Three Methods of Data Pre-Processing for Text Classification
This blog shows how text data representations can be used to build a classifier to predict a developer’s deep learning framework of choice based on the code that they wrote, via examples of TensorFlow and PyTorch projects.
Check IBM Global Data Science Forum for interesting and useful information about Data Science and related topics
As a developer advocate at IBM, I work to empower AI, machine learning, and deep learning developers to be successful with both open-source tools and those found on IBM Cloud. I also like to better my understanding of AI/ML/DL developers by performing deep learning on them. I recently built a classifier to predict a developer’s deep learning framework of choice based on the code that they wrote, via examples of TensorFlow and PyTorch projects.
In order to pass code examples through a neural network, some transformations had to be performed to get data in a state that a network could use to classify. There were three techniques that were beneficial for me when developing this project, described below.
Bag of Words
Modern neural networks cannot interpret labeled text as described above and data must be pre-processed before it can be given to a network for training. One straightforward way to do this is with a bag of words. A bag of words is created by scanning through every element in a data set and creating a dictionary for each unique word seen that can act as an index. For instance, if ‘Acosta’ is the 1,000th unique word encountered when building a bag of words, every instance of data that has the word ‘Acosta’ in it will have a non-zero value equivalent to the word’s number of appearances in its 1,000th column. This allows a full representation of a data set in a format that a neural network can operate on. However, this can produce quite a large feature vector (in my case 45,818), which will dramatically effect the number of parameters a network has to train on.
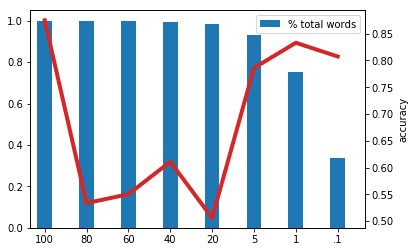
Feature-Vector Length as a Hyperparameter
Keeping each word as a feature in a data set can lead to one that is extremely sparse. Neural networks generally have a harder time optimizing gradients with sparse data and are more likely to over- or under-fit a training set. Many data sets comprised of text, including the one reference in this post, closely resemble Zipf’s law of distribution, meaning the least frequently referenced words may often only occur one time within a dataset, and can be discarded to provide a dataset that is denser. This can be done by sort the bag of words generated in the previous section, but only maintain a portion of the most frequently used words. How many words to keep, like the number of layers in a network or number of nodes with a layer, becomes a hyperparameter of the network. Luckily, there are now ways to automatically perform a hyperparameter optimization process.
Embeddings
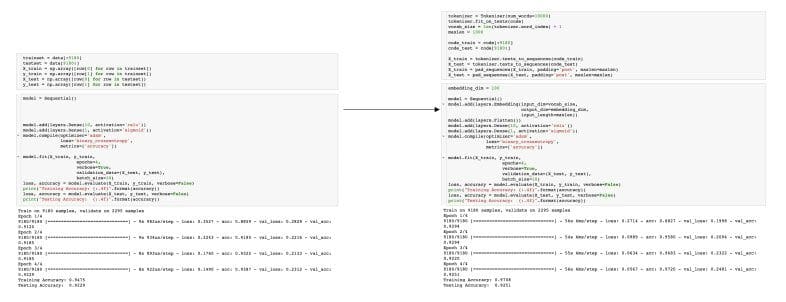
There is a tradeoff in the first two methods described above between having a full representation of the data via one-hot encoding or having a dense data set by limiting the length of the feature vector. The benefits of both can be had via word embeddings. With respect to this project, embeddings refer the ability to translate data from a real space into an embedded space that is both more dense and trainable. Keras provides a nice API to easily add a word embedding as a first layer in a network via its layers library, an example of how to use it is illustrated below. Like in the previous example, the resulting length of the embedded space is a hyperparameter to be set or found via optimization.
Want to get started?
If you would like to try the concepts described here, I will be presenting this material, as well as model building, serving, and deep learning framework selection at ODSC Europe in London this November at the workshop “Choosing The Right Deep Learning Framework: A Deep Learning Approach,” and writing about it on the IBM Data Science Community.
Bio: Before becoming a Developer Advocate at IBM, Nick Acosta studied computer science at Purdue University and the University of Southern California, and was a high performance computing consultant for Hewlett-Packard in Grenoble, France. He now specializes in machine learning and interacting with other data scientists of various communities, startups, and enterprises in order to help them succeed with open source and on IBM’s data science platform. His current areas of focus involve the utilization of machine learning to better understand how machine learning developers write code and solve problems as well as all things Kardashian.