How to Improve Machine Learning Performance? Lessons from Andrew Ng
5 useful tips and lessons from Andrew Ng on how to improve your Machine Learning performance, including Orthogonalisation, Single Number Evaluation Metric, and Satisfying and Optimizing Metric.
You have worked for weeks on building your machine learning system and the performance is not something you are satisfied with. You think of multiple ways to improve your algorithm’s performance, viz, collect more data, add more hidden units, add more layers, change the network architecture, change the basic algorithm etc. But which one of these will give the best improvement on your system? You can either try them all, invest a lot of time and find out what works for you. OR! You can use the following tips from Ng’s experience.

Orthogonalisation
One of the challenges with building machine learning systems is that there are so many things you could try, so many things you could change. Including, for example, so many hyperparameters you could tune. The art of knowing what parameter to tune to get what effect, is called orthogonalisation.
In supervised learning, one needs to perform well on the following four tasks and for each of them, there should be a set of knobs which can be tuned for that task to perform well.
- Fit training set well
- Fit dev set well
- Fit test set well
- Perform well in real world
Suppose, your algo isn’t doing well on training set, you want one knob, or maybe one specific set of knobs that you can use, to make sure you can tune your algorithm to make it fit well on the training set. The knobs you use to tune this are, may be train a bigger network or switch to a better optimization algorithm, like the Adam optimization algorithm, and so on. In contrast, if your algorithm is not doing well on the dev set, then you have a set of knobs around regularization that you can use to try to make it satisfy the second criteria. Thus, knowing your tuning knobs well will help improve your system quicker.
Single Number Evaluation Metric
Have a single real number metric for your project as an evaluation metric so that you know if tuning a knob is helping your algorithm or not. While testing multiple scenarios, this metric can help you choose the most efficient algorithm quickly. Sometimes, you might need two metrics to evaluate your algorithm, say precision and recall. But with two evaluation metrics, it gets difficult to mark which algorithm is performing better.
![]()
Hence, rather than using two numbers, precision and recall, to pick a classifier, you just have to find a new evaluation metric that combines precision and recall. In the machine learning literature, the standard way to combine precision and recall is something called an F1 score. You will rarely ever have to devise a new performance measure yourself as you can generally find one in ML literature based on the requirements of your system.
Satisfying and Optimizing Metric
There might be cases where you don’t have just 1 (or 2) but n metrics that you care about for your system. Suppose you are asked to create a classifier with maximum accuracy, with minimum time and space complexity. You build the following 4 classifiers, which one do you deliver?
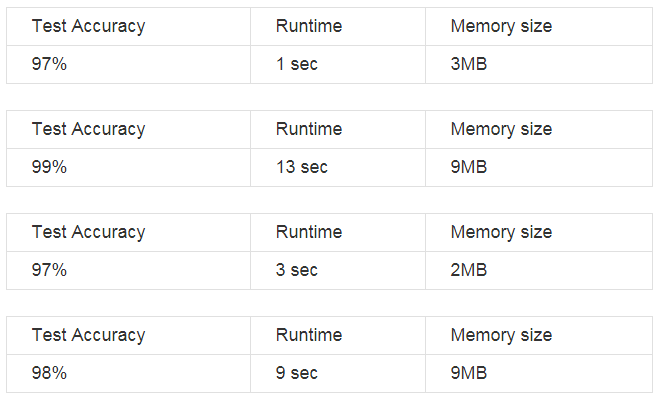
In such cases, choose one metric as optimizing and (n-1) metrics as satisficing. Here, maximize Test Accuracy (optimizing), have Runtime less than 10sec and Memory requirement less than 10MB (satisfying a threshold). By doing all these, you are setting a goal for your team so that they know what needs to be achieved.
Everyone in the Machine Learning universe knows about Andrew Ng, and if they know him, they also know about his Deep Learning Specialization courseon Coursera. If you want to break into AI, this Specialization will help you do so. One of the courses in this specialization talks about Structuring Machine Learning Projects, where you understand how to diagnose errors in a machine learning system and prioritize most promising directions for reducing those errors. This article is based off of this course in the specialization.
Train/Dev/Test Distributions
Always make sure that your development and test sets come from the same distribution and it must be taken randomly from all the data. For example, you are building a cat classifier and you have data from US, UK, South America, India, China, and Australia. It will be incorrect to use data from first three regions as dev set and from last three regions as test set. Shuffle all this data and randomly select both the sets.
Choose a dev/test set to reflect data you expect to get in the future and consider important to do well on.
Change dev/test set and evaluation metrics
If half way through your project you realise you chose wrong dev set or wrong metric to measure your performance, change them. After all, the success of your machine learning depends on -
- Knowing what to aim at (Choosing correct dev set and evaluation metric)
- Aiming it well (Performing well on these metric)
If doing well on your metric + dev/test set does not correspond to doing well on your application, it is time to change them. You have not set your aim well.
Conclusion
Understand the application of your machine learning algorithm, collect data accordingly and split train/dev/test sets randomly. Come up with a single optimizing evaluation metric and tune your knobs to improve on this metric.
I hope this post helped you learn how to build a successful machine learning project. There will be more posts following this one to talk about human level performance, avoidable bias, error analysis, data mismatch, multi-tasking etc.
If you have any questions/suggestions, feel free to reach out with your comments, connect with me on LinkedIn, or Twitter
Original. Reposted with permission.
Related