How to Create Unbiased Machine Learning Models
In this post we discuss the concepts of bias and fairness in the Machine Learning world, and show how ML biases often reflect existing biases in society. Additionally, We discuss various methods for testing and enforcing fairness in ML models.
By Philip Tannor, Co-Founder & CEO of Deepchecks.

Image by Clker-Free-Vector-Images from Pixabay
AI systems are becoming increasingly popular and central in many industries. They decide who might get a loan from the bank, whether an individual should be convicted, and we may even entrust them with our lives when using systems such as autonomous vehicles in the near future. Thus, there is a growing need for mechanisms to harness and control these systems so that we may ensure that they behave as desired.
One important issue that has been gaining popularity in the last few years is fairness. While usually ML models are evaluated based on metrics such as accuracy, the idea of fairness is that we must ensure that our models are unbiased with regard to attributes such as gender, race and other selected attributes.
A classic example of an episode regarding racial bias in AI systems, is the COMPAS software system, developed by Northpointe, which aims to assist US courts with assessing the likelihood of a defendant becoming a recidivist. Propublica published an article which claims that this system is biased against blacks, giving them higher risk ratings.

ML system bias against African Americans? (source)
In this post we will try to understand where biases in ML models originate, and explore methods for creating unbiased models.
Where Does Bias Come From?
"Humans are the weakest link"
—Bruce Schneier
In the field of Cybersecurity it is often said that “humans are the weakest link” (Schneier). This idea applies in our case as well. Biases are in fact introduced into ML models by humans unintentionally.
Remember, an ML model can only be as good as the data it’s trained on, and thus if the training data contains biases, we can expect our model to mimic those same biases. Some representative examples for this can be found in the field of word embeddings in NLP. Word embeddings are learned dense vector representations of words, that are meant to capture semantic information of a word, which can then be fed to ML models for different downstream tasks. Thus, embeddings of words with similar meanings are expected to be “close” to each other.
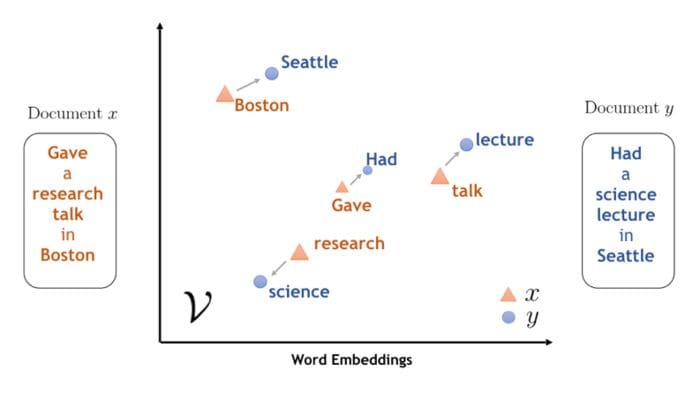
Word embeddings can capture the semantic meaning of words. (source)
It turns out that the embedded space can be used to extract relations between words, and to find analogies as well. A classic example for this is the well known king-man+woman=queen equation. However, if we substitute the word “doctor” for the word “king” we get “nurse” as the female equivalent of the “doctor”. This undesired result simply reflects existing gender biases in our society and history. If in most available texts doctors are generally male and nurses are generally female, that’s what our model will understand.
doctor = nlp.vocab['doctor'] man = nlp.vocab['man'] woman = nlp.vocab['woman'] result = doctor.vector - man.vector + woman.vector print(most_similar(result)) Output: nurse
Culture Specific Tendencies
Currently, the most used language on the internet is English. Much of the research and products in the field of Data Science and ML is done in English as well. Thus, many of the “natural” datasets that are used to create huge language models tend to match American thought and culture, and may be biased towards other nationalities and cultures.

Cultural bias: GPT-2 needs active steering in order to produce a positive paragraph with the given prompt. (source)
Synthetic Datasets
Some biases in the data may be created unintentionally in the process of the dataset’s construction. During construction and evaluation people are more likely to notice and pay attention to details they are familiar with. A well known example for an image classification mistake, is when Google Photos misclassified black people as gorillas. While a single misclassification of this sort may not have a strong impact on the overall evaluation metrics, it is a sensitive issue, and could have a large impact on the product and the way customers relate to it.
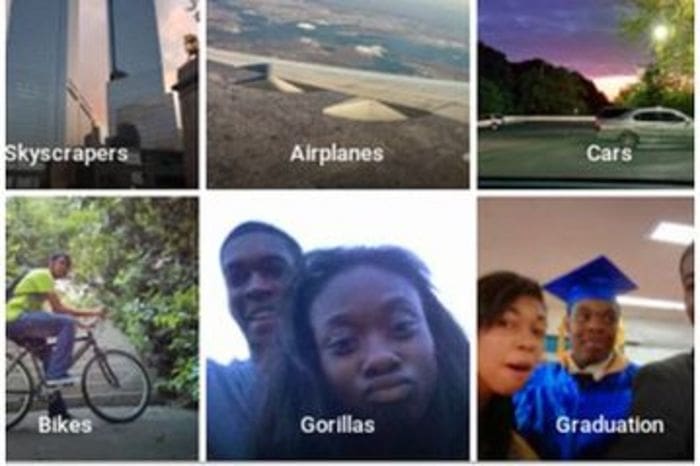
Racist AI algorithm? Misclassification of black people as gorillas. (source)
In conclusion, no dataset is perfect. Whether a dataset is handcrafted or “natural”, it is likely to reflect the biases of it’s creators, and thus the resulting model will contain the same biases as well.
Creating fair ML models
There are multiple proposed methods for creating fair ML models, which generally fall into one of the following stages.
Preprocessing
A naive approach to creating ML models that are unbiased with respect to sensitive attributes is to simply remove these attributes from the data, so that the model cannot use them for its prediction. However, it is not always straightforward to divide attributes into clear cut categories. For example, a person’s name may be correlated with their gender or ethnicity, nevertheless we would not necessarily want to regard this attribute as sensitive. More sophisticated approaches attempt to use dimensionality reduction techniques in order to eliminate sensitive attributes.
At Training Time
An elegant method for creating unbiased ML models is using adversarial debiasing. In this method we simultaneously train two models. The adversary model is trained to predict the protected attributes given the predictors prediction or hidden representation. The predictor is trained to succeed on the original task while making the adversary fail, thus minimizing the bias.
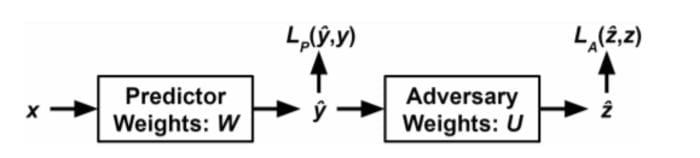
Adversarial debiasing illustration: The predictor loss function consists of two terms, the predictor loss, and the adversarial loss. (source)
This method can achieve great results for debiasing models without having to “throw away” the input data, however, it may suffer from difficulties that arise in general when training adversarial networks.
Post Processing
In the post processing stage we get the model’s predictions as probabilities, but we can still choose how to act based on these outputs, for example we can move the decision threshold for different groups in order to meet our fairness requirements.
One way to ensure model fairness in the post processing stage is to look at the intersection of the area under the ROC curve for all groups. The intersection represents TPRs and FPRs that can be achieved for all classes simultaneously. Note that in order to satisfy the desired result of equal TPRs and FPRs for all classes one might need to purposefully choose to get less good results on some of the classes.
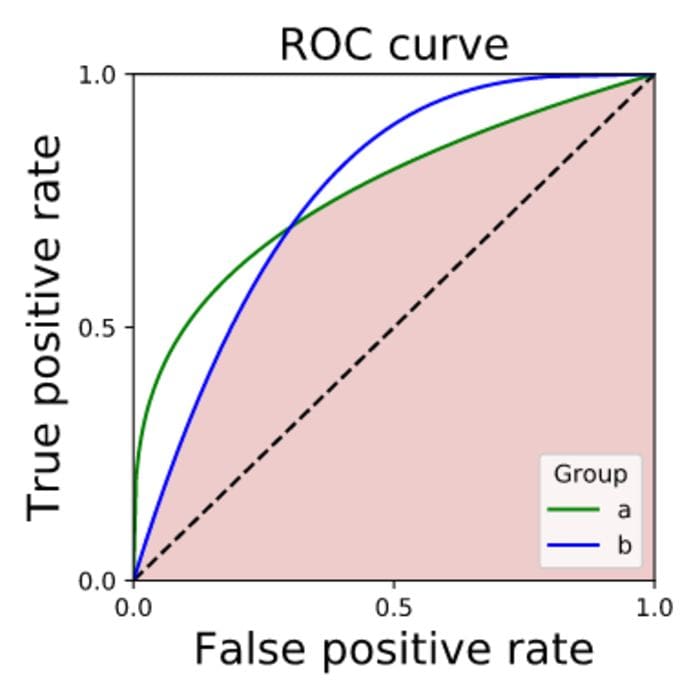
The colored region is what’s achievable while fulfilling the separability criterion for fairness. (source)
Another method for debiasing a model in the post processing stage involves calibrating the predictions for each class independently. Calibration is a method for ensuring that the probability outputs of a classification model indeed reflect the matching ratio of positive labels. Formally, a classification model is calibrated if for each value of r:

When a model is properly calibrated error rates will be similar across the different values of protected attributes.
Conclusion
To sum it up, we have discussed the concepts of bias and fairness in the ML world, we have seen that model biases often reflect existing biases in society. There are various ways in which we could enforce and test for fairness in our models, and hopefully, using these methods will lead to more just decision making in AI assisted systems around the world.
Further Reading
Gender bias in word embeddings
Alekh Agarwal, Alina Beygelzimer, Miroslav Dudík, John Langford, & Hanna Wallach. (2018). A Reductions Approach to Fair Classification.
Brian Hu Zhang, Blake Lemoine, & Margaret Mitchell. (2018). Mitigating Unwanted Biases with Adversarial Learning.
Solon Barocas, Moritz Hardt, & Arvind Narayanan (2019). Fairness and Machine Learning. fairmlbook.org.
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, & Aram Galstyan. (2019). A Survey on Bias and Fairness in Machine Learning.
Bio: Philip Tannor is Co-Founder & CEO of Deepchecks.
Related:
- Data Protection Techniques Needed to Guarantee Privacy
- What Makes AI Trustworthy?
- Ethics, Fairness, and Bias in AI