Similarity Search: Euclid of Alexandria goes shoe shopping
Many applications can be improved with similarity search. Similarity search can provide more relevant results and therefore improve business outcomes such as conversion rates, engagement rates, detected threats, data quality, and customer satisfaction.
Rajat Tripathi, ML Solutions Engineer, Pinecone
Finding similar items based on fixed criteria is easy with query languages when dealing with traditional databases. But what if we don’t want to use fixed criteria, and instead show results based on the semantic meaning of a query?
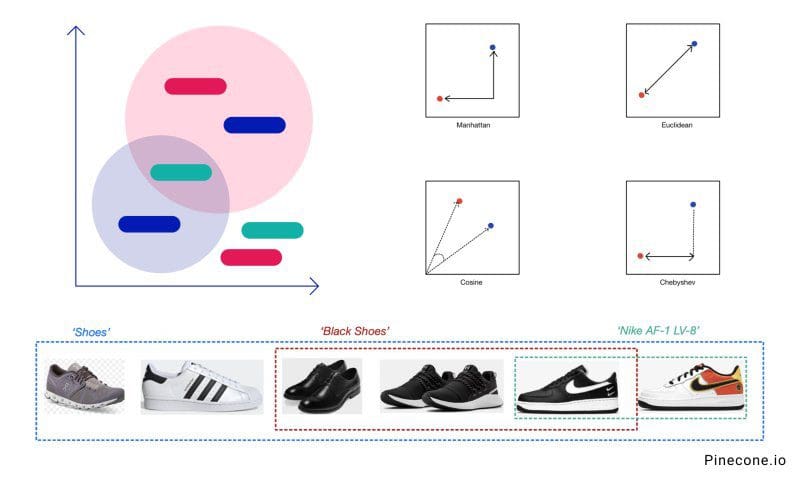
For example, if you want to search through inventory using vague terms like “shoes” and “black shoes,” or something precise like "Nike AF-1."
Our system must discern between these terms and understand how a black shoe differs from other shoes. It needs to search through something more meaningful than tabular data about those items.
In machine learning, we often represent objects as vector embeddings. This lets us translate similarity between objects (eg, images, text, audio) into a vector space. In this space, the proximity between objects reflects how similar they are to one another. Hence, we can find similar items by measuring the distance between vectors.
The common distance metrics include Euclidean, Manhattan, Cosine, and Chebyshev. The best choice depends on the use case, and experimentation is recommended.
This is where similarity search comes in. It’s the action of searching through vector embeddings to find similar items to that of the query vector.
At the core of any similarity search solution is an approximate nearest neighbor (ANN) algorithm to measure the distance between items and retrieve the closest ones.
ANN is a slightly less accurate but much faster version of K-nearest-neighbors (k-NN). Instead of calculating the distance between each vector pair, which is very inefficient, it retrieves a “good guess” of the nearest neighbor. It exchanges some accuracy in favor of a performance boost, making this feasible for applications with huge catalogs and low latency requirements.
In short, ANN algorithms achieve better efficiency with techniques like indexing, clustering, hashing, and quantization to significantly improve computation and storage at the cost of some loss of accuracy. There are many variations of ANN, and each of those requires tuning for optimal performance for a given use case.
Many applications can be improved with similarity search. Recommendation systems, search and analysis tools for unstructured data, anomaly detectors, social media feed ranking, and data management products are just a few examples. Similarity search can provide more relevant results and therefore improve business outcomes such as conversion rates, engagement rates, detected threats, data quality, and customer satisfaction.
Similarity search is more than an algorithm, however. Running ANN in production requires data pipelines, frequent updating of the index, a distributed infrastructure to complete the indexing and search tasks quickly, and many operational components to keep the system reliable and highly available.
This isn’t easy. It’s why large companies with immense engineering resources already implemented similarity search into their applications while many others have not, despite the availability of ANN algorithms.
It doesn’t have to be hard. Our goal at Pinecone is to make similarity search as easy as making an API call, so everyone can build better applications regardless of their size.
This is an excerpt from Pinecone.io. Read the full post.