Save Sarah Connor with Data Science
Data science and data privacy are deeply interwoven, and must be carefully considered by practitioners. In comparing the Safe Harbour and Expert Determination data obfuscation approaches, Safe Harbour has been very popular among data engineers but has fundamental limitations, where Expert Determination offers important advantages.
By Peter Kozlov, Master of Data Analytics, with over 30 years of experience in different industries.
What is going on in the picture below?
Do we see a data thief here?

Picture 1. Shots from The Terminator film released in 1984.
It is California 1984. We probably can recognise the future governor of California, Arnold Schwarzenegger, in the role of Terminator, who is directly targeting Californians. He is using a phone book he found in a phone booth for it.
Was the Terminator a data thief? Actually, he wasn’t because such personal data was publicly available in 1984.
Perception of personal information treatment was changed significantly in recent years, and there are some indications:
- (EU) General Data Protection Regulation (GDPR) was enforced on May 25, 2018.
- (AU) Consumer Data Rights (CDR) in power from September 1, 2019.
- (US) The Health Insurance Portability and Accountability Act (HIPAA) changes are expected in 2021.
Today, Californians take data privacy very seriously, according to California Consumer Privacy Act (CCPA, signed into law on October 11, 2019). Californians were ahead of others to attach a price tag to each non-compliant customer record. The price tag is in the range of $100-750 per record.
What are the best practices in data privacy? The US regulator HIPAA was always a raw model for the health industry as well as other industries. It disseminates knowledge and sharpens definitions for privacy data treatment methods. HIPAA differentiates Safe Harbour and Expert Determination methods. We will compare these data obfuscation approaches.
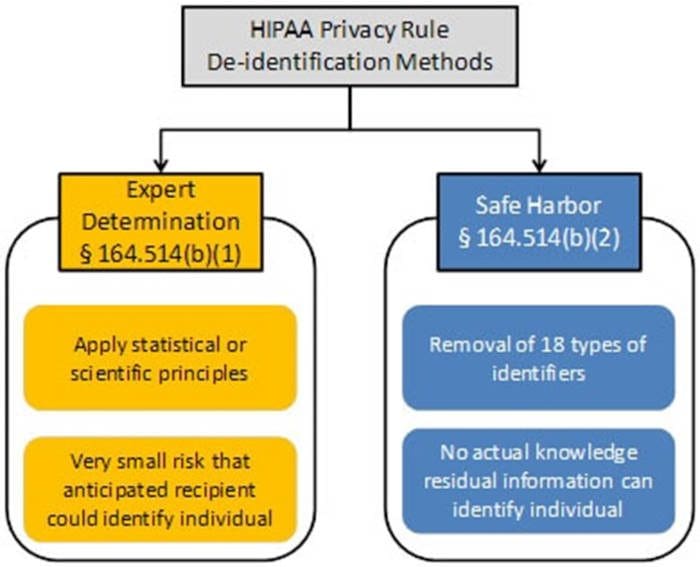
Picture 2. HIPAA recommended de-identification methods. Illustration from the U.S. Department of Health & Human Services.
Expert Determination is provided by a qualified statistician/data scientist as an objective risk assessment. In contrast, Safe Harbor is a recipe for businesses to do this themselves.
“Safe Harbour” is a very catchy idea because it is based on a simple set of rules to remove well-defined identifiers. For example, the first two identifiers are a person’s name and geographic subdivision smaller than a state. The full identifiers list can be found here. Apart from removing keys, we also need to ensure that there is no information left to identify individuals. This could be a challenge due to micro keys such as a very rare disease or unique treatment parameters. Safe Harbour is rule-based and is thus too inflexible to consider the actual content of the data and micro keys. The article A Re-identification of Patients in Maine and Vermont Statewide Hospital Data in the Technology Science journal demonstrated that 3.2% of Safe Harbor data had been re-identified to individuals using local publications.
The Expert Determination approach can take into consideration the purpose of data research and tolerate various obfuscation methods in a research context:
- Scrambling
- Encryption
- Directory replacement
- Masking
- Tokenization
- Data blurring
- Noise addition
- Aggregation
Expert Determination allows us to balance engendered information loss with the probability of personal information disclosure and make sure that the meaning of the information processing is preserved.
Let’s discuss an example.
Our task is to perform customer research and reduce data risks. We want to compare urban vs. rural customers with Safe Harbour and Expert Determination. We will use a data example of two records and four fields. We assume that the order collected for the research records is random in the internal data set, and the collected “valuable customer data” is not shared with the public on a row-by-row basis. We also assume that the following data set is available in a clinic which is an external data source for this exercise:

Table 1. Data example of an external data source.
Our Safe Harbour obfuscation requires us to remove Names, dates, and months from the date of birth (DOB) and replace the location with just the state in our internal data:

Table 2. Safe Harbour data obfuscation for the data example.
We have two concerns in the case of a data leak:
- leaked data gets joined with an external source to exploit the DOB.
- the DOB can be guessed from our internal data set.
P(DOB disclousure|Ext|Int) is the probability of DOB disclosure when internal and external data gets leaked. There is a fifty-fifty chance that we can match “1963, California” to the external source DOB because we have two records with an identical Year of Birth (YOB) and Location in our internal data set.
P(DOB disclousure|Int) is the probability of DOB disclosure when an attacker tries to recover the DOB from our internal data set. 1963 has 365 days, and there is no other information in the internal data set to guess the day in such a large date range.
Expert Determination is applied in two steps. First, we try to preserve a maximum of information, and second, we review such “data hoarding” by adjusting preserved data to the research purpose.

Table 3. The first attempt of Expert Determination data obfuscation for the data example.
P(DOB disclousure|Ext|Int) is the same as in the data set by Safe Harbor.
P(DOB disclousure|Int) is 1 chance from 30 that is higher than in the previous case. According to our arbitrary decision, this P value could be accepted as low or moderate risk.
We have managed to preserve names, location, and DOB to the month level for the first Expert Determination obfuscation attempt. What is come to the question is if the obfuscation results are aligned with the research purpose. More careful alignment with the urban vs. rural customer research can exclude names and just tag customer age groups as adults and children.

Table 4. The second attempt of Expert Determination data obfuscation for the data example.
There is no change for the P(DOB disclousure|Ext|Int) value.
P(DOB disclousure|Int) is estimated based on the maximum adult age of 100 (you can also use a more conservative number such as average life expectancy). Another two parameters are the minimum adult age of 18 and the average number of days in a year of 365.25. P(DOB disclousure|Int) is significantly lower for the second Expert Determination obfuscation than for Safe Harbor implementation.
The final comparison of these two HIPAA obfuscation methods for the data example:

Table 5. Compare HIPAA methods for the data example and the research purpose.
The selected data example and research purpose aim to demonstrate the flexibility of Expert Determination over Safe Harbour. The main advantage of Expert Determination is that this method not only deals with the probability of disclosure but simultaneously allows us to control correspondent engendered information loss. The data sample obfuscated with the Expert Determination data example allows us to carry out the urban vs. rural research, and with Safe Harbour, it does not.
Perhaps this example will serve to demonstrate that the simplest solution to a problem is not always appropriate and can save Sarah Connor from being found by the Terminator by applying the best rather than the quickest solution.
Related: