Getting Started with Deep Learning
This post approaches getting started with deep learning from a framework perspective. Gain a quick overview and comparison of available tools for implementing neural networks to help choose what's right for you.
By Matthew Rubashkin, Silicon Valley Data Science.
Editor's note: Please note that, while this chart and post was up to date when it was first published, the landscape has changed in such a way that the table below is not depict a fully accurate picture at this point (e.g. Keras now supports a greater number of frameworks). The post is still beneficial, however, with this caveat noted.
At SVDS, our R&D team has been investigating different deep learning technologies, from recognizing images of trains to speech recognition. We needed to build a pipeline for ingesting data, creating a model, and evaluating the model performance. However, when we researched what technologies were available, we could not find a concise summary document to reference for starting a new deep learning project.
One way to give back to the open source community that provides us with tools is to help others evaluate and choose those tools in a way that takes advantage of our experience. We offer the chart below, along with explanations of the various criteria upon which we based our decisions.
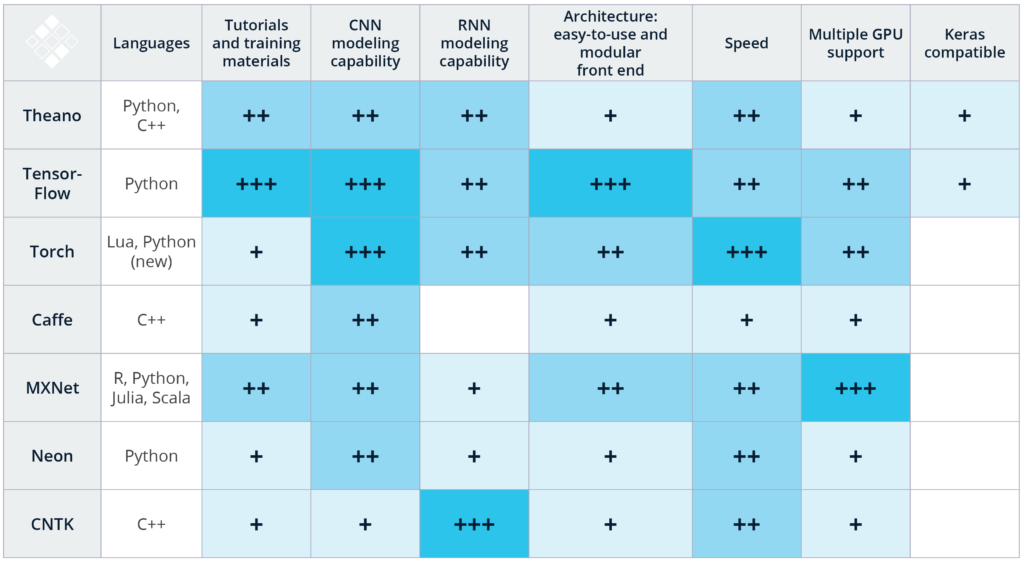
These rankings are a combination of our subjective experiences with image and speech recognition applications for these technologies, as well as publicly available benchmarking studies. Please note that this is not an exhaustive list of available deep learning toolkits, more of which can be found here. In the coming months, our team is excited to checkout DeepLearning4j, Paddle, Chainer, Apache Signa, and Dynet. We explain our scoring of the reviewed tools below:
Languages: When getting started with deep learning, it is best to use a framework that supports a language you are familiar with. For instance, Caffe (C++) and Torch (Lua) have Python bindings for its codebase, but we would recommend that you are proficient with C++ or Lua respectively if you would like to use those technologies. In comparison, TensorFlow and MXNet have great multi language support that make it possible to utilize the technology even if you are not proficient with C++.
Note: We have not had an opportunity to test out the new Python wrapper for Torch, PyTorch, released by Facebook AI Research (FAIR) in January 2017. This framework was built for Python programmers to leverage Torch’s dynamic construction of neural networks.
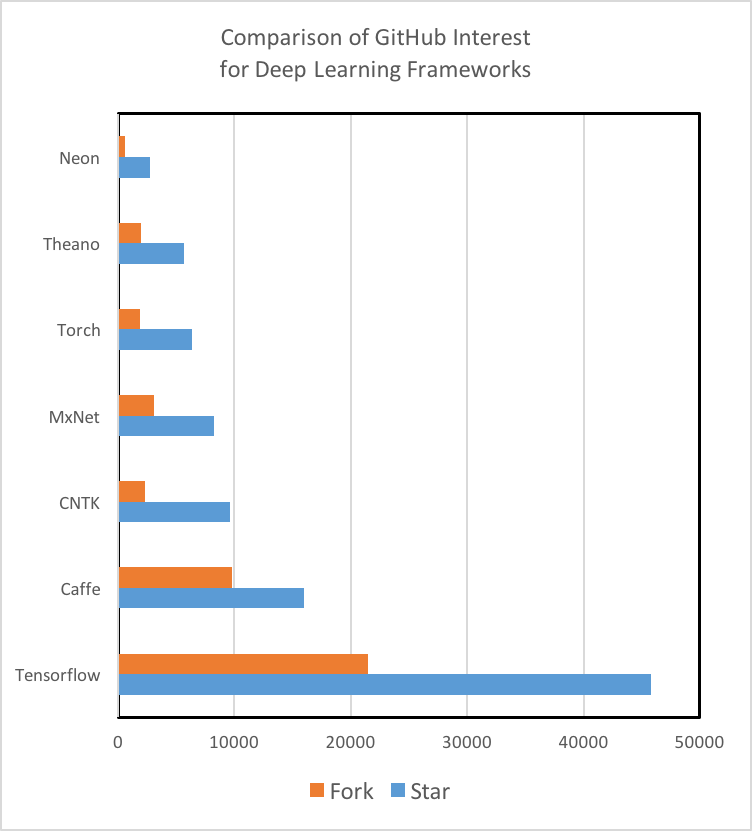
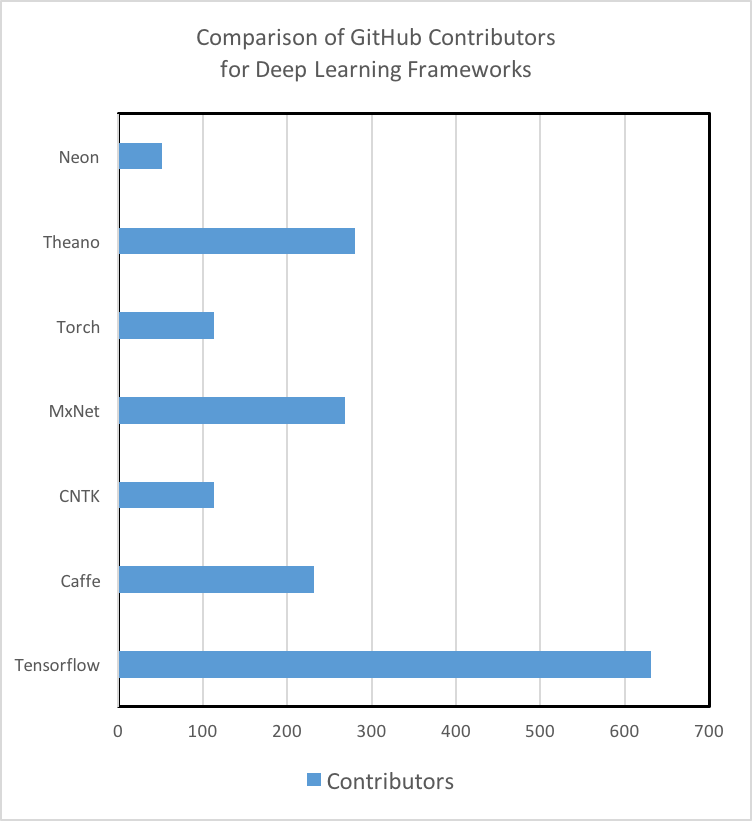
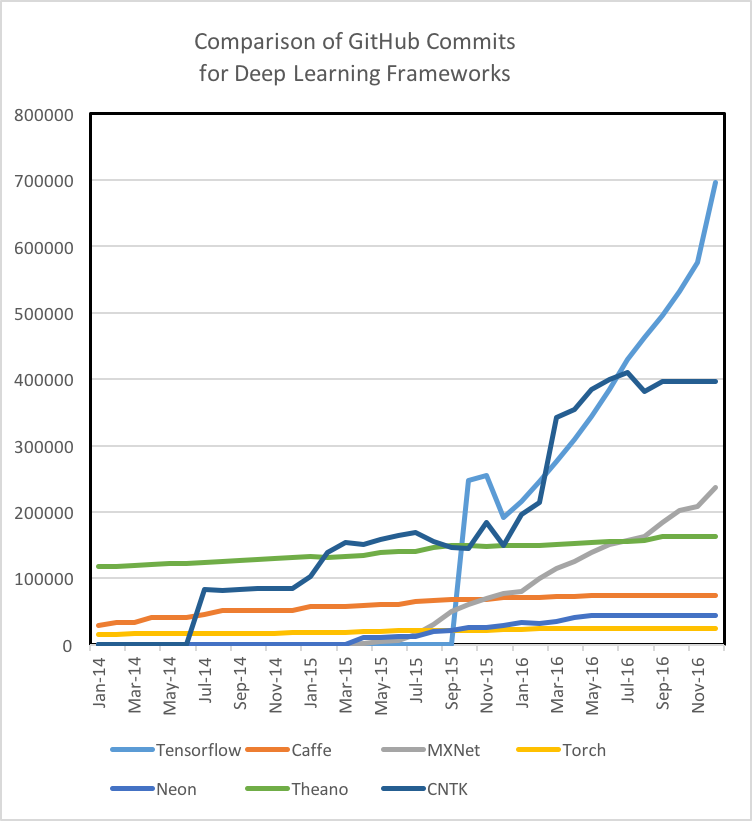
Tutorials and Training Materials: Deep learning technologies vary dramatically in the quality and quantity of tutorials and getting started materials. Theano, TensorFlow, Torch, and MXNet have well documented tutorials that are easy to understand and implement. While Microsoft’s CNTK and Intel’s Nervana Neon are powerful tools, we struggled to find beginner-level materials. Additionally, we’ve found that the engagement of the GitHub community is a strong indicator of not only a tool’s future development, but also a measure of how likely/fast an issue or bug can be solved through searching StackOverflow or the repo’s Git Issues. It is important to note that TensorFlow is the 800-pound Gorilla in the room in regards to quantity of tutorials, training materials, and community of developers and users.
CNN Modeling Capability: Convolutional neural networks (CNNs) are used for image recognition, recommendation engines, and natural language processing. A CNN is composed of a set of distinct layers that transform the initial data volume into output scores of predefined class scores (For more information, check out Eugenio Culurciello’s overview of Neural Network architectures). CNN’s can also be used for regression analysis, such as models that output of steering angles in autonomous vehicles. We consider a technology’s CNN modeling capability to include several features. These features include the opportunity space to define models, the availability of prebuilt layers, and the tools and functions available to connect these layers. We’ve seen that Theano, Caffe, and MXNet all have great CNN modeling capabilities. That said, TensorFlow’s easy ability to build upon it’s InceptionV3 model and Torch’s great CNN resources including easy-to-use temporal convolution set these two technologies apart for CNN modeling capability.
RNN Modeling Capability: Recurrent neural networks (RNNs) are used for speech recognition, time series prediction, image captioning, and other tasks that require processing sequential information. As prebuilt RNN models are not as numerous as CNNs, it is therefore important if you have a RNN deep learning project that you consider what RNN models have been previously implemented and open sourced for a specific technology. For instance, Caffe has minimal RNN resources, while Microsoft’s CNTK and Torch have ample RNN tutorials and prebuilt models. While vanilla TensorFlow has some RNN materials, TFLearn and Keras include many more RNN examples that utilize TensorFlow.
Architecture: In order to create and train new models in a particular framework, it is critical to have an easy to use and modular front end. TensorFlow, Torch, and MXNet have a straightforward, modular architecture that makes development straightforward. In comparison, frameworks such as Caffe require significant amount of work to create a new layer. We’ve found that TensorFlow in particular is easy to debug and monitor during and after training, as the TensorBoard web GUI application is included.
Speed: Torch and Nervana have the best documented performance for open source convolutional neural network benchmarking tests. TensorFlow performance was comparable for most tests, while Caffe and Theano lagged behind. Microsoft’s CNTK claims to have some of the fastest RNN training time. Another study comparing Theano, Torch, and TensorFlow directly for RNN showed that Theano performs the best of the three.
Multiple GPU Support: Most deep learning applications require an outstanding number of floating point operations (FLOPs). For example, Baidu’s DeepSpeech recognition models take 10s of ExaFLOPs to train. That is >10e18 calculations! As leading Graphics Processing Units (GPUs) such as NVIDIA’s Pascal TitanX can execute 11e9 FLOPs a second, it would take over a week to train a new model on a sufficiently large dataset. In order to decrease the time it takes to build a model, multiple GPUs over multiple machines are needed. Luckily, most of the technologies outlined above offer this support. In particular, MXNet is reported to have one the most optimized multi-GPU engine.
Keras Compatible: Keras is a high level library for doing fast deep learning prototyping. We’ve found that it is a great tool for getting data scientists comfortable with deep learning. Keras currently supports two back ends, TensorFlow and Theano, and will be gaining official support in TensorFlow in the future. Keras is also a good choice for a high-level library when considering that its author recently expressed that Keras will continue to exist as a front end that can be used with multiple back ends.
If you are interested in getting started with deep learning, I would recommend evaluating your own team’s skills and your project needs first. For instance, for an image recognition application with a Python-centric team we would recommend TensorFlow given its ample documentation, decent performance, and great prototyping tools. For scaling up an RNN to production with a Lua competent client team, we would recommend Torch for its superior speed and RNN modeling capabilities.
In the future we will discuss some of our challenges in scaling up our models. These challenges include optimizing GPU usage over multiple machines and adapting open source libraries like CMU Sphinx and Kaldi for our deep learning pipeline.
Bio: Matthew Rubashkin, with a background in optical physics and biomedical research, has a broad range of experiences in software development, database engineering, and data analytics. He enjoys working closely with clients to develop straightforward and robust solutions to difficult problems.
Original. Reposted with permission.
Related: