Some Things Uber Learned from Running Machine Learning at Scale
Uber machine learning runtime Michelangelo has been in operation for a few years. What has the Uber team learned?

Uber has been one of the most active contributors to open source machine learning technologies in the last few years. While companies like Google or Facebook have focused their contributions in new deep learning stacks like TensorFlow, Caffe2 or PyTorch, the Uber engineering team has really focused on tools and best practices for building machine learning at scale in the real world. Technologies such as Michelangelo, Horovod, PyML, Pyro are some of examples of Uber’s contributions to the machine learning ecosystem. With only a small group of companies developing large scale machine learning solutions, the lessons and guidance from Uber becomes even more valuable for machine learning practitioners (I certainly learned a lot and have regularly written about Uber’s efforts).
Recently, the Uber engineering team published an evaluation of the first three years of operations of the Michelangelo platform. If we remove all the Michelangelo specifics, Uber’s post contains a few non-obvious, valuable lessons for organizations starting in their machine learning journey. I am going to try to summarize some of those key takeaways in a more generic way that can be applicable to any mainstream machine learning scenario.
What is Michelangelo?
Michelangelo is the center piece of the Uber machine learning stack. Conceptually, Michelangelo can be seen as a ML-as-a-Service platform for internal ML workloads at Uber. From the functional standpoint, Michelangelo automates different aspects of the lifecycle of ML models allowing different Uber’s engineering teams to build, deploy, monitor and operate ML models at scale. Specifically, Michelangelo abstracts the lifecycle of a ML models in a very sophisticated workflow:
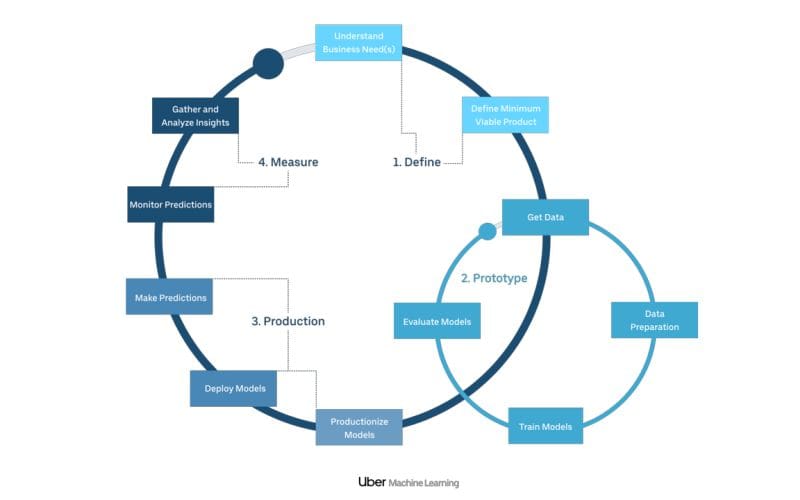
The architecture behind Michelangelo uses a modern but complex stack based on technologies such as HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow.
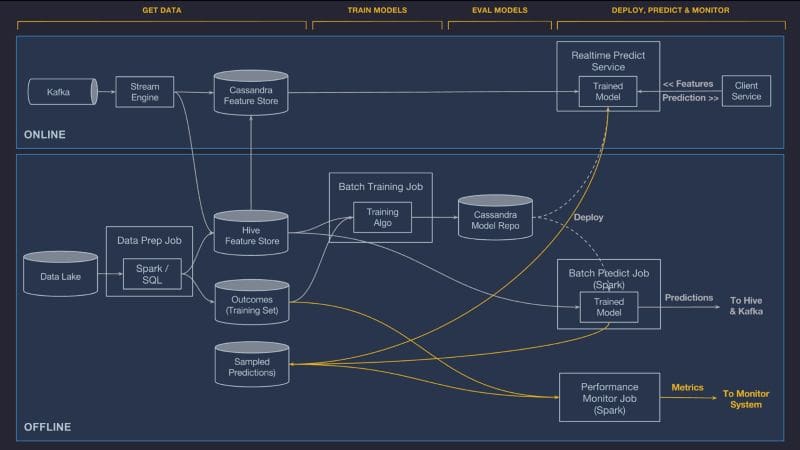
Michelangelo powers hundreds of machine learning scenarios across different divisions at Uber. For instance, Uber Eats uses machine learning models running on Michelangelo to rank restaurant recommendations. Similarly, the incredibly exact estimated time of arrivals(ETA) in the Uber app are calculated using incredibly sophisticated machine learning models running on Michelangelo that estimate ETAs segment-by-segment.
To enable this level of scalability across dozens of data science teams and hundreds of models, Michelangelo needs to provide a very flexible and scalable architecture as well as the corresponding engineering process. The first version of Michelangelo was deployed in 2015 and three years and hundreds of machine learning models later, there are a few important lessons Uber has learned.
1-Training Requires its Own Infrastructure
If you are building a single model, you are tempted to leverage the same infrastructure and tooling for training and development. If you are building a hundred models, that approach doesn’t work. Uber’s Michelangelo, uses a proprietary toolset called the Data Science Workbench(DSW) to train models across large GPU clusters and different machine learning toolkits. Beyond the consistent infrastructure, Michelangelo’s DSW abstracts common tasks of machine learning training processes such as data transformation, model composition, etc.
2-Models Need to be Monitored
Paraphrasing one of my mentors in this space “models that make stupid predictions are worse than models than don’t predict at all”. Even models that performed impeccably against training and evaluation data can start making dumb predictions when faced with new datasets. From that perspective, model monitoring and instrumentation is a key component of real world machine learning solutions. Uber Michelangelo configures machine learning models to log predictions made in production and then compare them against actuals. This process produces a series of accuracy metrics that can be used to evaluate the performance of the models.
3-Data is the Hardest Thing to Get Right
In machine learning solutions, data engineers spend a considerable percentage of their time running extraction and transformation routines over datasets to select features that are then used by training and production models. Michelangelo approach to streamline this process was to build a common feature store that allow different teams to share high quality features across their models. Similarly, Michelangelo provides monitoring tools to evaluate specific features over time.
4-Machine Learning Should be Measured as a Software Engineering Process
I know it sounds trivial but it’s far from it. Most organizations, orchestrated their machine learning efforts separated from other software engineering tasks. It is true that is hard to adapt traditional agile or waterfall processes to machine learning solutions but there are plenty of software engineering practices that are relevant in the machine learning world. Uber enforces the view that machine learning is a software engineering process and has provisioned Michelangelo with a series of tools to enforce the correct lifecycle of machine learning models.
Versioning, testing or deployment are some of the software engineering aspects that are rigorously enforced by Uber’s Michelangelo. For instance, once Michelangelo recognizes that a model is like a compiled software library, it keeps track of the model’s training configuration in a rigorous, version-controlled system in the same way that you version control the library’s source code. Similarly, Michelangelo runs comprehensive test suites evaluates models against holdout datasets before they are deployed to production trying to validate their correct functioning.
5-Automating Optimization
Fine tuning and optimizing hyperparameters is a never-ending task in machine learning solutions. Many times, data science engineers spend more time finding the right hyperparameter configuration than building the model itself. To address this challenge, Uber’s Michelangelo introduced an optimization-as-a-service tool called AutoTune which uses state-of-the-art black box Bayesian optimization algorithms to more efficiently search for an optimal set of hyperparameters. The idea of Michelangelo’s AutoTune is to use machine learning to optimize machine learning models allowing data science engineers to focus more time in the implementation of the models instead of their optimization.
From a machine learning perspective, Uber can be considered one of the richest lab environments in the world. The scale and sophistication of the tasks tackled by Uber’s data scientists is second to none in the industry. The first three years of operation of Michelangelo have certainly showed that implementing large-scale machine learning solutions is still an incredibly complicated effort. The lessons learned from Michelangelo are an incredible source of insights for organization embarking in their machine learning journey.
Original. Reposted with permission.
Related:
- Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning
- Learning by Forgetting: Deep Neural Networks and the Jennifer Aniston Neuron
- Google Unveils TAPAS, a BERT-Based Neural Network for Querying Tables Using Natural Language