Brain Monitoring with Kafka, OpenTSDB, and Grafana
Interested in using open source software to monitor brain activity, and control your devices? Sure you are! Read this fantastic post for some insight and direction.
By Jeff Lam, Silicon Valley Data Science.

Here at SVDS, we’re a brainy bunch. So we were excited when Confluent announced their inaugural Kafka Hackathon. It was a great opportunity to take our passion for data science and engineering, and apply it to neuroscience.
We wondered, “Wouldn’t it be cool to monitor our brain wave activity? And process those signals to control devices like home appliances, light switches, TV’s, and drones?“ We didn’t end up having enough time to implement mind control of any IoT devices during the 2-hour hackathon. However, we did win 2nd place with our project: streaming brainwave EEG data through Kafka’s new Streams API, storing the data on OpenTSDB with Kafka’s Connect API, and finally visualizing the time series with Grafana. In this post, we’ll give a quick overview of how we did all this, reveal the usage of Confluent’s unit testing utilities, and, as a bonus, we’ll show how it’s done in Scala.
Please note that this is not meant to be a production-ready application. But, we hope readers will learn more about Kafka and we welcome contributions to the source code for those who wish to further develop it.
Installation Requirements
All source code for our demo application can be found in our GitHub repository.
We used the Emotiv Insight to collect brainwave data, but the more powerful Epoc+ model should work, too. For those who don’t have access to the device, a pre-recorded data sample CSV file is included in our GitHub repository, and you may skip ahead to the “Architecture” section.
In order to collect the raw data from the device, you must install Emotiv’s Premium SDKwhich, unfortunately, isn’t free. We’ve tested our application on Mac OS X, so our instructions henceforth will reference that operating system.
Once you’ve installed the Premium SDK, open their “EEGLogger.xcodeproj” example application.
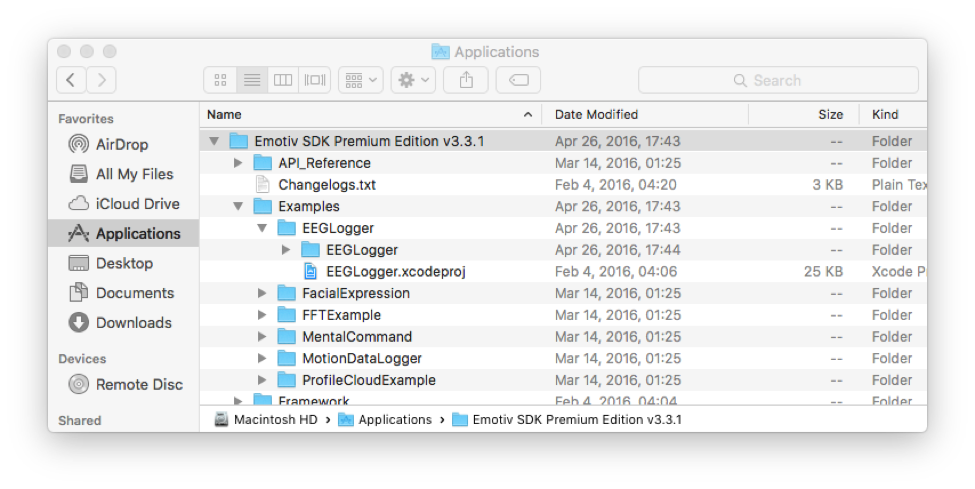
Assuming you have Xcode installed, the example application will open in Xcode. If you have the Insight instead of the Epoc+, you will need to uncomment a few lines in their Objective-C code. Go to the “getNextEvent” method in the “ViewController.mm” file and uncomment the lines of code for the Insight, and comment out the lines of code for the Epoc+.
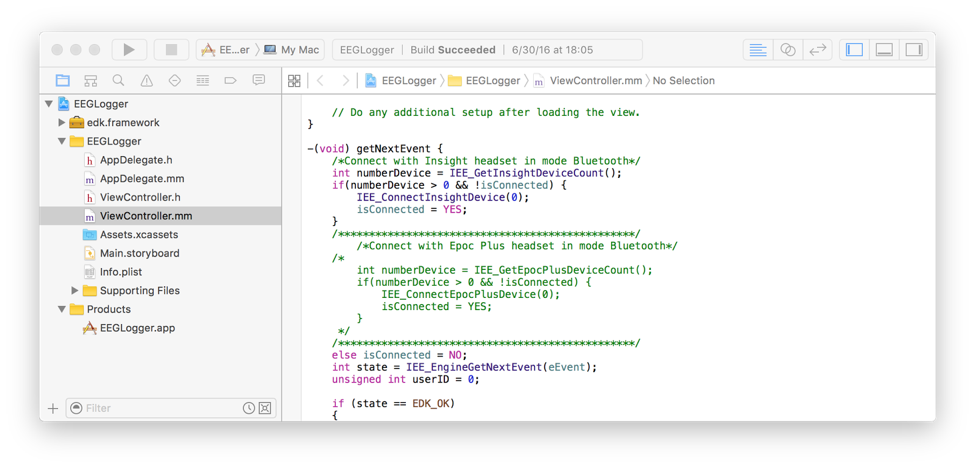
Next, save your changes and press the “play” button in Xcode to run their example app on your Mac. Power on your Insight or Epoc+ headset and the example app will soon indicate that it’s connected (via Bluetooth). Once the Bluetooth connection to the headset is established, you’ll see log output in Xcode. That’s your cue to inspect the raw EEG output in the generated CSV file found in your Mac at the path:
~/Library/Developer/Xcode/DerivedData/EEGLogger-*/Build/Products/Debug/EEGDataLogger.csv
Press the “stop” button in Xcode for now.
Architecture
To give you a high level overview of the system, the steps of the data flow are:
- Raw data from the Emotiv headset is read via Bluetooth by their sample Mac app and appended to a local CSV file.
- We run “tail -f” on the CSV file and pipe the output to Kafka’s console producer into the topic named “sensors.”
- Our main demo Kafka Streams application reads each line of the CSV input as a message from the “sensors” topic and transforms them into Avro messages for output to the “eeg” topic. We’ll delve into the details of the code later in this blog post.
- We also wrote a Kafka sink connector for OpenTSDB, which will take the Avro messages from “eeg” topic and save the data into OpenTSDB. We’ll also describe the code for the sink connector in more detail later in this blog post.
- Grafana will regularly poll OpenTSDB for new data and display the EEG readings as a line graph.
Note that, in a production-ready system, brain EEG data from many users would perhaps be streamed from Bluetooth to each user’s mobile app that in turn sends the data into a data collection service in your cloud infrastructure. Also note that, for simplicity’s sake, we did not define partition keys for any of the Kafka topics in this demo.