Domino – A Platform For Modern Data Analysis
Tools that facilitate data science best practices have not yet matured to match their counterparts in the world of software engineering. Domino is a platform built from the ground up to fill in these gaps and accelerate modern analytical workflows.
By Nick Elprin (Founder, Domino Data Lab)
As more organizations invest in maturing their analytical capabilities, data scientists are increasingly applying best practices from software engineering to make their workflows easier to manage (e.g., version control). Unfortunately, data analysis and software development have fundamental differences, which can lead to friction when transplanting tools and practices from the software world. As a result, data analysis teams either awkwardly graft tools on to their workflows, or they build their own custom toolset — or, lacking the resources for custom development, they simply tolerate inefficiency.
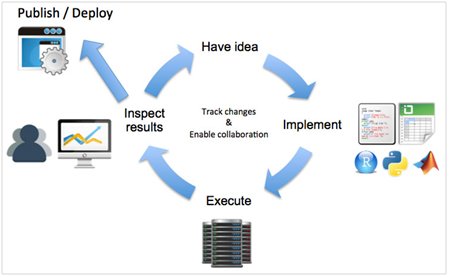
This article introduces Domino, a platform we have built from the ground up to support modern data analysis workflows. Domino is language agnostic (supports Python, R, MATLAB, Perl, Julia, shell scripts and more) and has rich functionality for version control and collaboration (think Github for data science) along with one-click infrastructure scalability (think Heroku for scripts), and deployment and publishing (like yhat) — all in an integrated end-to-end platform.
Requirements of a modern data science platform
The differences between software development and data science illuminate critical requirements of modern analytical workflows:

Domino addresses the above issues with a platform built around three key insights:
We have received a ton of positive feedback from data scientists who don’t have the time or engineering training to manage their own infrastructure or set up tools to facilitate best practices. We hope Domino will be useful to you, and we’d love to hear what you think!

Nick Elprin is a founder at Domino Data Lab. Prior to Domino, he built software at a large hedge fund. He has a BA and MS in computer science from Harvard.
Related:
As more organizations invest in maturing their analytical capabilities, data scientists are increasingly applying best practices from software engineering to make their workflows easier to manage (e.g., version control). Unfortunately, data analysis and software development have fundamental differences, which can lead to friction when transplanting tools and practices from the software world. As a result, data analysis teams either awkwardly graft tools on to their workflows, or they build their own custom toolset — or, lacking the resources for custom development, they simply tolerate inefficiency.
This article introduces Domino, a platform we have built from the ground up to support modern data analysis workflows. Domino is language agnostic (supports Python, R, MATLAB, Perl, Julia, shell scripts and more) and has rich functionality for version control and collaboration (think Github for data science) along with one-click infrastructure scalability (think Heroku for scripts), and deployment and publishing (like yhat) — all in an integrated end-to-end platform.
Requirements of a modern data science platform
The differences between software development and data science illuminate critical requirements of modern analytical workflows:
- Development is more exploratory and iterative; you don’t always know where you’re going. As a result, version control — the ability to browse past results and reproduce them — is not just a safety net, but actually critical context as you work.
Version control for data science has its own subtleties that make traditional source control systems, such as git, insufficient. For example, without tracking your data, you can’t reliably reproduce your work — but source control systems weren’t designed to handle large data files. And the outputs of your code matter, too: when your code runs, it produces charts, tables, or model parameters, which let you assess your progress and must be tracked as they change. - Transparency into your results is critical. Software build systems can run unit tests, but with analytical work, you don’t know ahead of time what the correct answer is, so you need to inspect your results visually. In many environments, other people need to inspect them, too.
- Hardware scalability is necessary during development, not just once you’ve deployed your final product.
- Loosely coupled integration with production applications. The end-goal of many analysis is a model that can be executed by a production business process (e.g., making a recommendation to a user), but data scientists are often bottlenecked on IT or engineering teams to deploy changes to the software. Data scientists need an easy way to deploy model changes on their own.
Domino addresses the above issues with a platform built around three key insights:
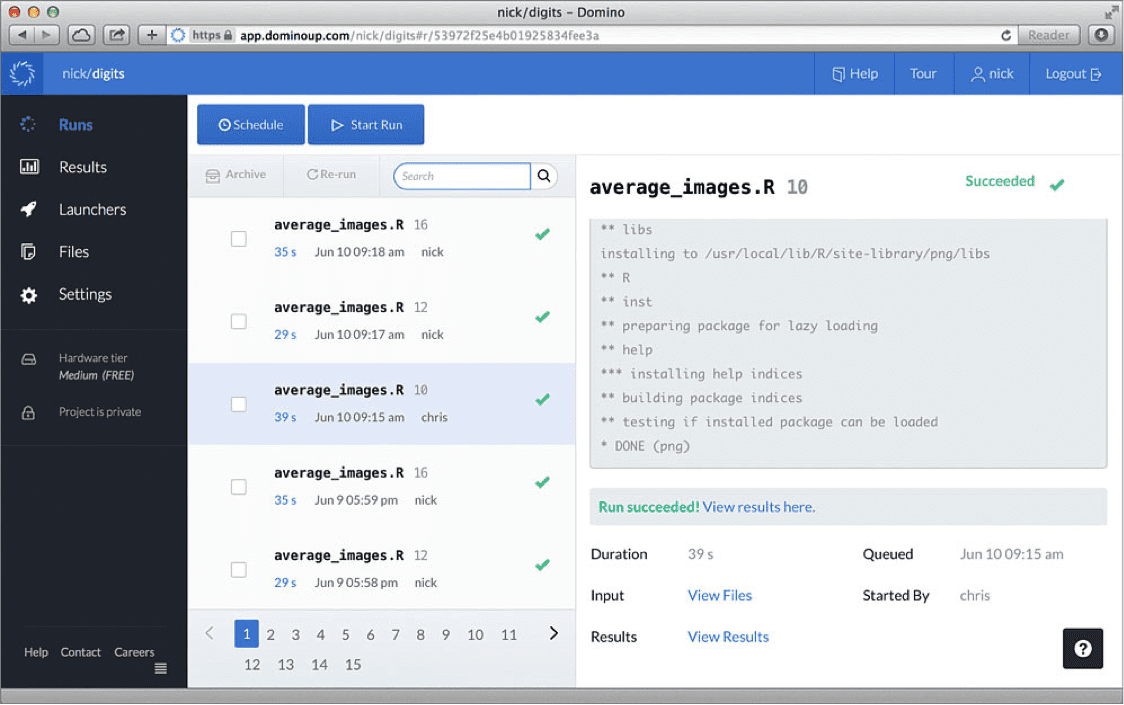
- Code + Data = Results, and all three components need to be tracked and linked together. Every time you execute your code, Domino keeps a snapshot of your project (including data files); when your code finishes, Domino takes another snapshot of any outputs your code generated. These are linked together as a “Run” — so you can always trace back from a result to the code and data that generated it.
- Storage and code execution should be centralized. This facilitates sharing and collaboration, as the central server can act as a hub that can enforce access controls for different collaborators, merge changes and detect conflicts, and send notifications to the team about changes. Results and diagnostics be served via the web, eliminating cumbersome email attachments.
Centralization of execution enables easy scaling: since code and data live together, the server has everything it needs to run on any type of hardware you choose, to spread multiple jobs across machines, or to schedule automatic recurring jobs. This allows massive speedup of development cycles.
Finally, centralization enables easy deployment. Domino can host your models as REST API endpoints, exposing them to your business processes through a clean interface. And for direct human consumers, Domino lets you build lightweight self-service web forms on top of your model, so internal stakeholders can run your model with their own parameter values whenever they want, without bothering you. - Your desktop environment is (still) a great place for authoring and debugging code. There are already tons of great tools for editing, and we don’t see a need for an in-browser IDE. Domino makes it easy to synchronize your local files with the server, so you can work locally using the tools you love, and run on powerful machines when you want to.
We have received a ton of positive feedback from data scientists who don’t have the time or engineering training to manage their own infrastructure or set up tools to facilitate best practices. We hope Domino will be useful to you, and we’d love to hear what you think!
Nick Elprin is a founder at Domino Data Lab. Prior to Domino, he built software at a large hedge fund. He has a BA and MS in computer science from Harvard.
Related: