Data Quality Assessment Is Not All Roses. What Challenges Should You Be Aware Of?
Of all data quality characteristics, we consider consistency and accuracy to be the most difficult ones to measure. Here, we describe the challenges that you may encounter and the ways to overcome them.
By Alex Bekker, Head of Data Analytics, ScienceSoft
Determined to measure the quality of your data? Check out the challenges that you can face.
Data quality can (and must!) be measured. Otherwise, how can you know whether you have high-quality data you can trust completely or low-quality data that can be the source of multiple problems? But data quality measurement is for sure not all roses. For this article, I picked three out of multiple data quality assurance challenges to describe: selecting the approach to measurement, measuring data accuracy, and measuring data consistency. The first one – because this is a fundamental issue, the remaining two – because I find these two data quality characteristics the most difficult ones to measure.
Challenge 1. Choosing the right approach to assessment
There are three approaches to measuring data quality: manual and automated ones, as well as the combination of both. I am personally not a big fan of manual measurements, as they are usually too time- and resource-consuming and, thus, costly. Still, this is not a reason to abandon the whole practice. It has its supporters, too. For example, Harvard Business Review recommends an approach called Friday afternoon measurements to assess and improve data quality. In brief, it’s a practice of having weekly meetings, where managers take the spreadsheet with last 100 data records and mark each as erroneous or not. Then they total the number of error-free records and give a percentage of how good the quality of data is. Personally, I doubt that the sample is good enough as it’s most likely not representative of the whole data set. I’m also quite skeptical about managers who can boast an eagle’s eye to spot all the mistakes.
An alternative is to use automated data measurement tools that rely on the rules and thresholds you set. For example, an ecommerce retailer may decide that if there are two entries in the database where customers’ full names match but their e-mails differ – with 90% probability, it’s the same customer. Based on such rules and thresholds, the tool can take further actions – for example, merge these two data entries.
Real-life projects usually require an intricately designed combination of automated and manual measurements. Let’s take the same rule but change the threshold: if the customers’ full names match but their e-mails differ – with 50% probability, it’s the same customer. The degree of certainty is neither too large nor too small to let the tool make a decision. In such cases, it prompts a data steward for a decision whether these data entries depict one customer.
Challenge 2. Measuring data accuracy: first, find the real-world value
Data accuracy means that data in your database corresponds to reality. However, let’s think for a moment: where can we find a reliable reference to check our values against? If you have hundreds of suppliers and want to verify their companies’ names, it will require too much time to surf the Internet for correct versions. If you doubt that your SKU portfolio is accurate, you won’t be contacting your suppliers to double-check all the details. And one more example to finish it: your customers’ names. It’s difficult to imagine where you can find the references for that one.
Reliable reference sources are hard to find but it doesn’t mean that they are completely unavailable. For example, you can compare your suppliers’ names with the ones featured in company registers. In the case with customer or product names, you can apply machine learning to spot suspicious and potentially erroneous records. This approach allows saving manual efforts and increasing effectiveness dramatically. However, this all doesn’t resolve the challenge of finding the actual real-world values completely. So, when measuring data accuracy, you should find a good balance between the required efforts and the value expected from the action.
Challenge 3. Measuring data consistency: first, try to find inconsistencies
Data consistency means that data in your database doesn’t contain any contradictions. This section is not about simple cases, such as comparing the sum of employees’ records in each department to the overall headcount. Instead, I suggest considering a case that requires more complicated business logic. So, imagine a retailer running both online and brick-and-mortar stores. The retailer wants to measure the consistency of customer account records for both these sales channels.
Each time when shopping online, a customer chooses what personal information to share with the retailer. For instance, they can enter either as a guest, or as a registered user, which means that the retailer is either able to identify their name, or not. A customer can indicate their home address if, for example, they need a delivery, and can skip this field if they don’t, etc. The same is true for brick-and-mortar stores. There, a customer may or may not use their loyalty card. And when they were filling out the questionnaire to get the loyalty card, they may have either filled all the fields, or skipped some.
In this case, it’s not surprising that the retailer ended up with the database that looks as the one below (for simplicity reasons, we narrowed the example down to a customer’s full name and contact information):
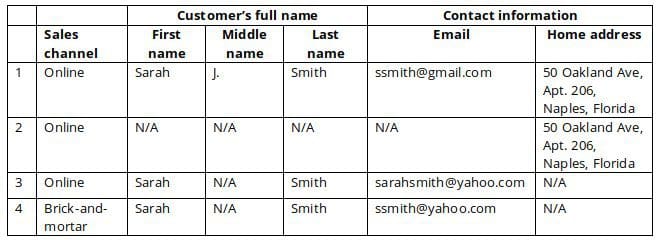
Now, the question: from your point of view, how many individual customers hide behind these four records?
If your answer is somewhere in the range from 1 to 4 inclusive, you may be right! And here is just a couple or multiple possible scenarios to prove this:
- If we have an exact match of home addresses but we don’t know the customer’s name (lines 1 and 2) – it can be the same customer as well as their family members.
- If within one sales channel the customers’ first and last names completely match but their e-mails differ (lines 1 and 3) – it can be either the same customer or namesakes.
- If sales channels are different, the customers’ first and last names completely match but their e-mails differ (lines 1 and 4) – it can be either the same customer or namesakes.
Now, you can see what I meant in the title for this section: to measure the rate of consistency, you should first make sure that the records are indeed inconsistent. What’s more, the result of such action won’t be 100% accurate due to the degree of uncertainty I described for Challenge 1.
That’s all, period; though a comma would be more suitable
Definitely, the challenges of data quality measurement aren’t limited to just these three. I hope that I managed to give you a clue about some pitfalls that you can encounter while trying to manage your data quality successfully and efficiently.
Bio: Alex Bekker is the Head of Data Analytics Department at ScienceSoft, an IT consulting and software development company headquartered in McKinney, Texas. Combining 20+ years of expertise in delivering data analytics solutions with 10+ years in project management, Alex has been leading both business intelligence and big data projects, as well as helping companies embrace the advantages that data science and machine learning can bring. Among his largest projects are: big data analytics revealing media consumption patterns in 10+ countries, private labels product analysis for 18,500+ manufacturers, BI for 200 healthcare centers.
Related:
- Big Data: Promises, Challenges and Threats
- 3 Challenges for Companies Tackling Data Science
- Must-Know: What are common data quality issues for Big Data and how to handle them?