Spark SQL for Real-Time Analytics
Apache Spark is the hottest topic in Big Data. This tutorial discusses why Spark SQL is becoming the preferred method for Real Time Analytics and for next frontier, IoT (Internet of Things).
By Sumit Pal and Ajit Jaokar, (FutureText).
This article is part of the forthcoming Data Science for Internet of Things Practitioner course in London. If you want to be a Data Scientist for the Internet of Things, this intensive course is ideal for you. We cover complex areas like Sensor fusion, Time Series, Deep Learning and others. We work with Apache Spark, R language and leading IoT platforms. Please contact info@futuretext.com for more details
Overview
This is the 1st part of a series of 3 part article which discusses SQL with Spark for Real Time Analytics for IOT. Part One discusses the technological foundations of SQL with Spark. Part two discusses Real Time Analytics with Spark SQL. Finally, Part Three discusses an IoT use case for Real Time Analytics with Spark SQL.
Introduction
In Part One, we discuss Spark SQL and why it is the preferred method for Real Time Analytics. Spark SQL is a module in Apache Spark that integrates relational processing with Spark’s functional programming API. Spark SQL has been part of Spark Core since version 1.0. It runs HiveQL/SQL alongside or replacing existing hive deployments. It can connect to existing BI Tools. It has bindings in Python, Scala and Java. It makes two vital additions to the framework. Firstly, it offers a tight integration between relational and procedural processing, with declarative DataFrame API that integrates with procedural Spark API. Secondly, it includes an extensible optimizer, built with Scala, leveraging its strong pattern matching capabilities, which makes it easy to add compos-able rules, control code generation and define extensions.
Objectives and Goals of Spark SQL
While the relational approach has been applied to solving big data problems, it is in-sufficient for many big data applications. Relational and procedural approaches have until recently remained disjoint, forcing developers to choose one paradigm or other. The Spark SQL framework combines both models.
As they say, “The fastest way to read data is NOT to read it” at all.
Spark SQL supports relational processing both within Spark programs (viaRDDs) and on external data sources. It can easily support new data sources, including semi-structured data and external databases amenable to query federation.
Spark SQL helps this philosophy by
- Converting data to more efficient formats (from storage, network and IO perspective) by using various columnar formats
- Using data partitioning
- Skipping data reads using Data statistics
- Pushing predicates to Storage System
- Optimization as late as possible when all the information about data pipelines is available
Internally, Spark SQL and DataFrame take advantage of the Catalyst query optimizer to intelligently plan the execution of queries.
Spark SQL
Spark SQL can support Batch or Streaming SQL. With RDDs the core Spark Framework supports batch workloads. RDDs can point to static data sets and Sparks’s rich API can be used to manipulate the RDDs working on batch data sets in memory with lazy evaluation.
Streaming + SQL and DataFrames
Let us quickly look into what is an RDD in spark core framework and what is a DStream which are the basic building blocks for further discussions in the article
Spark operates on RDDs – resilient distributed dataset – which is an in-memory data structure. Each RDD represents a chunk of the data which is partitioned across the data nodes in the cluster. RDDs are immutable and a new one is created when transformations are applied. RDDs are operated in parallel using transformations/actions like mapping, filtering. These operations are performed simultaneously on all the partitions in parallel. RDDs are resilient, if a partition is lost due to a node crash, it can be reconstructed from the original sources.
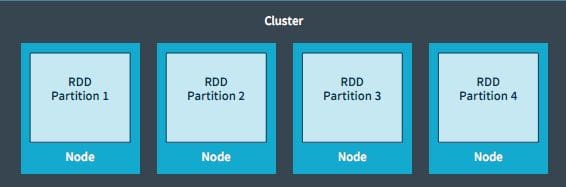
Spark Streaming provides as abstraction called DStream (discrete streams) which is a continuous stream of data. DStreams are created from input data stream or from sources such as Kafka, Flume or by applying operations on other DStreams. A DStream is essentially a sequence of RDDs.
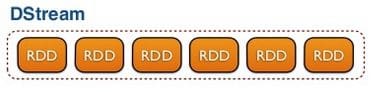
RDDs generated by DStreams can be converted to DataFrames and queried using SQL. The stream can be exposed to any external application that talks SQL using Spark’s JDBC driver. Batches of streaming data are stored in the Spark’s worker memory and this can be interactively queried on demand using SQL or Spark’s API.
StreamSQL is a Spark component that combines Catalyst and Spark Streaming to perform SQL queries on DStreams. StreamSQL extends SQL to support streams with operations like:
- SELECT against a stream to calculate functions or filter unwanted data (using a WHERE clause)
- JOIN a stream with 1 or more data sets to produce a new stream.
- Windowing and Aggregation – Stream can be limited to create finite data sets. Windowing allows complex message selection based on field values. Once a finite batch is created analytics can be applied.
Spark SQL has the following components
Components
Spark SQL Core
- Execution of queries as RDDs
- Reading data sets in multiple file formats Parquet, JSON, Avro etc.
- Reading data sources both SQL and NOSQL Data sources
Hive Support
- HQL, MetaStore, SerDes, UDFs
Catalyst Optimizer
- it optimizes the Relational algebra + expressions
- it does Query optimization
Problems Spark SQL solves
Spark SQL provides a unified framework with no movement of data outside the cluster. No extra modules need to be installed or integrated. It provides a unified load/save interface irrespective of the data source and the programming language.
The example below shows how easy it is to both load data from avro and convert it into parquet.
val df = sqlContext.load("mydata.avro", "com.databricks.spark.avro")
df.save("mydata.parquet", "parquet")
Spark SQL has a unified framework to solve the same analytics problem both for batch & streaming, which has been the Holy Grail in data processing. Frameworks have been built which do either one of them and do it well in terms of scalability, performance and feature set, but having a unified framework for doing both batch and streaming was never feasible, before Spark / Spark SQL led the way. With Spark framework the same code (logic) can work either with batch data – RDDs or with Streaming Data Sets (DStreams – Discretized Streams). DStream is just a series of RDDs. This representation allows batch and streaming workloads to work seamlessly. This vastly reduces code maintenance overheads and training developers with 2 different skill sets.
Reading from JDBC Data Sources
Data source for reading from JDBC has been added as built-in source for Spark SQL. Spark SQL can extract data from any existing relational databases that supports JDBC. Examples include mysql, postgres, H2, and more. Reading data from one of these systems is as simple as creating virtual table that points to the external table. Data from this table can then be easily read in and joined with any of the other sources that Spark SQL supports.
Spark SQL with Data Frames
Data Frames are distributed collection of rows organized into named columns, an abstraction for selecting, filtering, aggregating and plotting, structured data – it was previously used to be called SchemaRDD.
DataFrame API can perform relational operations on both external data sources and Spark’s built-in distributed collections.
DataFrame offers rich relational/procedural integration within Spark programs. DataFrames are collections of structured records that can be manipulated using Spark’s procedural API, or using new relational APIs that allow richer optimizations. They can be created directly from Spark’s built-in distributed collections of objects, enabling relational processing in existing Spark.
DataFrames are more convenient and more efficient than Spark’s procedural API. They make it easy to compute multiple aggregates in one pass using a SQL statement, something that is difficult to express in traditional functional APIs.
Unlike RDDs, DataFrames keep track of their schema and support various relational operations that lead to more optimized execution. They infer the schema using reflection.
Spark DataFrames are lazy in that each DataFrame object represents a logical plan to compute a dataset, but no execution occurs until the user calls a special “output operation” such as save. This enables rich optimization across all operations.
DataFrames evolve Spark’s RDD model, making it faster and easier for Spark developers to work with structured data by providing simplified methods for filtering, aggregating, and projecting over large datasets. DataFrames are available in Spark’s Java, Scala, and Python API.
Spark SQL’s data source API can read and write DataFrames from a wide variety of data sources and data formats – Avro, parquet, ORC, JSON, H2.
Example of how writing less code– using plain RDDs and using DataFrame APIs for SQL
The scala example below shows equivalent code – one using Sparks RDD APIs and other one using Spark’s DataFrame API. Let us have an object – People – firstname, lastname, age being the attributes and the objective is to get the basic stats on age – People – grouped by firstname.
case class People(firstname: String, lastname: String, age: Intger)
val people = rdd.map(p => (people.firstname, people.age)).cache()
// RDD Code
val minAgeByFN = people.reduceByKey( scala.math.min(_, _) )
val maxAgeByFN = people.reduceByKey( scala.math.max(_, _) )
val avgAgeByFN = people.mapValues(x => (x, 1))
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
val countByFN = people.mapValues(x => 1).reduceByKey(_ + _)
// Data Frame Code
df = people.toDF
people = df.groupBy("firstname").agg(
min("age"),
max("age"),
avg("age"),
count("*"))
Data Frames are faster than using the plain RDDs due to the catalyst optimizer. DataFrames provide the same operations as relational query languages like SQL and Pig.
Approach to solving Streaming Analytics with Spark SQL
The diagram below shows thinking behind our approach of using Spark SQL for doing Real Time Analytics. This follows the well know pattern of Lambda Architecture for building Real Time Analytic systems for big streaming data.
Shortcomings of Spark SQL
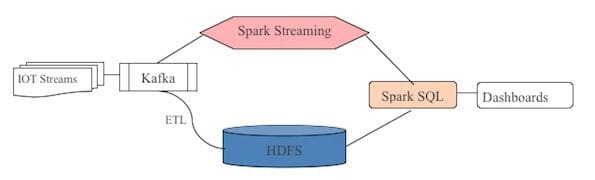
Same as any tool running on a Hadoop cluster – the SLAs do not depend on how fast the engine is – but depends on how many other concurrent users are running on the system.
The Spark SQL code is sometimes too pithy for a first user to comprehend what is being done. It takes some experience and practice to get used to the coding style and implicitness of spark SQL code.
Conclusion
Spark SQL as an important evolution of the core Spark API. While Spark’s original functional programming API was quite general, it offered only limited opportunities for automatic optimization. Spark SQL simultaneously makes Spark accessible to more users.
This article was an effort to prepare the fundamentals for the next set of articles where spark sql is used for doing real time analytics in IOT space.
References:
StreamSQL – https://en.wikipedia.org/wiki/StreamSQL
StreamSQL – https://github.com/thunderain-project/StreamSQL
Bio: Sumit Pal is a big data, visualisation and data science consultant. He is also a software architect and big data enthusiast and builds end-to-end data-driven analytic systems. Sumit has worked for Microsoft (SQL server development team), Oracle (OLAP development team) and Verizon (Big Data analytics team) in a career spanning 22 years. Currently, he works for multiple clients advising them on their data architectures and big data solutions and does hands on coding with Spark, Scala, Java and Python. Sumit blogs at sumitpal.wordpress.com/
Ajit Jaokar (@AjitJaokar) does research and consulting for Data Science and the Internet of Things. His work is based on his teaching at Oxford University and UPM (Technical University of Madrid) and covers IoT, Data Science, Smart cities and Telecoms.
Related: