Open Source Toolkits for Speech Recognition
This article reviews the main options for free speech recognition toolkits that use traditional Hidden Markov Models and n-gram language models.
By Cindi Thompson, Silicon Valley Data Science.
As members of the deep learning R&D team at SVDS, we are interested in comparing Recurrent Neural Network (RNN) and other approaches to speech recognition. Until a few years ago, the state-of-the-art for speech recognition was a phonetic-based approach including separate components for pronunciation, acoustic, and language models. Typically, this consists of n-gram language models combined with Hidden Markov models (HMM). We wanted to start with this as a baseline model, and then explore ways to combine it with newer approaches such as Baidu’s Deep Speech. While summaries exist explaining these baseline phonetic models, there do not appear to be any easily-digestible blog posts or papers that compare the tradeoffs of the different freely available tools.
This article reviews the main options for free speech recognition toolkits that use traditional HMM and n-gram language models. For operational, general, and customer-facing speech recognition it may be preferable to purchase a product such as Dragon or Cortana. But in an R&D context, a more flexible and focused solution is often required, and that is why we decided to develop our own speech recognition pipeline. Below we list the top contenders in the free or open source world, and rate them on several characteristics.
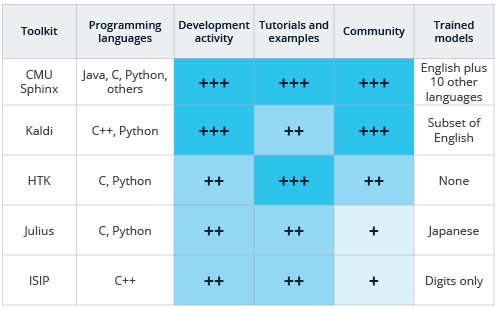
Comparison of open source and free speech recognition toolkits.
This analysis is based on our subjective experience and the information available from the repositories and toolkit websites. This is also not an exhaustive list of speech recognition software, most of which are listed here (which goes beyond open source). A 2014 paper by Gaida et.al. evaluates the performance of CMU Sphinx, Kaldi, and HTK. Note that HTK is not strictly open source in its usual interpretation, as the code cannot be redistributed or re-purposed for commercial use.
Programming Languages: Depending on your familiarity with different languages, you may naturally prefer one toolkit over another. All of the listed options except for ISIP have Python wrappers available either on the main site or found quickly with a web search. Of course, the Python wrappers may not expose the full functionality of the core code available in the toolkit. CMU Sphinx also has wrappers in several other programming languages.
Development activity: All of the projects listed have their origins in academic research. CMU Sphinx, as may be obvious from its name, is a product of Carnegie Mellon University. It’s existed in some form for about 20 years, and is now available on both GitHub (with C and Java versions there) and SourceForge, with recent activity on both. Both the Java and C versions appear to have only one contributor on GitHub, but this doesn’t reflect the historical reality of the project (there are 9 administrator and more than a dozen developers on the SourceForge repo). Kaldi has its academic roots from a 2009 workshop, with its code now hosted on GitHub with 121 contributors. HTK started its life at Cambridge University in 1989, was commercial for some time, but is now licenced back to Cambridge and is not available as open source software. While its latest version was updated in December of 2015, the prior release was in 2009. Julius has been in development since 1997 and had its last major release in September of 2016 with a somewhat active GitHub repo consisting of three contributors, which again is unlikely to reflect reality. ISIP was the first state-of-the-art open source speech recognition system, and originated from Mississippi State. It was developed mostly from 1996 to 1999, with its last release in 2011, but the project was mostly defunct before the emergence of GitHub.1
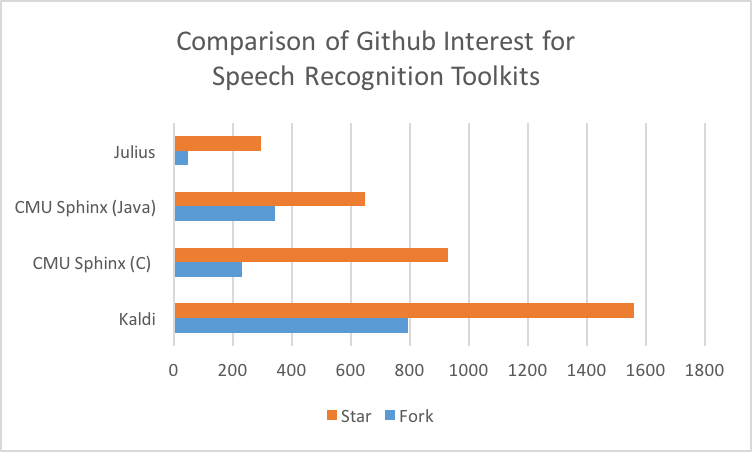
Community: Here we looked at both mailing and discussion lists and the community of developers involved. CMU Sphinx has online discussion forums and active interest in its repos. However, we wonder if the duplication of repos in both SourceForge and GitHub are blocking more widespread contribution. In comparison, Kaldi has both forums and mailing lists as well as an active GitHub repo. HTK has mailing lists but no open repository. The user forum link on the Julius web site is broken but there may be more information on the Japanese site. ISIP is primarily targeted for educational purposes and the mailing list archives are no longer functional.
Tutorials and Examples: CMU Sphinx has very readable, thorough, and easy to follow documentation; Kaldi’s documentation is also comprehensive but a bit harder to follow in my opinion. However, Kaldi does cover both the phonetic and deep learning approaches to speech recognition. If you are not familiar with speech recognition, HTK’s tutorial documentation (available to registered users) gives a good overview to the field, in addition to documentation on actual design and use of the system. The Julius project is focused on Japanese, and the most current documentation is in Japanese2, but they also are actively translating to English and provide that documentation as well; there are some examples of running speech recognition here. Finally, the ISIP project has some documentation, but is a little more difficult to navigate.
Trained models: Even though a main reason to use these open or free tools is because you want to train specialized recognition models, it is a big advantage when you can speak to the system out of the box. CMU Sphinx includes English and many other models ready to use, with the documentation for connecting to them with Python included right in the GitHub readme. Kaldi’s instructions for decoding with existing models is hidden deep in the documentation, but we eventually discovered a model trained on some part of an English VoxForge dataset in the egs/voxforge subdirectory of the repo, and recognition can be done by running the script in the online-data subdirectory. We didn’t dig as deeply into the other three packages, but they all come with at least simple models or appear to be compatible with the format provided on the VoxForge site, a fairly active crowdsourced repository of speech recognition data and trained models.
In the future, we will discuss how to get started using CMU Sphinx. We also plan to follow up on our earlier deep learning post with one that applies neural networks to speech, and will compare the neural net’s recognition performance to that of CMU Sphinx. In the meantime, we always love feedback and questions on our blog posts, so let us know if you have additional perspective on these toolkits or others.
References
- blog.neospeech.com/2016/07/08/top-5-open-source-speech-recognition-toolkits
- Gaida, Christian, et al. “Comparing open-source speech recognition toolkits.” Tech. Rep., DHBW Stuttgart (2014).
Bio: Cindi Thompson is a naturally collaborative problem-solver able to bridge technical and business concerns using strong communication and facilitation skills. With a PhD in artificial intelligence, she brings a unique blend of academic and industry experience in machine learning, natural language understanding, and R&D.
Original. Reposted with permission.
Related: