A community developing a Hugging Face for customer data modeling
A year ago, Objectiv started a community of 50 companies to develop a Hugging Face like open-source project for customer data modeling. They key objective: enable building data models on one team/company’s dataset, and then run them seamlessly on another.
Objectiv is a community-driven open-source project that aims to do for customer data modeling what Hugging Face did for NLP: https://github.com/objectiv/objectiv-analytics
Customer data modeling is reinvented from scratch by every team
Starting with product analytics, every company/team uses their own custom tracking plans to define events and data structures. As a result, everyone is going through the same learning curve to clean & prep data, and to build analytics models & machine learning from scratch. The same applies to other key customer data inputs like CRM, payments, marketing, etc.
Democratizing customer data modeling
About a year ago, we started a community of 50 companies to develop a Hugging Face like open-source project for customer data modeling. They key objective: enable building data models on one team/company’s dataset, and then run them seamlessly on another.
Step 1: generalize input data for product analytics
The first step we took is to define an open analytics taxonomy: a detailed specification of product analytics events to track, and how to structure this data. We defined & tested it with the use cases of our initial community of 50 companies, to make sure it fit their digital products & data modeling goals.
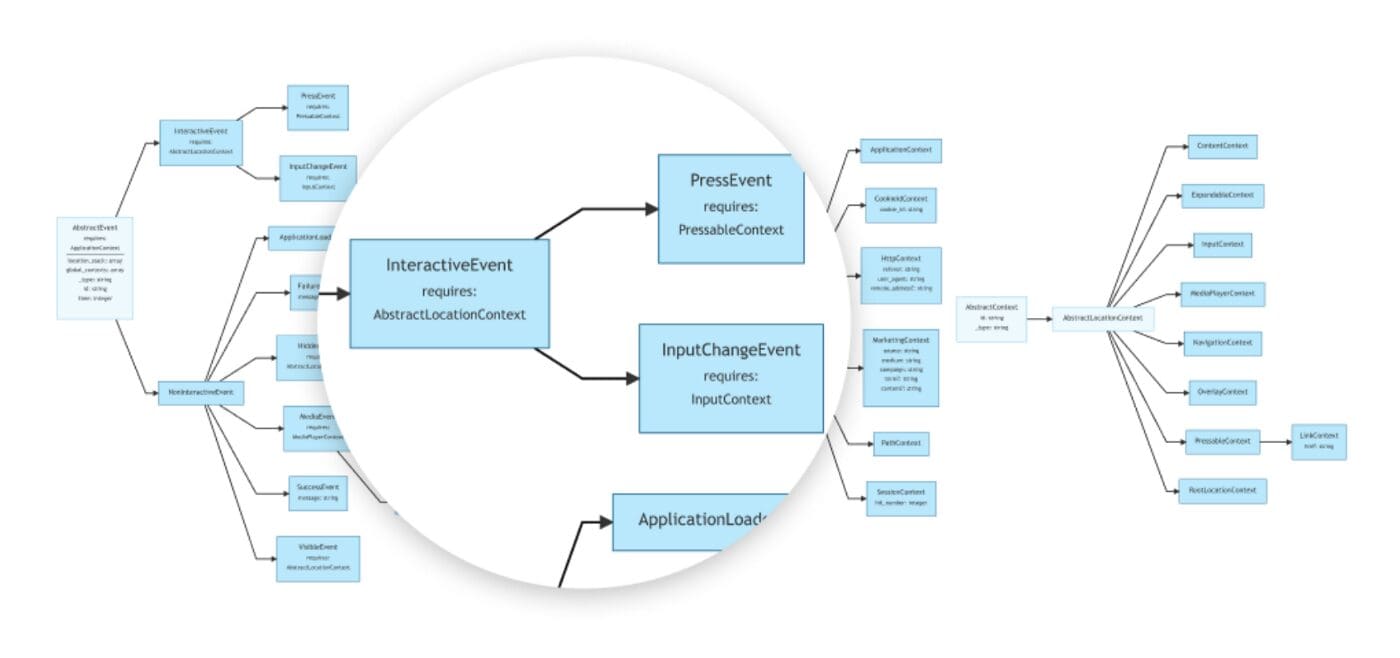
Step 2: provide tooling to capture validated, clean data
Because the taxonomy standardizes input data, we were able to develop helpful tooling to support engineers implementing the tracking instrumentation. For example, SDKs with validation at IDE, runtime and CI.
Step 3: create a place to take models & run them seamlessly on your data
The initial community grew to 300+ data team members and with their input, we created the open model hub: an open-source collection of models, ranging from typical product analytics use-cases, to predicting user behavior with machine learning. These models run straight on any dataset that follows the open analytics taxonomy. They’re powered by a pandas-compatible python library that runs in any major notebook. All models currently work on both PostgreSQL and Google BigQuery, with Amazon Athena next, and more data stores coming.
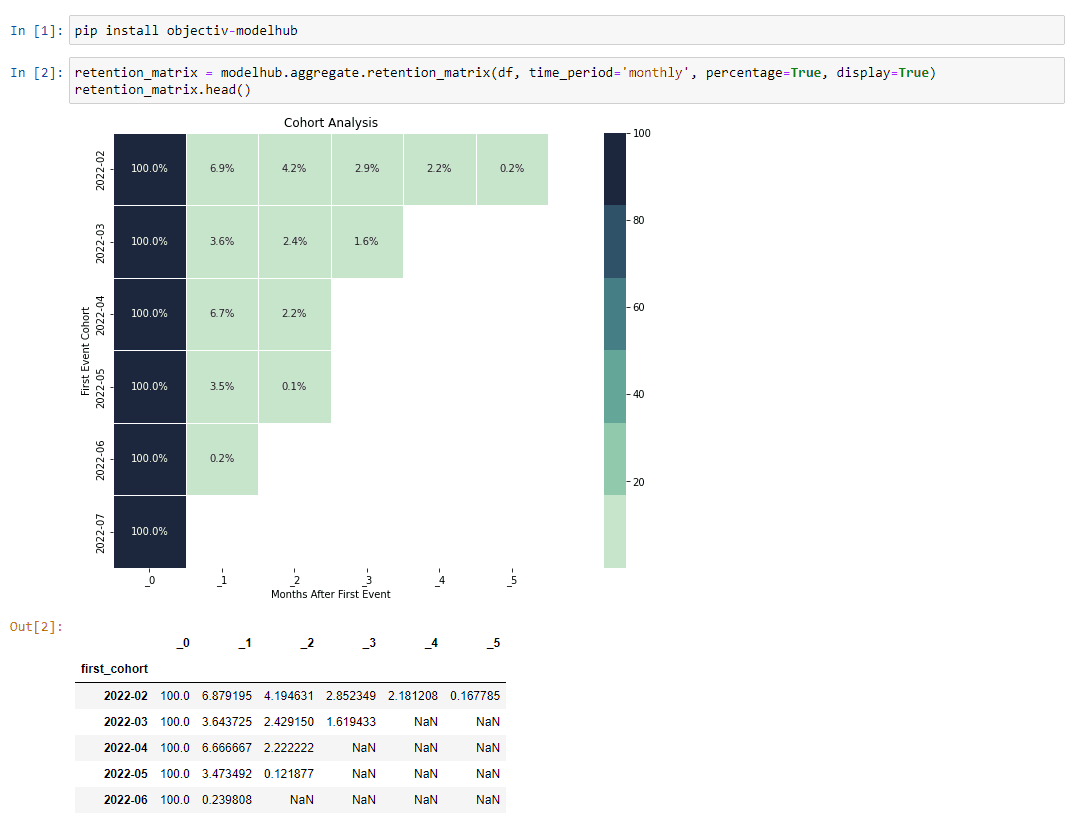
Next: more sources of input data
After covering product analytics as input, the open analytics taxonomy and open model hub are both now being extended to cover marketing, CRM, payments data and more.
Getting involved
If you like to test the project and contribute, check out the repo on https://github.com/objectiv/objectiv-analytics