How to Anonymise Places in Python
A ready-to-run code which identifies and anonymises places, based on the GeoNames database.

Photo by Max Chen on Unsplash
In this article, I illustrate how to identify and anonymise places in Python, without the usage of NLP techniques, such as Named Entity Recognition.
Places identification is based on a gazetteer, which is built from the Geonames Database.
Geonames is a Web service, containing (almost) all the places in the world. The Geonames database can be downloaded for free at this link. You can download the full database, covering all the world countries, or only one specific country.
The idea behind this article is to build a gazetteer from the Geonames Database and exploit it to recognise places in a sentence. In practice, the implemented algorithm searches whether every word in the sentence is contained in the gazetteer or not. In order to search also for places longer than one word, ngrams are considered.
The article is organised as follows:
- import the Geonames Database
- identify places in a sentence
- anonymise places in a sentence
- extend the anonymise function
Import the Geonames Database
The first step involves importing the Geonames Database, which can be downloaded from this link. You can choose whether to import the full database (AllCountries.zip) or a specific country (e.g. IT.zip for Italy). Every country is identified by its identification code.
The full database is more complete, but it requires more processing time than a single-country database.
Thus, you should choose the right database, according to the text to be processed. In this tutorial, I focus on the Italian database, but the same code can be also exploited by other databases.
From the Geonames link, I download the IT.zip file, I decompress it and I put in my working directory:
Image by Author
Then I import it into a Pandas dataframe:
import pandas as pd
df = pd.read_csv('source/IT.txt', sep=' ', header=None)
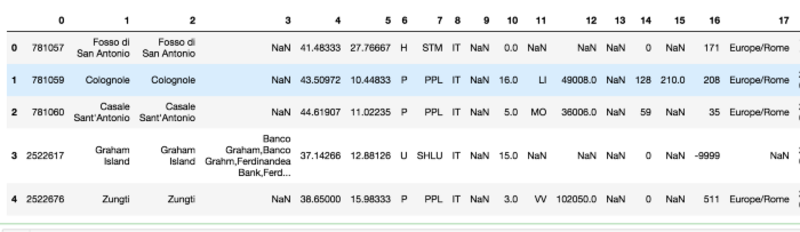
Image by Author
The column 1 of the dataframe contains the list of places, which is used to build the gazetteer:
gaz = df[1]
gaz = gaz.tolist()
The implemented gazetteer contains 119.539 places.
Identify Places in a Sentence
Now I define a function which receives as input a text and then returns all the places contained in the text. The function performs the following operations:
- remove all punctuation from the text
- split the sentence in tokens, separated by the space character. This can be done through the
split()function - starting from the identified tokens, build all the possible ngrams, with n ? 5. I exploit the
ngramsfunction of thenltklibrary to split the text into ngrams. For example in the sentence: Oggi sono andata a Parigi, the ngrams with n ? 5 include:
(‘Oggi’, ‘sono’, ‘andata’, ‘a’, ‘Parigi’)
(‘Oggi’, ‘sono’, ‘andata’, ‘a’)
(‘sono’, ‘andata’, ‘a’, ‘Parigi’)
(‘Oggi’, ‘sono’, ‘andata’)
(‘sono’, ‘andata’, ‘a’)
(‘andata’, ‘a’, ‘Parigi’)
(‘Oggi’, ‘sono’)
(‘sono’, ‘andata’)
(‘andata’, ‘a’)
(‘a’, ‘Parigi’)
(‘Oggi’,)
(‘sono’,)
(‘andata’,)
(‘a’,)
(‘Parigi’,)
- starting from the biggest ngrams (n = 5), search if each ngram is contained in the gazetteer. If so, a place is found and can be added to the list of found places and remove the place from the original text, otherwise, continue. Note
The full code of the function is the following one:
from nltk import ngrams
import re
def get_places(txt):
# remove punctuation
txt = re.sub(r"[^\w\d'\s]+",'',txt)
n = 5
places = []
for i in range(n,0,-1):
tokens = ngrams(txt.split(), i)
for t in tokens:
token = " ".join(t)
try:
res = gaz.index(token)
except ValueError:
continue
if res:
places.append(token)
txt = txt.replace(token,"")
return places
Now I can test the function with an example:
txt = 'Oggi sono andata a Roma e a Milano.'
get_places(txt)
which gives the following output:
['Roma', 'Milano']
Anonymise Places in a Sentence
Now, I’m ready to exploit the previous defined function to anonymise function. Simply, I can replace the found places with a symbolic character, such as X. All the searching operations must be done on a copy of the original text, in order to preserve the original text (i.e. punctuation is remove for manipulation).
Here the complete function for anonymisation:
def anonymise_places(txt):
temp_txt = re.sub(r"[^\w\d'\s]+",'',txt)
n = 5
# remove punctuation
for i in range(n,0,-1):
tokens = ngrams(temp_txt.split(), i)
for t in tokens:
token = " ".join(t)
try:
res = gaz.index(token)
except ValueError:
continue
if res:
txt = txt.replace(token,"X")
temp_txt = temp_txt.replace(token,"")
return txt
Extend the Anonymise Function
The implemented function can be extended with a gazetteer covering all the world. However, the GeoNames database for all the world is about 1.5 GB thus resulting difficult to manage. For this reason, you can download it, load in Pandas and then select only the interesting column (which corresponds to column 1) and export the result as a new csv file, which is about 274 MB:
df_all = pd.read_csv('source/allCountries.txt', sep=' ', header=None)
df_all[1].to_csv('source/places.csv')
The previous operation may require a while, since the file is quite huge. Then, you can exploit this new file as a gazetteer, instead of IT.txt.
Summary
In this article, I have described how to anonymise places in Python without the usage of NLP techniques. The proposed methodology is based on the usage of a gazetteer, which is built from the Geonames Database.
The full code of this tutorial can be downloaded from my Github Repository. The tutorial also contains a function test in gradio, a very powerful Python library for Web Apps. Stay tuned for a tutorial on gradio :)
Angelica Lo Duca (Medium) (@alod83)works as a researcher at the Institute of Informatics and Telematics of the National Research Council (IIT-CNR) in Pisa, Italy. She is a professor of "Data Journalism" for the Master degree course in Digital Humanities at the University of Pisa. Her research interests include Data Science, Data Analysis, Text Analysis, Open Data, Web Applications, and Data Journalism, applied to society, tourism, and cultural heritage. She used to work on Data Security, Semantic Web, and Linked Data. Angelica is also an enthusiastic tech writer.
Original. Reposted with permission.