Building a Question-Answering System from Scratch
This part will focus on introducing Facebook sentence embeddings and how it can be used in building QA systems. In the future parts, we will try to implement deep learning techniques, specifically sequence modeling for this problem.
By Alvira Swalin, University of San Francisco

As my Masters is coming to an end, I wanted to work on an interesting NLP project where I can use all the techniques(not exactly) I have learned at USF. With the help of my professors and discussions with the batch mates, I decided to build a question-answering model from scratch. I am using the Stanford Question Answering Dataset (SQuAD). The problem is pretty famous with all the big companies trying to jump up at the leaderboard and using advanced techniques like attention based RNN models to get the best accuracy. All the GitHub repositories that I found related to SQuAD by other people have also used RNNs.
However, my goal is not to reach the state of the art accuracy but to learn different NLP concepts, implement them and explore more solutions. I always believed in starting with basic models to know the baseline and this has been my approach here as well. This part will focus on introducing Facebook sentence embeddings and how it can be used in building QA systems. In the future parts, we will try to implement deep learning techniques, specifically sequence modeling for this problem. All the codes can be found on this Github repository.
But let’s first understand the problem. I will give a brief overview, however, a detailed understanding of the problem can be found here.
SQuAD Dataset
Stanford Question Answering Dataset (SQuAD) is a new reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage. With 100,000+ question-answer pairs on 500+ articles, SQuAD is significantly larger than previous reading comprehension datasets.
Problem
For each observation in the training set, we have a context, question, and text. Example of one such observation-

The goal is to find the text for any new question and context provided. This is a closed dataset meaning that the answer to a question is always a part of the context and also a continuous span of context. I have broken this problem into two parts for now -
- Getting the sentence having the right answer (highlighted yellow)
- Once the sentence is finalized, getting the correct answer from the sentence (highlighted green)
Introducing Infersent, Facebook Sentence Embedding
These days we have all types of embeddings word2vec, doc2vec, food2vec, node2vec, so why not sentence2vec. The basic idea behind all these embeddings is to use vectors of various dimensions to represent entities numerically, which makes it easier for computers to understand them for various downstream tasks. Articles explaining these concepts are linked for your understanding.
Traditionally, we used to average the vectors of all the words in a sentence called the bag of words approach. Each sentence is tokenized to words, vectors for these words can be found using glove embeddings and then take the average of all these vectors. This technique has performed decently, but this is not a very accurate approach as it does not take care of the order of words.
Here comes Infersent, it is a sentence embeddings method that provides semantic sentence representations. It is trained on natural language inference data and generalizes well to many different tasks.
The process goes like this-
Create a vocabulary from the training data and use this vocabulary to train infersent model. Once the model is trained, provide sentence as input to the encoder function which will return a 4096-dimensional vector irrespective of the number of words in the sentence. [demo]
These embeddings can be used for various downstream tasks like finding similarity between two sentences. I have implemented the same for Quora-Question Pair kaggle competition. You can check it out here.
Coming to the SQuAD problem, below are the ways I have tried using sentence embedding to solve the first part of the problem described in the previous section-
- Break the paragraph/context into multiple sentences. The two packages that I know for processing text data are - Spacy & Textblob. I have used package TextBlob for the same. It does intelligent splitting, unlike spacy’s sentence detection which can give you random sentences on the basis of period. An example is provided below:

Example: Paragraph

TextBlob is splitting it into 7 sentences which makes sense

Spacy is splitting it into 12 sentences
- Get the vector representation of each sentence and question using Infersent model
- Create features like distance, based on cosine similarity and Euclidean distance for each sentence-question pair
Models
I have further solved the problem using two major methods-
- Unsupervised Learning where I am not using the target variable. Here, I am returning the sentence form the paragraph which has the minimum distance from the given question
- Supervised Learning - Creation of training set has been very tricky for this part, the reason being the fact that there is no fixed number of sentences in each part and answer can range from one word to multiple words. The only paper I could find that has implemented logistic regression is by the Stanford team who has launched this competition & dataset. They have used multinomial logistic regression explained in this paper and have created 180 million features (sentence detection accuracy for this model was 79%), but it is not clear how they have defined the target variable. If anyone has any idea, please, clarify the same in the comments. I will explain my solution later.
Unsupervised Learning Model
Here, I first tried using euclidean distance to detect the sentence having minimum distance from the question. The accuracy of this model came around 45%. Then, I switched to cosine similarity and the accuracy improved from 45% to 63%. This makes sense because euclidean distance does not care for alignment or angle between the vectors whereas cosine takes care of that. Direction is important in case of vectorial representations.
But this method does not leverage the rich data with target labels that we are provided with. However, considering the simple nature of the solution, this is still giving a good result without any training. I think the credit for the decent performance goes to Facebook sentence embedding.
Supervised Learning Models
Here, I have transformed the target variable form text to the sentence index having that text. For the sake of simplicity, I have restricted my paragraph length to 10 sentences (around 98% of the paragraphs have 10 or fewer sentences). Hence, I have 10 labels to predict in this problem.
For each sentence, I have built one feature based on cosine distance. If a paragraph has less number of sentences, then I am replacing it’s feature value with 1 (maximum possible cosine distance) to make total 10 sentences for uniformity. It will be easier to explain this process with an example.
Let’s take the first observation/row of the training set. The sentence having the answer is bolded in the context.:
Example
Question — “To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?”
Context — “Architecturally, the school has a Catholic character. Atop the Main Building\’s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend “Venite Ad Me Omnes”. Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.”
Text — “Saint Bernadette Soubirous”
In this case, the target variable will become 5, because that’s the index of the bolded sentence. We will have 10 features each corresponding to one sentence in the paragraph. The missing values for column_cos_7, column_cos_8, and column_cos_9 are filled with 1 because these sentences do not exists in the paragraph

Dependency Parsing
Another feature that I have used for this problem is the “Dependency Parse Tree”. This is marginally improving the accuracy of the model by 5%. Here, I have used Spacy tree parsing as it is has a rich API for navigating through the tree.
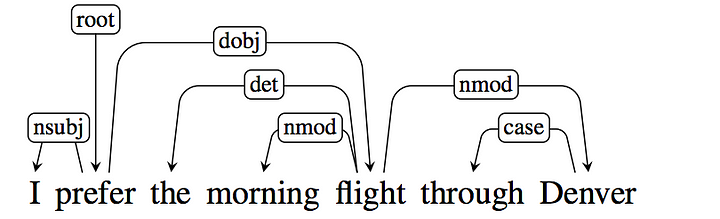

For more details: Please check out Stanford Lecture
Relations among the words are illustrated above the sentence with directed, labeled arcs from heads to dependents. We call this a Typed Dependency structure because the labels are drawn from a fixed inventory of grammatical relations. It also includes a root node that explicitly marks the root of the tree, the head of the entire structure.
Let’s visualize our data using Spacy tree parse. I am using the same example provided in the previous section.
Question — “To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?”

Sentence having the answer — “It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858”

Roots of All the Sentences in the Paragraph

The idea is to match the root of the question which is “appear” in this case to all the roots/sub-roots of the sentence. Since there are multiple verbs in a sentence, we can get multiple roots. If the root of the question is contained in the roots of the sentence, then there are higher chances that the question is answered by that sentence. Considering that in mind, I have created one feature for each sentence whose value is either 1 or 0. Here, 1 represents that the root of question is contained in the sentence roots and 0 otherwise.
Note: It is important to do stemming before comparing the roots of sentences with the question root. In the previous example, root word for question is appear while the root word in the sentence is appeared. If you don’t stem appear & appeared to a common term, them matching won’t be possible.
The example below is the transposed data with 2 observations from the processed training data. So, we have 20 features in total combining cosine distance and root match for 10 sentences in a paragraph. The target variable ranges from 0 to 9.

Note: It is very important to standardize all the columns in your data for logistic regression.
Once, the training data is created, I have used multinomial logistic regression, random forest & gradient boosting techniques.
The accuracy of multinomial logistic regression is 65% for the validation set. Considering the original model which had a lot of features with an accuracy of 79%, this one is quite simpler. The random forest gave an accuracy of 67% and finally, XGBoost worked best with an accuracy of 69%on the validation set.
I will be adding more features (NLP related) to improve these models.
Ideas related to feature engineering or other improvements are highly welcomed. All the codes related to above concepts are provided here.
In the next part, we will focus on the text extraction (correct span) from the sentences shortlisted in this part. In the meantime, check out my other blogs here!
References
- Github Repository with Codes
- Facebook Repo for Infersent
- Best Resource Paper explaining the Logistic Regression
- Blog Explaining the Problem
- Leaderboard & Dataset
Bio: Alvira Swalin (Medium) is currently pursuing Master's in Data Science at USF, I am particularly interested in Machine Learning & Predictive Modeling. She is a Data Science Intern at Price (Fx).
Original. Reposted with permission.
Related:
- CatBoost vs. Light GBM vs. XGBoost
- Choosing the Right Metric for Evaluating Machine Learning Models – Part 1
- Choosing the Right Metric for Evaluating Machine Learning Models – Part 2