Stop (and Start) Hiring Data Scientists
Large companies are losing many data scientists to smaller companies, so what should executives and managers do? These three “stop & start” tactics can improve talent retention, and help define a new way of recruiting and working for the Data Science field.
By Ian Xiao, Data | ML | Marketing.

Disclaimer: All opinions are my own; they do not reflect my employer’s. All data used in this article come from Kaggle Data Science Survey. All observations are from my experience working in data science teams in big and small companies.
What is happening?
Large companies are losing about 20% of their data scientists; many of them probably went to startups, while some might have left the sector. Comparing to an average turnover rate of 13% in technology, which is the industry that has the highest attrition, it’s clear that the data science teams at big companies are facing a serious retention problem.
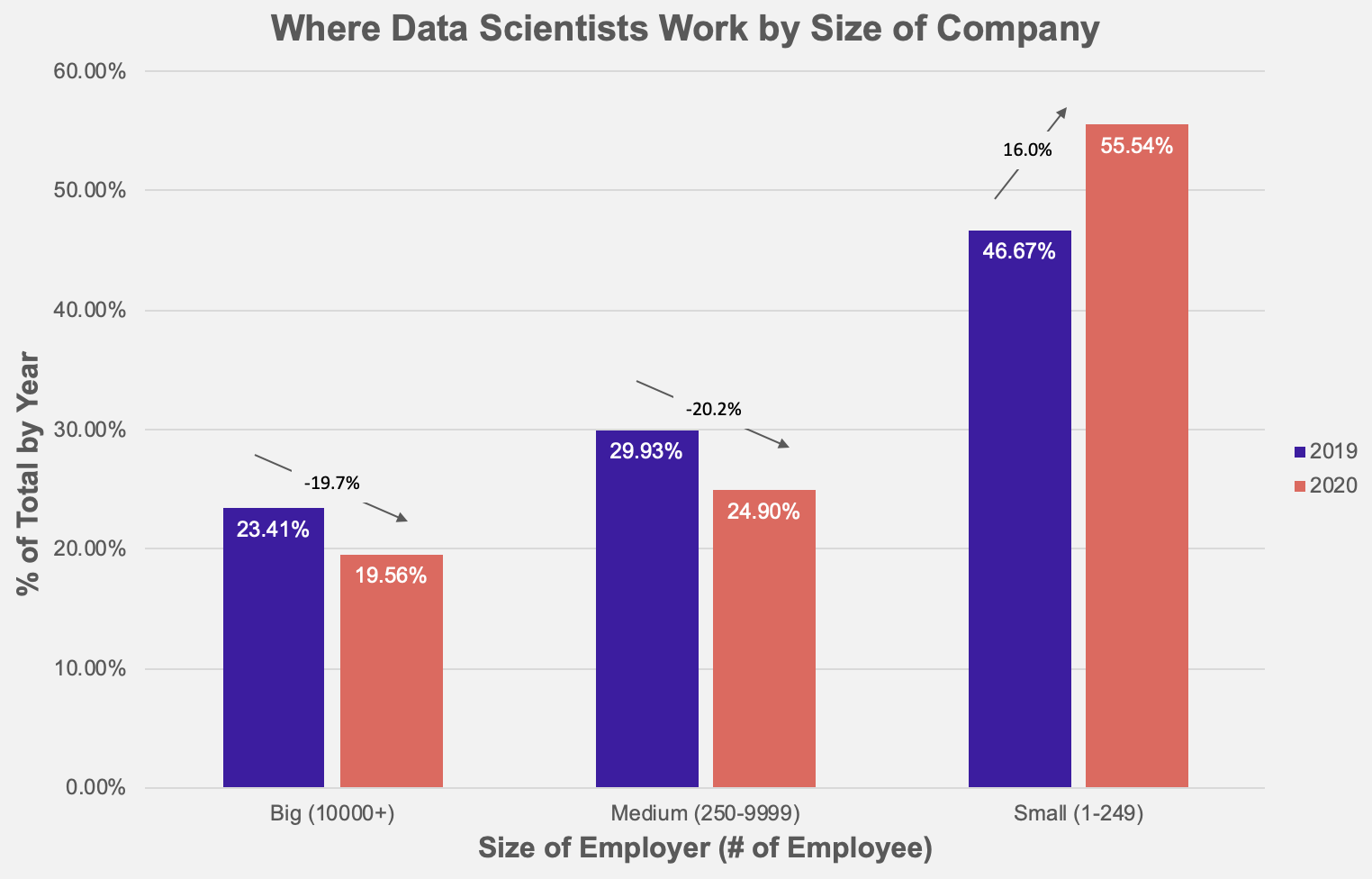
Data from Kaggle Survey, extracted on May 8th, 2021; n=4033 in 2020, n=3502 in 2019, across major countries. Only included respondents who identified as “Data Scientist” or “Machine Learning Engineer.”
Why do Data Scientists quit?
Data scientists quit mostly because there is a gap in expectation vs. reality.
Most data scientists expect to spend most of the time on work directly related to modelling and insight discovery while data engineers prepare clean datasets and build the pipelines. However, they spend almost 50% of the time on “tedious” data collection and cleaning — just as much as data engineers do.
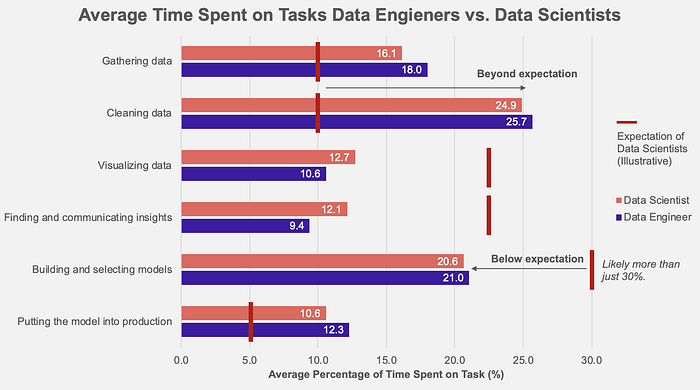
Data from Kaggle Survey, extracted on May 8th, 2021; n=584 in 2018, across major countries. Only included respondents who identified as “Data Engineer” or “Data Scientist.” Expected time spent based on the author’s observation and the rough estimated time of modelling related content from data science courses on Udacity, Coursera, Udemy, and YouTube.
Most data scientists want to work on sophisticated problems with cutting-edge solutions. Data scientists at smaller companies are 46% more likely to use only advanced algorithms on a regular basis than their peers in larger companies.

Data from Kaggle Survey, extracted on May 8th, 2021; n=3502 in 2019, across major countries. Only included respondents who identified as “Data Scientist” or “Machine Learning Engineer.” Traditional algorithms include Linear and Logistic Regression and Random Forest. Advanced algorithms include the Gradient Boosting method, Bayesian method, CNN / RNN, and Transformer Network.
What should we do?
We need to embrace turnover because it is normal. But having a turnover that’s 55% higher than the industry with the highest attrition means we need to do something now.
For hiring managers and executives at large companies, let’s cultivate a new and sustainable way of recruiting and working. Adding ping pong tables helps, but it won’t solve the problem.
- Stop hiring data scientists who only care about cool sh*t. Start hiring data scientists who take pride in building and shipping stuff with others.
We should reset the expectation and the role of data scientists using the recruiting process — start from campus events and career webinars to actual interviews. Have teams from Business, Product Management, Data Engineering, and Software Development be part of the interviews. This will trigger a ripple effect and help aspiring data scientists develop the right expectations and skill profiles. - Stop focusing on “science.” Start celebrating “data + science + engineering” together.
Since the early days of Kaggle, a popular data science competition platform that rightfully brought Data Science to the mainstream career path, we’ve been overly spotlighting the algorithmic work and success of data science individuals. In fact, to achieve results in the real world, it’s a team effort that involves lots of hard (and smart) work from data engineers and software developers. They build the backbones of applications that host the model data scientists developed. The sad reality is that many users don’t see or understand the backend; therefore, they under-appreciate the work of the unsung heroes. Data, science, and engineering (and business strategy, UX design, and product management) must come together — and share the spotlights. - Stop running data science teams in silos. Start creating data product pods.
Many large companies hire people to dedicated data science teams; this builds walls and reinforces false expectations. We should adopt the proven successful model of product development teams — they organize by core product category or features. In this case, we should organize and hire people into Data Product Pods. Each pod is a dedicated or temporary team that consists of people who know data and have all the skills to design and ship viable products collectively. Essential roles include Product Managers, Data Engineers, Data Scientists, and Full-stack Developers. Most importantly, success is attributed to the quality of the product and the contribution of the whole pod — not a particular role or individual.
Original. Reposted with permission.
Related: