High-Performance Deep Learning: How to train smaller, faster, and better models – Part 5
Training efficient deep learning models with any software tool is nothing without an infrastructure of robust and performant compute power. Here, current software and hardware ecosystems are reviewed that you might consider in your development when the highest performance possible is needed.

In the previous parts (Part 1, Part 2, Part 3, Part 4), we discussed why efficiency is important for deep learning models to achieve high-performance models that are pareto-optimal, as well as the focus areas for efficiency in Deep Learning. We also covered four of the focus areas (Compression Techniques, Learning Techniques, Automation, and Efficient Architectures). Let us finish this series with the final section on the foundational Infrastructure that is critical to training and deploying high-performance models.
As a side note, you are also welcome to go through our survey paper on efficiency in deep learning, which covers this topic in further detail.
Infrastructure
In order to be able to train and run inference efficiently, there has to be a robust software and hardware infrastructure foundation. In this section, we go over both these aspects.
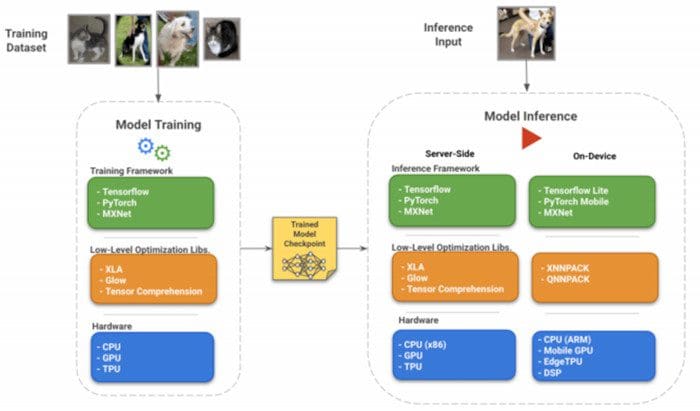
A mental model of the software and hardware infrastructure, and how they interact with each other.
Tensorflow Ecosystem:
Tensorflow (TF) [1] is a popular machine learning framework that has been used in production by many large enterprises. It has some of the most extensive software support for model efficiency.
Tensorflow Lite for On-Device Use Cases: Tensorflow Lite (TFLite) [2] is a collection of tools and libraries designed for inference in low-resource environments such as edge devices. At a high level, we can break down the TFLite into two core parts:
- Interpreter and Op Kernels: TFLite provides an interpreter for running specialized TFLite models, along with implementations of common neural net operations (Fully Connected, Convolution, Max Pooling, ReLu, Softmax, etc. each of which as an Op). The interpreter and operations are primarily optimized for inference on ARM-based processors as of the time of writing this post. They can also leverage smartphone DSPs such as Qualcomm’s Hexagon [3] for faster execution.
- Converter: This is a tool for converting the given TF model into a single file for inference by the interpreter. Apart from the conversion itself, it handles a lot of internal details like getting a graph ready for quantized inference (as mentioned in earlier posts), fusing operations, adding other metadata to the model, etc.
Other Tools for On-Device Inference: Similarly, there are tools for inference on other platforms as well. For example, TF Micro [4] has a slimmed-down interpreter and a smaller set of ops for inference on very low resource microcontrollers like DSPs. TensorflowJS (TF.JS) [5] is a library within the TF ecosystem that can be used to train and run neural networks within the browser or using Node.js. These models can also be accelerated through GPUs via the WebGL interface [6]. It supports both importing models trained in TF as well as creating new models from scratch in TF.JS. There is also the TF Model Optimization Toolkit [7], which offers adding quantization, sparsity, weight-clustering etc. in a model graph.
XLA for Server-Side Acceleration: XLA (Accelerated Linear Algebra) [8] is a graph compiler that can optimize linear algebra computations in a model by generating new implementations for operations (kernels) that are customized for the graph. For example, certain operations which can be fused together are combined in a single composite op. This avoids having to do multiple costly writes to RAM when the operands can directly be operated on while they are still in the cache. Kanwar et al. [9] report a 7× increase in training throughput and a 5× increase in the maximum batch size that can be used for BERT training using XLA. This allows training a BERT model for $32 on Google Cloud.
PyTorch Ecosystem:
PyTorch [10] is another popular machine-learning platform actively used by both academia and industry, and it can be compared to Tensorflow in terms of usability and features.
On-Device Usecases: PyTorch also has a lightweight interpreter that enables running PyTorch models on Mobile [11], with native runtimes for Android and iOS (analogous to TFLite interpreter). PyTorch also offers post-training quantization [12] and other graph optimization steps such as constant folding, fusing certain operations together, putting the channels last (NHWC) format for optimizing convolutional layers.
General Model Optimization: PyTorch also offers the Just-in-Time (JIT) compilation facility [13] for generating a serializable intermediate representation of the model from the code in TorchScript [14], which is a subset of Python and adds features like type-checks. It allows creating a bridge between the flexible PyTorch code for research and development to a representation that can be deployed for inference in production. It is the primary way PyTorch models are executed on mobile devices.
The alternatives for XLA in the PyTorch world seem to be the Glow [15] and TensorComprehension [16] compilers. They help in generating the lower-level intermediate representation (IR) that is derived from the higher-level IR like TorchScript.
PyTorch also offers a model tuning guide [17] which details various options that ML practitioners have at their disposal. Some of the core ideas in there are:
- Fusion of pointwise operations (add, subtract, multiply, divide, etc.) using PyTorch JIT.
- Enabling buffer checkpointing allows keeping the outputs of only certain layers in memory and computing the rest during the backward pass. This specifically helps with cheap to compute layers with large outputs like activations.
- Enabling device-specific optimizations, such as the cuDNN library and Mixed Precision Training with NVIDIA GPUs (explained in the GPU subsection).
- Train with Distributed Data Parallel Training, which is suitable when there is a large amount of data, and multiple GPUs are available for training.
Hardware-Optimized Libraries:
We can further extract efficiency by optimizing our software stack for the hardware the neural networks run on. As an example, ARM’s Cortex-family of processors support SIMD (Single-Instruction Multiple Data) instructions which allow vectorization of operation (working with batches of data) using the Neon instruction set. QNNPACK [18] and XNNPACK [19] libraries are optimized for ARM Neon for mobile and embedded devices and for x86 SSE2, AVX architectures, etc. The former is used for quantized inference mode for PyTorch, and the latter supports 32-bit floating-point models and 16-bit floating-point for TFLite. Similarly, there are other low-level libraries like Accelerate for iOS [20] and NNAPI for Android [21] that try to abstract away the hardware-level acceleration decision from higher-level ML frameworks.
Hardware
GPU: Graphics Processing Units (GPUs), while originally designed for accelerating computer graphics, began to be used for general-purpose use cases with the availability of the CUDA library [22] in 2007. AlexNet’s [23] winning the ImageNet competition in 2012 standardized the use of GPUs for deep learning models. Since then, Nvidia has released several iterations of its GPU microarchitectures with an increasing focus on deep learning performance. It has also introduced Tensor Cores [24], which are dedicated execution units and support training and inference in a range of precisions (fp32, TensorFloat32, fp16, bfloat16, int8, int4).
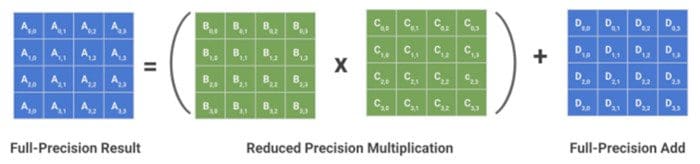
Reduced Precision Multiply-and-Accumulate (MAC) operation: B x C is an expensive operation, and hence it is done with reduced precision.
Tensor Cores optimize the standard Multiply-and-Accumulate (MAC) operation, A = (B × C) + D. Where, B and C are in a reduced precision (fp16, bfloat16, TensorFloat32), while A and D are in fp32. NVIDIA reports between 1× to 15× training speedup with this reduced precision MAC operations, depending on the model architecture and the GPU chosen [25]. Tensor Cores in NVidia’s latest Ampere architecture GPUs also support faster inference with sparsity (specifically, structured sparsity in the ratio 2:4, where 2 elements out of a block of 4 elements are sparse). They demonstrate an up to 1.5× speed up in inference time and up to 1.8× speedup in individual layers. Apart from this, NVidia also offers the cuDNN library [29] that contains optimized versions of standard neural network operations such as fully connected, convolution, batch-norm, activation, etc.

Data types used during training and inference on GPUs and TPUs. bfloat16 originated with TPUs, and Tensor Float 32 is supported on NVidia GPUs only.
TPU: TPUs are proprietary application-specific integrated circuits (ASICs) that Google designed to accelerate deep learning applications with Tensorflow and finely tuned for parallelizing and accelerating linear algebra operations. TPU architectures support both training and inference with TPUs and are available to the general public via their Google Cloud service. The core architecture of the TPU chips leverages the Systolic Array design [26], where a large computation is split across a mesh-like topology, where each cell computes a partial result and passes it on to the next cell in the order, every clock-step (in a rhythmic manner analogous to the systolic cardiac rhythm), without the need to store intermediate results in memory.
Each TPU chip has two Tensor Cores (not to be confused with NVidia’s Tensor Cores), each of which has a mesh of systolic arrays. There are 4 inter-connected TPU chips on a single TPU board. To further scale training and inference, a larger number of TPU boards can be connected in a mesh topology to form a ‘pod’. As per publicly released numbers, each TPU chip (v3) can achieve 420 teraflops, and a TPU pod can reach 100+ petaflops [27]. TPUs have been used inside Google for applications like training models for Google Search, general-purpose BERT models, applications like DeepMind’s world-beating AlphaGo and AlphaZero models, and many other research applications [28]. Similar to the GPUs, TPUs support the bfloat16 data type, which is a reduced-precision alternative to training in full floating-point 32-bit precision. XLA support allows transparently switching to bfloat16 without any model changes.
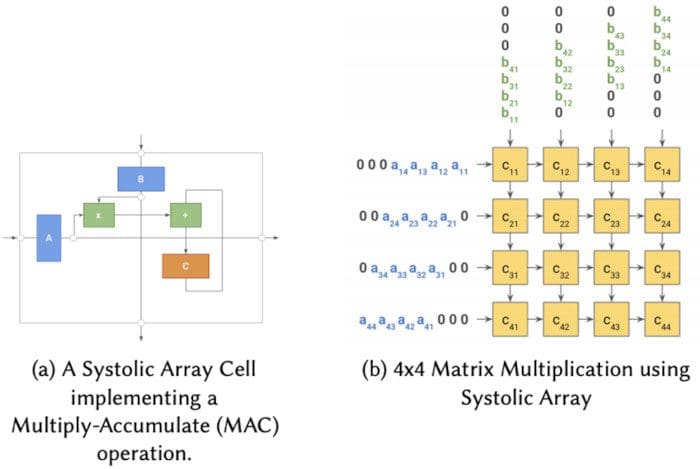
An illustration of a basic systolic array cell, and doing a 4x4 matrix multiplication using a mesh of systolic array cells.

Approximate size of the EdgeTPU, Coral, and the Dev Board. (Courtesy: Bhuwan Chopra)
EdgeTPU: EdgeTPU is also a custom ASIC chip designed by Google. Similar to the TPU, it is specialized for accelerating linear algebra operations, but only for inference and with a much lower compute budget on edge devices. It is further limited to only a subset of operations and works only with int8 quantized Tensorflow Lite models. The EdgeTPU chip itself is smaller than a US penny, making it amenable for deployment in many kinds of IoT devices. It has been deployed in Raspberry-Pi-like dev boards, in Pixel 4 smartphones as Pixel Neural Core, and can also be independently soldered onto a PCB.

Jetson Nano module. (Source)
Jetson: Jetson is a family of accelerators by Nvidia to enable deep learning applications for embedded and IoT devices. It comprises the Nano, which is a low-powered "system on a module" (SoM) designed for lightweight deployments, as well as the more powerful Xavier and TX variants, which are based on the NVidia Volta and Pascal GPU architectures. The Nano is suited for applications like home automation and the rest for more compute-intensive applications like industrial robotics.
Summary
In this series, we started by demonstrating the rapid growth of models in the Deep Learning space and motivating the need for efficiency and performance as we continue to scale them up. We followed that up by laying a mental model for the readers to understand the vast landscape of tools and techniques that they can use. We then went deeper into each of the focus areas to offer detailed examples and further illustrated the work done in industry and academia so far. We hope that this series of blog posts will hopefully give concrete and actionable takeaways, as well as tradeoffs for the reader to think about when optimizing a model for training and deployment. We invite the readers to go through our more detailed survey paper on model optimization and efficiency for further insights.
References
[1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 2016. Tensorflow: A system for large-scale machine learning. In 12th {USENIX} symposium on operating systems design and implementation ({OSDI} 16). 265–283.
[2] Tensorflow Authors. 2021. TensorFlow Lite | ML for Mobile and Edge Devices. https://www.tensorflow.org/lite [Online; accessed 3. Jun. 2021].
[3] XNNPACK Authors. 2021. XNNPACK backend for TensorFlow Lite. https://github.com/tensorflow/tensorflow/blob/ master/tensorflow/lite/delegates/xnnpack/README.md/#sparse-inference.
[4] Pete Warden and Daniel Situnayake. 2019. Tinyml: Machine learning with tensorflow lite on arduino and ultra-low-power microcontrollers. " O’Reilly Media, Inc.".
[5] Tensorflow JS: https://www.tensorflow.org/js
[6] WebGL: https://en.wikipedia.org/wiki/WebGL
[7] TensorFlow. 2019. TensorFlow Model Optimization Toolkit — Post-Training Integer Quantization. Medium (Nov 2019). https://medium.com/tensorflow/tensorflow-model-optimization-toolkit-post-training-integer-quantizationb4964a1ea9ba
[8] Tensorflow Authors. 2021. XLA: Optimizing Compiler for Machine Learning | TensorFlow. https://www.tensorflow. org/xla.
[9] Pankaj Kanwar, Peter Brandt, and Zongwei Zhou. 2021. TensorFlow 2 MLPerf submissions demonstrate best-in-class performance on Google Cloud. https://blog.tensorflow.org/2020/07/tensorflow-2-mlperf-submissions.html.
[10] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703 (2019).
[11] PyTorch Authors. 2021. PyTorch Mobile. https://pytorch.org/mobile/home.
[12] PyTorch Authors. 2021. Quantization Recipe — PyTorch Tutorials 1.8.1+cu102 documentation. https://pytorch.org/ tutorials/recipes/quantization.html.
[13] PyTorch Authors. 2021. torch.jit.script — PyTorch 1.8.1 documentation. https://pytorch.org/docs/stable/generated/ torch.jit.script.html
[14] PyTorch Authors. 2021. torch.jit.script — PyTorch 1.8.1 documentation. https://pytorch.org/docs/stable/generated/ torch.jit.script.html
[15] Nadav Rotem, Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, James Hegeman, Meghan Lele, Roman Levenstein, et al. 2018. Glow: Graph lowering compiler techniques for neural networks. arXiv preprint arXiv:1805.00907 (2018).
[16] Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. 2018. Tensor comprehensions: Framework-agnostic highperformance machine learning abstractions. arXiv preprint arXiv:1802.04730 (2018).
[17] PyTorch Authors. 2021. Performance Tuning Guide — PyTorch Tutorials 1.8.1+cu102 documentation. https: //pytorch.org/tutorials/recipes/recipes/tuning_guide.html
[18] Marat Dukhan, Yiming Wu Wu, and Hao Lu. 2020. QNNPACK: Open source library for optimized mobile deep learning - Facebook Engineering. https://engineering.fb.com/2018/10/29/ml-applications/qnnpack
[19] XNNPACK Authors. 2021. XNNPACK. https://github.com/google/XNNPACK
[20] Apple Authors. 2021. Accelerate | Apple Developer Documentation. https://developer.apple.com/documentation/ accelerate
[21] Android Developers. 2021. Neural Networks API | Android NDK | Android Developers. https://developer.android. com/ndk/guides/neuralnetworks.
[22] Contributors to Wikimedia projects. 2021. CUDA - Wikipedia. https://en.wikipedia.org/w/index.php?title=CUDA& oldid=1025500257.
[23] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25 (2012), 1097–1105.
[24] NVIDIA. 2020. Inside Volta: The World’s Most Advanced Data Center GPU | NVIDIA Developer Blog. https: //developer.nvidia.com/blog/inside-volta.
[25] Dusan Stosic. 2020. Training Neural Networks with Tensor Cores - Dusan Stosic, NVIDIA. https://www.youtube. com/watch?v=jF4-_ZK_tyc
[26] HT Kung and CE Leiserson. 1980. Introduction to VLSI systems. Mead, C. A_, and Conway, L.,(Eds), Addison-Wesley, Reading, MA (1980), 271–292.
[27] Kaz Sato. 2021. What makes TPUs fine-tuned for deep learning? | Google Cloud Blog. https://cloud.google.com/ blog/products/ai-machine-learning/what-makes-tpus-fine-tuned-for-deep-learning
Related: