes.
NoSQL is an umbrella term, one which encompasses a number of different technologies. These different technologies aren't even necessarily related in any way beyond the single defining characteristic of NoSQL: they are not relational in nature; for right or wrong, Structured Query Language (SQL) has become conflated with relational database management systems over the years. So, while I am not personally a fan of the term NoSQL, I can appreciate why others are, given that it quickly implies what it is we are talking about by explicitly stating what we are not talking about. As such, I grin and bear its usage.
Fan or not of the term, the various NoSQL technologies are welcome and necessary parts of today's data landscape. Key-value stores, document stores, graph databases, and other non-relational data storage paradigms allow for speed, flexibility, and scalability when storing and accessing unstructured data. But there are an awful lot of NoSQL database (or data store) engines available today. Which are the most-used, and what are the differences? This post explores this topic.
The methodology used to determine the top NoSQL database engines was to take the non-relational and non-search engine entries at respected topic observer db-engines.com and compare them with Google Trends results of the same search terms. The separate methodologies confidently produced the same top 5 candidates, making it easy to settle on which to select for this post.
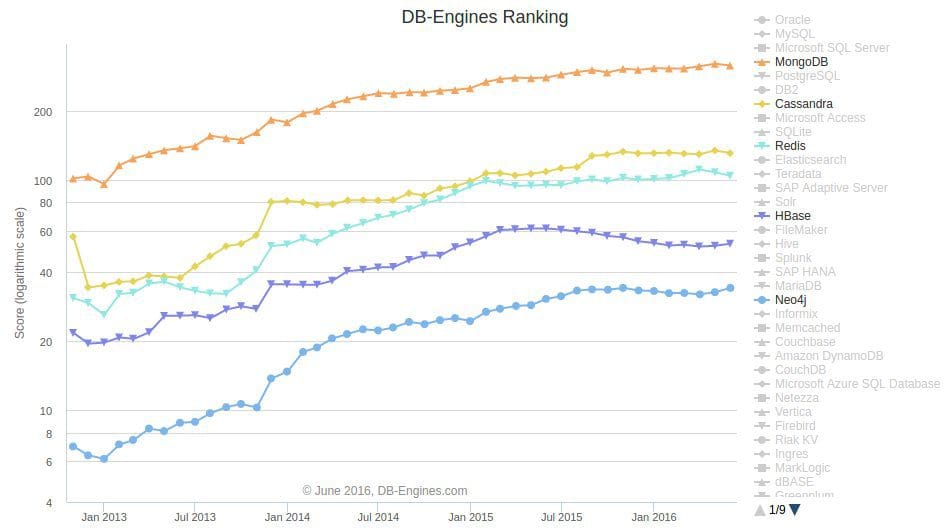
Here is a trend of database engine rankings over time, as per db-engines.com, with our top frameworks highlighted (click to enlarge):
The Google trends results of the same NoSQL engine search terms are shown below:
What follows is a brief overview of the top NoSQL database engines as per the above methodology.
1. MongoDB
MongoDB is a document store, and the current top NoSQL database engine in use today. As is the requirement for NoSQL engines, MongoDB does not use a relational schema, instead using JSON-like "documents" to store data. The document is akin to a record, housing fields and values. MongoDB supports dynamic schemas, and is free and open source software.

MongoDB also provides these features that you would expect: load balancing, replication, indexing, querying, and can act as a file system (with load balancing and fault tolerance). For those interested in a more detailed treatment of a particular point, check out this discussion of JSON and BSON (Binary JSON) objects, directly from MongoDB.
2. Cassandra
Originally developed at Facebook, Cassandra is a decentralized, distributed, column-oriented database engine. It is optimized for clusters, especially those across multiple datacenters, and thanks to its asynchronous updating and master-less design, Cassandra provides low latency client access. Like MongoDB, it is also free and open source.

Cassandra is a column-oriented database, meaning that its rows actually contain what we most usually think of as vertical data, or what is traditionally held in relational columns (Rows contains columns? Huh?). The advantage of column-oriented database design is that some types of data lookups can become very fast, given that the desired data could be stored consecutively in a single row (compare this with having to search and read from multiple, nonconsecutive rows to attain the same field value in row-oriented database). This particularity, along with the optimized, decentralized distributed model has solidified Cassandra's popularity over the years.
See a more thorough discussion of column-oriented design here.
3. Redis
Redis is the most popular and widely-used key-value store implementation on our list. What is a key-value store? Key-value stores are simple paradigms at a high-level: assign values to keys to facilitate the access and storage of these values, which are always found via their keys. Think hash maps and you've got the idea (dictionaries in Python).
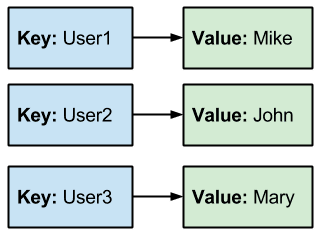
Redis holds its key-value pairings in memory, making their access quick. If data durability can be sacrificed (mainly with non-critical data, or in read-only or -primarily situations), being able to forego data writes means that this memory-only data boasts incredibly fast performance. Over the years, APIs have been developed for an incredibly wide variety of languages as well, making Redis an easy choice for developers.
For a comparison of Redis with other engines in this post, have a look at this Quora post.
4. HBase
Another column-oriented database, HBase is a free and open source implementation of Google's BigTable. While HBase is a legitimate piece of software in its own right, some of its popularity and widespread use undoubtedly comes from its close association with Hadoop, as it is part of the Apache project. It facilitates the efficient lookup of sparse, distributed data, which is one of its strongest selling points.

HBase has a number of high profile implementations in the wild, including those at LinkedIn, Facebook, and Spotify. Numerous related Apache projects also support HBase, notably providing an SQL layer for data access (Phoenix), which would certainly bode well for relational database admins looking to implement a NoSQL solution. And with the high numbers of Hadoop installations in existence, and growing, HBase will be a default NoSQL storage solution for many for years to come.
For a look at HBase's architecture, have a look at .
5. Neo4j
Neo4j is the lone graph database management system on our list, the most popular such system i use today. The graph database is premised on edges acting as relationships, directly relating data instances to one another. Like others on the list, Neo4j has an open source implementation as well.
Built in Java, Neo4j data can be accessed and updated via the Cypher Query Language, a graph-specific SQL-like language, an example of which is shown below:

Graph databases (and Neo4j, of course) have advantages in some use cases, including potentially in certain data mining and pattern recognition scenarios, given that associations between data instances are explicitly stated. For a further discussion on the merits of graph databases in general, see this Quora post, or this post from Neo4j.
Related: