Uber Unveils a New Service for Backtesting Machine Learning Models at Scale
The transportation giant built a new service and architecture for backtesting forecasting models.

Backtesting is an incredibly important aspect of the lifecycle of machine learning models. Any organization running multiple prediction models needs a mechanism to regularly evaluate it effectiveness and recover from errors. The relevance of backtesting scales exponentially with the number of machine learning models used in a given environment. Despite its importance, backtesting remains relatively ignored compared to other aspects of the machine learning lifecycle such as model training or deployment. Recently, Uber unveiled a new service completely built from the ground up to backtest machine learning models at scale.
Uber runs one of the largest machine learning infrastructures in the world. Across its several properties, Uber runs thousands of forecast models across diverse areas such as ride planning or budget management. Ensuring the accuracy of those forecast models is far from being an easy endeavor. The number of models and the scale of computation makes Uber’s environment relatively impractical for most backtesting frameworks. Even Uber itself have built previous backtesting frameworks such as Omphalos which proven to be effective for some specific use cases but unable to scale with Uber’s operation.
What level of scale are we talking about? To put things in context, Uber’s required to orchestrate around 10 million backtests across its different forecast models. In addition to the scale, Uber’s operation have different particularities when comes to backtesting that ended up tipping the scale in favor of building a customer backtesting service.
Understanding Backtesting the Uber Way
Not al backtests are created equal. Different organizations rely on different vectors to backtest models that reflect the domain-specific nature of their business. In the case of Uber, the transportation giant needed to consider elements such as the number of cities or the testing window in order to back test models efficiently. Models that work well for one city didn’t necessary perform well for another. Similarly, some models needed to be backtested real time while others can afford larger windows. All things considered, Uber identified four key vectors that were relevant in order to backtest forecast models.
- Number of backtesting windows
- Number of cities
- Number of model parameters
- Number of forecast models
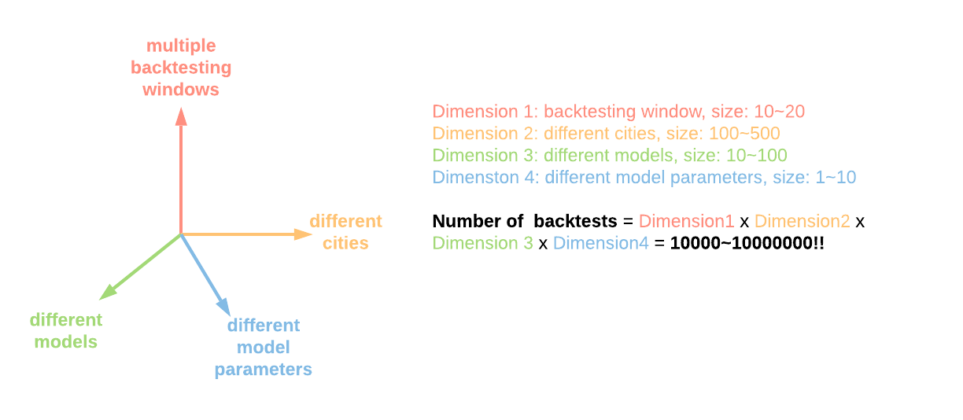
The combination of the four vectors resulted in a scale that was unmanageable by most mainstream backtesting services.
One of the key elements of effective backtesting is to determine how to split the test data. Unlike techniques such as cross-validation, backtesting leverages time-series data and non-randomized splits. That also means that any backtesting strategy needs to clearly understand how to split the testing data in a way that adapts to the performance of the model. In the case of Uber, that also needs to be done across thousands of models. To address this challenge, Uber chose to leverage two primary backtesting data split mechanisms, backtesting with an expanding window and backtesting with a sliding window. Each window is split into training data, which is used to train the model, and testing data, which is used to calculate the error rate for the trained model.

The last component of a backtesting strategy is to accurately measure the accuracy of the model. One of the most common metrics is the mean absolute percentage error(MAPE) which can be mathematically modeled as follows:

When comes to model backtesting, the lower the MAPE, the better a forecast model performs. Usually, data scientists rely of the MAPE metric to compare the results of error rate calculation methods used by the same model to ensure they express what actually went wrong with the forecast.
Putting together those three elements: backtesting vectors, backtesting windows and error measure, Uber setup to build a new backtesting service that could streamline forecasting operations across the organization.
Uber’s Backtesting Service
Over the years, Uber has built different proprietary technologies that help to simplify the lifecycle management of machine learning models. The new backtesting service was able to take advantage of that sophisticated infrastructure by leveraging technologies such as Data Science Workbench, Uber’s interactive data analytics and machine learning toolbox, and Michelangelo, Uber’s machine learning platform.
From an architecture standpoint, the new backtesting service consists of a Python library and a service written in Go. The Python library acts like a Python client. Since many machine learning models at Uber are currently written in Python, it was an easy choice to leverage this framework for the backtesting service, which allows users to seamlessly onboard, test, and iterate on their models. The Go service is written as a series of Cadence workflows. Cadence is an open source, orchestration engine written in Go and built by Uber to execute asynchronous long-running business logic in a scalable and resilient way. At a high level, machine learning models are uploaded through Data Science Workbench and backtesting requests on model data are submitted using the Python library that relays the request to the Backtesting Go service. Once an error measurement is calculated, it is either stored in a datastore or immediately put to work by data science teams, who leverage these prediction errors to optimize machine learning models in training.
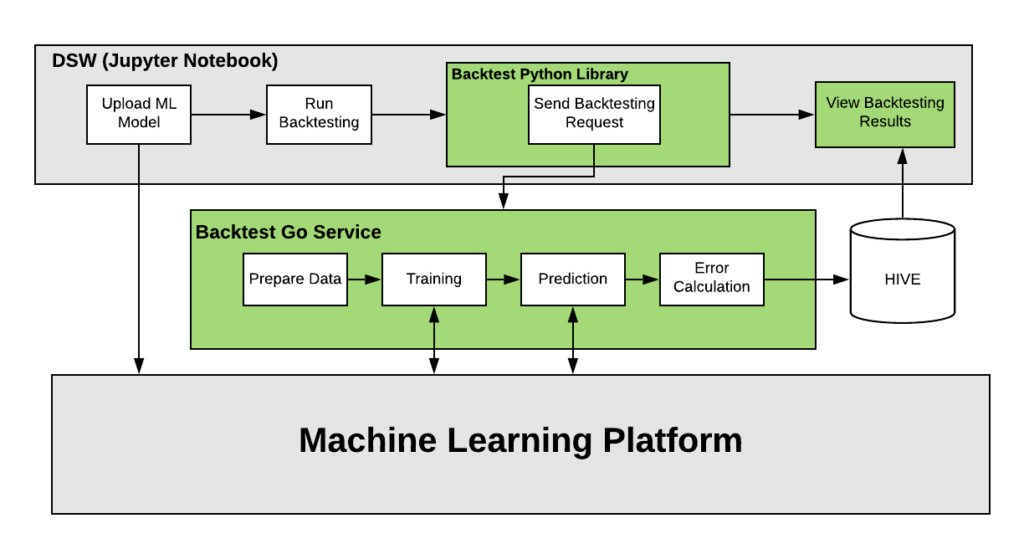
Drilling into the details, the backtesting workflow is composed of four stages. In Stage 1, the model is either written locally in Data Science Workbench (DSW) or uploaded to an machine learning platform, which returns a unique model ID. DSW triggers a backtest through our Go service, which then returns a UUID to DSW. In Stage 2, the Go service fetches training and testing data, stores it in a datastore, and returns a data set. In Stage 3, the backtesting data set is trained on the ML platform and prediction results are generated and returned to the Go service. In Stage 4, the backtesting results are stored in a datastore, to be fetched by users using DSW.

Uber has started to apply the new backtesting service across several use cases such as financial forecasting and budget management. Beyond the initial applicability, the new backtesting service could serve as a reference architecture for many organizations started to apply machine learning models at scale. The principles outlined in the architecture of the backtesting service can be applied across a different number of machine learning frameworks and platforms. It would be interesting to see if Uber decides to open source the backtesting service stack in the near future.
Original. Reposted with permission.
Related:
- Uber Has Been Quietly Assembling One of the Most Impressive Open Source Deep Learning Stacks in the Market
- Uber Creates Generative Teaching Networks to Better Train Deep Neural Networks
- Open Source Projects by Google, Uber and Facebook for Data Science and AI