 XLNet Outperforms BERT on Several NLP Tasks
XLNet Outperforms BERT on Several NLP Tasks
 XLNet Outperforms BERT on Several NLP Tasks
XLNet Outperforms BERT on Several NLP TasksXLNet is a new pretraining method for NLP that achieves state-of-the-art results on several NLP tasks.
By Elvis Saravia, Affective Computing & NLP Researcher
Two pretraining objectives that have been successful for pretraining neural networks used in transfer learning NLP are autoregressive (AR) language modeling and autoencoding (AE).
Autoregressive language modeling is not able to model deep bidirectional context which has recently been found to be effective in several downstream NLP tasks such as sentiment analysis and question answering.
On the other hand, autoencoding based pretraining aims to reconstruct original data from corrupted data. A popular example of such modeling is used in BERT, an effective state-of-the-art technique used to address several NLP tasks.
One advantage of models like BERT is that bidirectional contexts can be used in the reconstruction process, something that AR language modeling lacks. However, BERT partially masks the input (i.e. tokens) during pretraining which results in a pre-training-finetune discrepancy. In addition, BERT assumes independence on predicted tokens, something which AR models allow for via the product rule which is used to factorize the joint probability of predicted tokens. This could potentially help with the pretrain-finetune discrepancy found in BERT.
The proposed model (XLNet) borrows ideas from the two types of language pretraining objectives (AR and AE) while avoiding their limitations.
The XLNet model
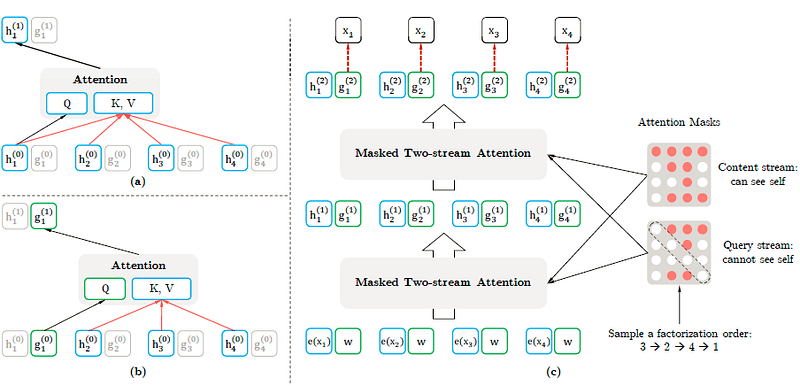
XLNet makes use of a permutation operation during training time that allows context to consists of tokens from both left and right, capturing the bidirectional context, making it a generalized order-aware AR language model. During pretraining, XLNet adopts the segment recurrent mechanism and relative encoding scheme proposed in Transformer-XL.
Essentially, the novel permutation language modeling objective (see paper for extra details) allows sharing of the model parameters across all the permuted factorization orders. This enables the AR model to properly and effectively capture bidirectional context while avoiding the independence assumption and pretrain-finetune discrepancy that BERT is subject to.
Simply put it, XLNet keeps the original sequence order, uses positional encodings, and relies on a special attention mask in Transformers to achieve the said permutation of the factorization order. In other words, the original Transformer architecture is modified and re-parameterized to avoid issues such as target ambiguity and pretrain-finetune discrepancy.
The core change happens in the hidden representation layers (see paper for details). XLNet is based on the Transformer-XL which it uses as the main pretraining framework. Obviously, for the proposed permutation operation to work, a few modifications are proposed, which enforce the proper reuse of the hidden states from previous segments. Some design ideas from BERT are also used to perform partial prediction and support certain tasks that consist of multiple segments like question and context paragraph in question answering.
From the following examples below, we can observe that both BERT and XLNet compute the objective differently. In general, XLNet captures more important dependencies between prediction targets, such as (New, York), which BERT omits.
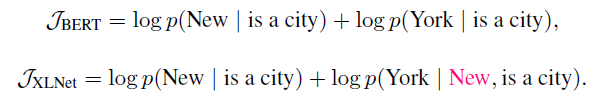
XLNet also proves to cover more dependencies as compared to GPT and ELMo.
Overall, XLNet makes a compelling case for bridging the gap between language modeling and pretraining, all achieved by leveraging AR modeling and borrowing techniques from previous methods like BERT and Transformer-XL. More importantly, XLNet aims to address the pretrain-finetune discrepancy, which means language models can potentially improve downstream tasks through this useful generalization.
Experiments
Several sources like BooksCorpus, English Wikipedia, Giga5, and Common Crawl are combined and used for pretraining. Tokenization is achieved with SentencePiece.
The same architecture hyperparameters as BERT-Large are used in XLNet-Large and trained on 512 TPU v3 chips for 500K epochs with an Adam optimizer. A linear learning rate decay and a batch size of 2048 are used, all leading to roughly 2.5 days of training. XLNet-Large was not able to leverage the additional data scale, so XLNet-Base (analogous to BERT-Base) was used to conduct a fair comparison with BERT. This also means that only BooksCorpus and English Wikipedia were used for pretraining.
Results
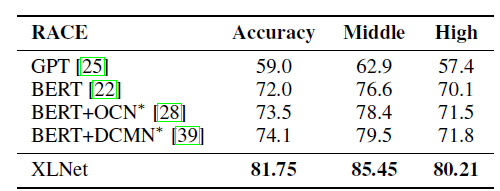
RACE involves a reading comprehension dataset that is used to test the question answering and long text understanding capabilities of the model. As shown in the table below, XLNet outperforms (in terms of accuracy) both GPT and BERT pretraining models.
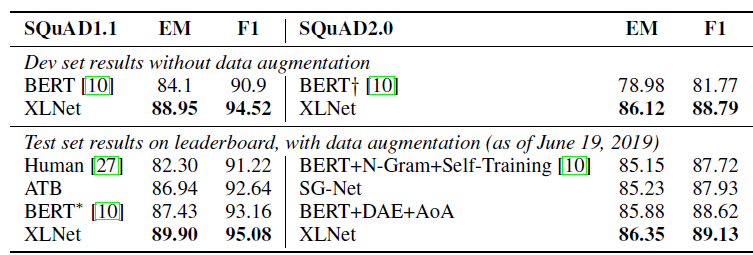
SQuAD and NewsQA are also popular reading comprehension datasets which consist of two tasks. Specifically, XLNet jointly trains on SQuAD 2.0 and NewsQA and obtains state-of-the-art performance on this task, outperforming BERT even on the dev set (see results below).
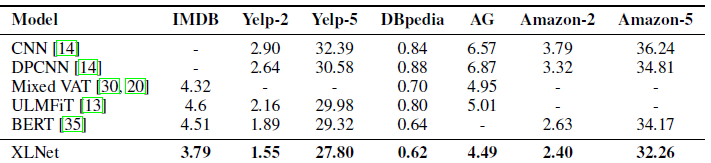
XLNet now holds state-of-the-art (SoTA) results on several text classification benchmarks such as IMDB and DBpedia (see results below).
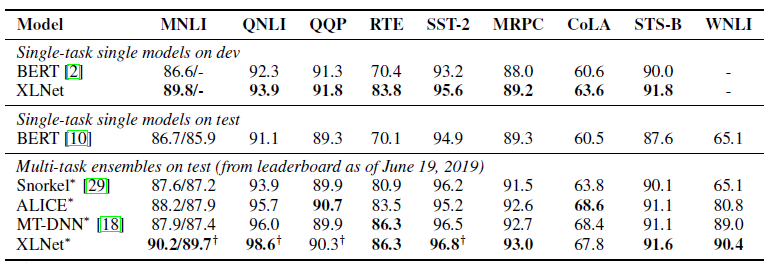
GLUE consists of 9 natural language understanding tasks. Using XLNet, multiple settings such as single-task and multi-task, as well as single models and ensembles are tested on GLUE. In the end, a multi-task ensemble XLNet achieves SoTA results on 7 out of 9 tasks. XLNet outperforms BERT on the different datasets as seen in the table below.
An interesting ablation study and extended results are provided in the paper to justify some of the design choices made in XLNet and how it compares with other models such as BERT and GPT.
XLNet: Generalized Autoregressive Pretraining for Language Understanding — (Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le)
Other suggested readings:
- Deep Learning for NLP: A Complete Overview
- A Light Introduction to Transfer Learning for NLP
- Adapters: A Compact and Extensible Transfer Learning Method for NLP
- A Light Introduction to Transformer-XL
Bio: Elvis Saravia is a researcher and science communicator in Affective Computing and NLP.
Original. Reposted with permission.
Related:
- Spark NLP: Getting Started With The World’s Most Widely Used NLP Library In The Enterprise
- Examining the Transformer Architecture: The OpenAI GPT-2 Controversy
- Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters