12 Most Challenging Data Science Interview Questions
The simple but tricky data science questions that most people struggle to answer.

Image by Author | Canva Pro
If you ask me, the hiring managers are not looking for the correct answers. They want to evaluate your work experience, technical knowledge, and logical thinking. Furthermore, they are looking for data scientists who understand both the business and technical sides.
For example, during an interview with a top telecommunication company, I was asked to come up with a new data science product. I suggested an open-source solution and let the community contribute to the project. I explained my thought process and how we can monetize the product by providing premium service to paid customers.
I have collected the 12 most challenging data science interview questions with answers. They are divided into three parts: situational, data analysis, and machine learning to cover all the bases.
You can also check out the complete collection of data science interviews: part 1 and part 2. The collection consists of hundreds of questions on all sub categories of data science.
Situational Interview Questions
1) What is the most challenging data science project that you worked on?
You don’t have to overthink. The hiring manager wants to assess your experience in dealing with complex projects.
Start with the project name and a short description. Then, explain why it was challenging and how you overcame it. It is all about details, tools, methodologies, terminology, out-of-box thinking, and dedication.
It is a good habit to review your last five projects before appearing for an interview. It will prepare you for the talking points, business use case, tools, and data science methodologies.
2) If we give you a random dataset, how will you figure out whether it suits the business needs or not?
It is not a complete question and it can put off the interviewee. You need to ask for a business use case and additional information about the baseline metric. After that, you can start with analyzing data and business use cases. You will be explaining statistical algorithms to analyze data reliability and quality. After that, match it with the business use case and how it can improve existing systems.
Remember, this question is all about assessing your critical thinking and your preparedness for handling random datasets. Explain your thought process and come up with a conclusion.
3) How will you generate revenue using your machine learning skills?
This one is a tricky question, and you should be prepared for the numbers and how machine learning has generated revenue for multiple companies.
If you are not aware of numbers, then don’t worry. There are multiple ways to tackle this question. Machine learning is used in forecasting stock prices, diagnosing diseases, multi-language customer service, and recommended systems in e-commerce.
You need to tell them your expertise in a specific area and match it with the company's mission. If they are fintech, you can propose fraud detection, forecasting growth, threat detection, and policy recommendation systems.
Data Analysis
4) Why do we use A/B Testing?
A/B testing is statistical hypothesis testing for randomized experiments with two variables, A and B. It is mostly used for user experience research where two different versions of a product are analyzed based on user response.
In data science, it is used for testing various machine learning models in the production and analysis of data-driven solutions within a company.

Image from Optimizely
5) Write an SQL query that lists all orders with customer information.
The interviewers will provide you with extra information about database tables such as the Customers table has ID and Name data field, and the Orders table has ID, CUSTOMER, and VALUE.
We will join two tables on ID and CUSTOMER columns and display ID, Name as Customer Name, and VALUE.
SELECT a.ID, a.Name as Customer Name, b.VALUE FROM Customers as a LEFT JOIN Orders as b ON a.ID = b.CUSTOMER
The above example is quite simple. You must be prepared for a complex SQL query to clear the interview round. Check out Nate’s recent blog on 24 SQL Questions You Might See on Your Next Interview.
6) What are Markov chains?
Markov Chains is a transition from one state to another using probabilistic methodology. It defines the probability of transitioning to a future state based on the current state and time elapsed. Markov Chain is used in information theory, search engines, and speech recognition. Learn more by reading Brilliant Math’s wiki page.
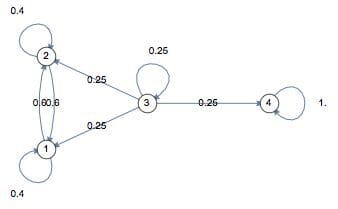
Image from Brilliant Math & Science Wiki
7) How can outlier values be treated?
The simple solution is to drop outliers as they affect the overall data analysis. But before you do that, make sure your dataset is large, and the values you are removing are garbage. The garbage means that it was added by mistake.
Apart from that, you can:
- Normalize the data
- Apply MinMaxScaler or StandardScaler
- Use algorithms that are not affected by outliers, such as random forests
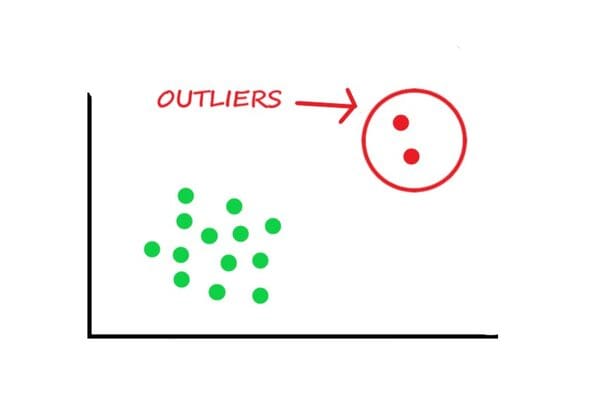
Image from dataanalyticsedge
Machine Learning
8) What is TF-IDF?
TF-IDF (Term Frequency Inverse Document Frequency of records) is used to calculate the relevance of a word in a series or corpus of a text. During the text indexing process, it assesses the value of each term in a document or corpus. It is commonly used for text vectorization, where a line or sentence is converted to numerical values and used for NLP (Natural Language Processing) tasks.
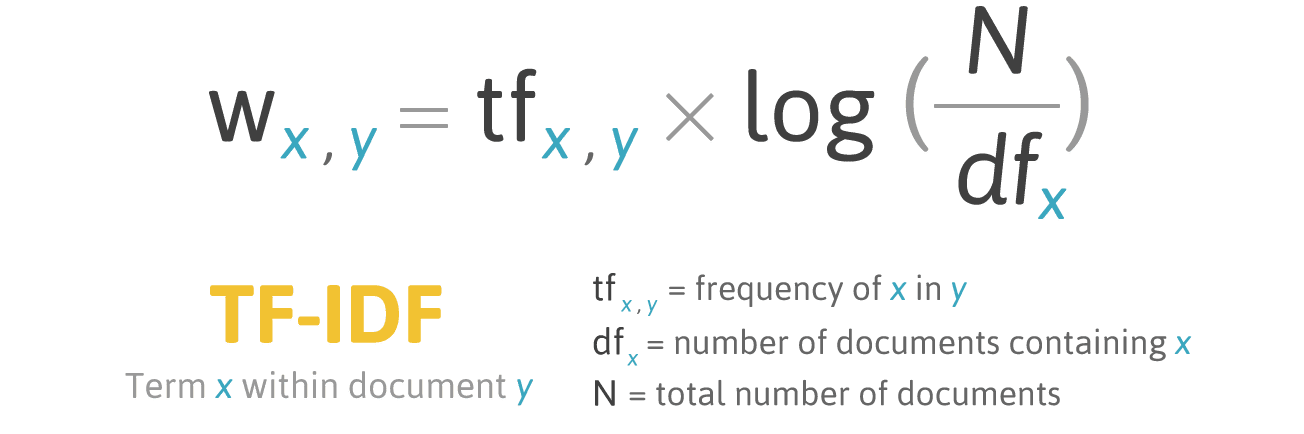
Image by filotechnologia.blogspot
9) What is the difference between error and residual?
Error is the difference between the observed value and its theoretical value. Often it is the unobserved value generated by the DGP (Data Generating Process)
Residual is the difference between the observed value and the predicted value generated from a model.
10) Do gradient descent methods always converge to similar points?
Not always. It is quite easy for it to get stuck at local minima or optima points. If you have multiple local optima, its convergence depends on the data and initial conditions. It is hard to reach global minima.
11) What is the Sliding Window method for Time Series Forecasting?
The sliding window method is also called the lag method, where previous time steps are used as inputs, and the next time step is used as an output. The previous steps depend on the window width, which is the number of previous steps. The sliding window method is quite famous for univariate forecasting. It converts a time series dataset into a supervised learning problem.
For example, if the sequence is [45,96,105,108,130,140,160,190,220,250,300,400] and the window width is three. The output will look like:
| X | y |
| 45,96,105 | 108 |
| 96,105,108 | 130 |
| 105,108,130 | 140 |
| 108,130,140 | 160 |
| … | … |
12) How can you avoid overfitting your model?
Overfitting occurs when your model performs well on the train and validation dataset but fails at the unseen test dataset.
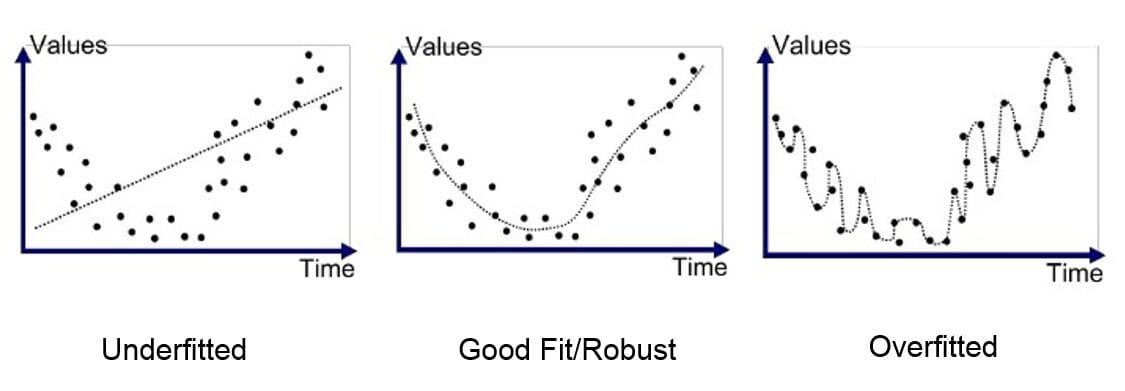
Image by Ilyes Talbi
We can avoid it by:
- Keeping model simple
- Avoid training for longer Epocs
- Feature engineering
- Using cross-validation techniques
- Use regularization techniques
- Model evaluation using Shap
Reference
- Top 80 Data Science Interview Questions and Answers 2022 | Simplilearn
- 87 Commonly Asked Data Science Interview Questions (springboard.com)
- Top 30 NLP Interview Questions & Answers 2022 - Intellipaat
- 9 Data Science Interview Questions and Answers for 2022 | Indeed.com
- 23 Time Series Interview Questions (ANSWERED) ML Devs Must Know | MLStack.Cafe
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.