 Hadoop for Beginners
Hadoop for Beginners
 Hadoop for Beginners
Hadoop for BeginnersAn introduction to Hadoop, a framework that enables you to store and process large data sets in parallel and distributed fashion.
By Aafreen Dabhoiwala, Data Scientist Intern
This article is to give brief introduction about Hadoop for those who know next to nothing about this technology. Big Data is at the foundation of all the megatrends that are happening today, from social to the cloud to mobile devices to gaming. This article will help to build the foundation to take the next step in learning this interesting technology. Let's get started:
What's Big Data?
Ever since the enhancement of technology, data has been growing every day. Everyone owns gadgets nowadays. Every smart device generates data. One of the prominent sources of data is social media. We, being social animal love to share our thoughts, feelings with others and social media is the right platform for the interaction with other all around the world.
The following image shows data generated by users on the social media every 60 seconds. Data has been exponentially getting generated through these sources.
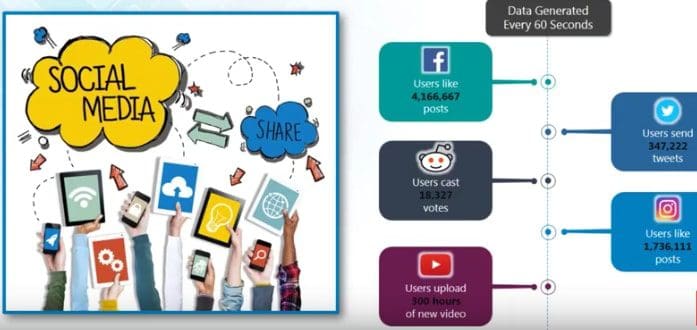
Social Media Data Analysis
The following image show the Global Mobile Data Traffic prediction by Cisco till 2020.
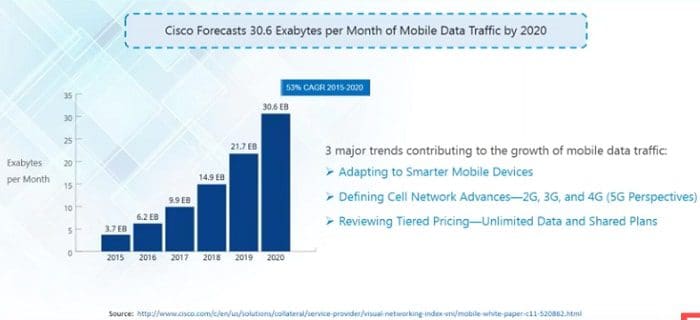
Big Data term used for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.
Depending on the industry and organization, big data encompasses information from various internal and external sources such as transactions, social media, enterprise content, sensors and mobile devices etc. Companies can leverage data to meet their customer needs, optimize their products, services and operations. This massive amount of data can also be used by the companies to find new sources of the revenue.
How did Hadoop come into picture?
These massive amounts of data generated is difficult to store and process using traditional database system. Traditional database management system is used to store and process relational and structured data only. However, in today's world there are lots of unstructured data getting generated like images, audio files, videos; hence traditional system will fail to store and process these kinds of data. Effective solution for this problem is Hadoop.
Hadoop is a framework to process Big Data. It is a framework that enables you to store and process large data sets in parallel and distributed fashion.
Hadoop Core Components:
There are two main components of Hadoop: HDFS and MapReduce.
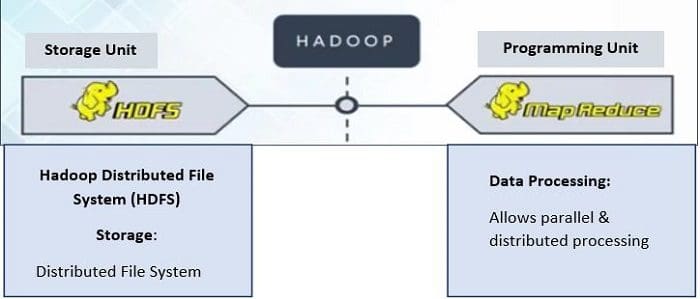
Hadoop Distributed File System (HDFS) takes care of storage part of Hadoop architecture.
MapReduceis a processing model and software framework for writing applications which can run on Hadoop. These programs of MapReduce are capable of processing Big Data in parallel on large clusters of computational nodes.
What's HDFS and what are its core components?
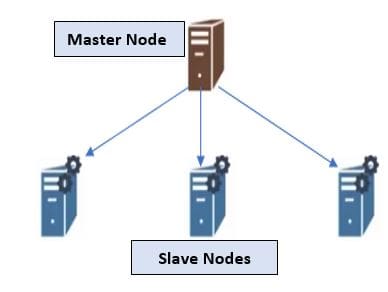
HDFS stores files across many nodes in a cluster.
Hadoop follows Master-Slave architecture and hence HDFS being its core component also follows the same architecture.
NameNode and DataNode are the core components of HDFS:
NameNode:
- Maintains and Manages DataNodes.
- Records Metadata i.e. information about data blocks e.g. location of blocks stored, the size of the files, permissions, hierarchy, etc.
- Receives status and block report from all the DataNodes.
DataNode:
- Slave daemons. It sends signals to NameNode.
- Stores actual It stores in data blocks.
- Serves read and write requests from the clients.
Secondary NameNode:
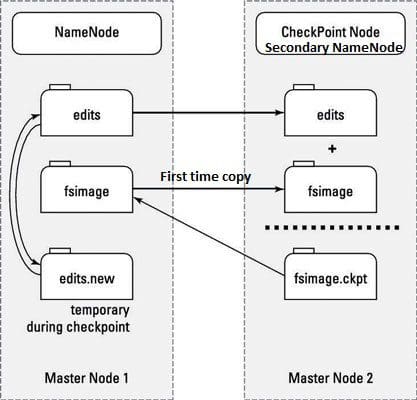
- This is NOT a backup NameNode. However, it is a separate service that keeps a copy of both the edit logs (edits) and filesystem image (fsimage) and merging them to keep the file size reasonable.
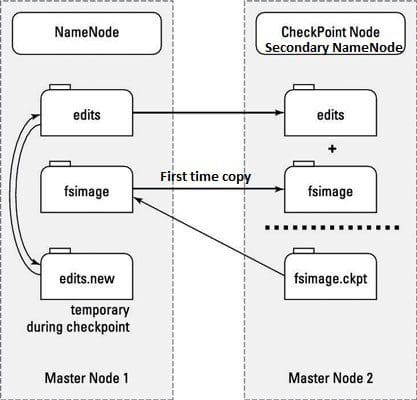
Secondary NameNode and Checkpointing
- MetaData of NameNode is managed by two files: fsimage and edit logs.
- Fsimage: This file contains all the modifications that happens across the Hadoop namespace or HDFS when the NameNode starts. It's stored in the local disk of the NameNode machine.
- Edit logs: This file contains the most recent modification. It’s a small file comparatively to the fsimage. Its stored in the RAM of the NameNode machine.
- Secondary NameNode performs the task of Checkpointing.
- Checkpointing is the process of combining edit logs with fsimage (edit logs + fsimage).Secondary NameNode creates copy of edit logs and fsimage from the NameNode to create final fsimage as shown in the above figure.
- Checkpointing happens periodically. (default 1 hour).
Why final fsimage file is required in Secondary NameNode?
- Final fsimage in the Secondary NameNode allows faster failover as it prevents edit logs in the NameNode from getting too huge.
- new log file in the NameNode contains all the modifications/changes that happen during the checkinpointing. Its temporary.
How the data is stored in DataNodes? HDFS Data Blocks.
Each file is stored on HDFS as blocks. The default size of each block is 128MB in Apache Hadoop 2.x (64 MB in Apache Hadoop 1.x)
After file is divided into data blocks as shown in the below figure, these data blocks will be then distributed across all the Data Nodes present in the Hadoop cluster.
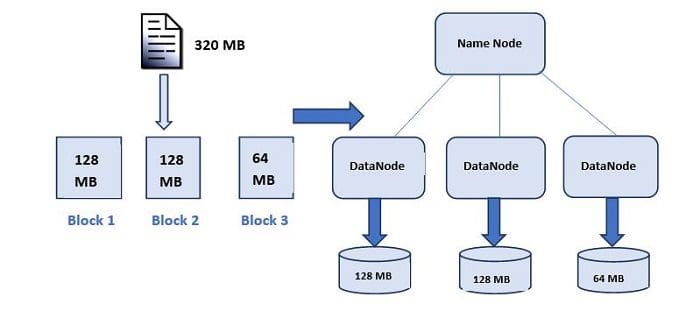
What's the advantages of HDFS and what makes it ideal for distribute systems?
- Fault Tolerance–Each data blocks are replicated thrice ((everything is stored on three machines/DataNodes by default) in the cluster. This helps to protect the data against DataNode (machine) failure.
- Space – Just add more datanodes and re-balance the size if you need more disk space.
- Scalability – Unlike traditional database system that can't scale to process large datasets; HDFS is highly scalable because it can store and distribute very large datasets across many nodes that can operate in parallel.
- Flexibility –It can store any kind of data, whether its structured, semi-structured or unstructured.
- Cost-effective – HDFS has direct attached storage and shares the cost of the network and computers it runs on with the MapReduce. It's also an open source software.
In the next article we shall discuss about MapReduce, another core component of Hadoop. Stay tuned.
Bio: Aafreen Dabhoiwala is a Data Scientist Intern with Viasat Inc and a graduate student of MS in Information Science at the University of Colorado Denver. He is a Software Developer turned to a Data Scientist, with interests in Machine Learning, IoT, Data Science and Big Data. Contact him at aafreen2902@gmail.com
Related:
- Python eats away at R: Top Software for Analytics, Data Science, Machine Learning in 2018: Trends and Analysis
- Three Ways Big Data and Machine Learning Reinvent Online Video Experience
- Did Spark Really Kill Hadoop?