
 A Learning Path To Becoming a Data Scientist
A Learning Path To Becoming a Data Scientist

 A Learning Path To Becoming a Data Scientist
A Learning Path To Becoming a Data ScientistBecoming a professional data scientist may not be as easy as "1... 2... 3...", but these 10 steps can be your self-learning roadmap to kickstarting your future in the exciting and ever-expanding field of data science.

Image by the author (made using Canva).
Data science is one of the rapidly growing fields that demands that a data scientist grows up daily, and I can’t see this demand slowing down anytime soon. It is an interdisciplinary field that can help us analyze the data around us to make our life better and our future brighter.
Luckily, becoming a data scientist does not require a degree. As long as you are open to learning new things and willing to put in the effort and time, you can become a data scientist.
The question now is, where to start?
“The beginning is perhaps more difficult than anything else, but keep heart, it will turn out all right.”
― Vincent van Gogh
The internet is full of tutorials about all the details of every data science aspect, such as machine learning basics, natural language processing, speech recognition, and all kind of amazing data science magic.
But,
For a beginner, the amount of information can be overwhelming and lead someone to give up before they even start.
What could help is having a structured roadmap that clearly lays out what you need to learn and the order that you should learn to become a data scientist.
In this article, I will lay out a 10-step roadmap from start to finish of concepts you need to cover along your data science learning journey.
Step №1: Programming
If you’re new to the technical field, then programming would be the best place to start. Currently, the two programming languages used most in data science are Python and R.
- R: A programming language for statistical computing. R is widely for developing statistical software and data analysis.
- Python: A high-level, general-purpose programming language. Python is widely used in many applications and fields, from simple programming to quantum computing.
Because Python is a beginner-friendly programming language, I find it a great place to start with data science and maybe more fields in the future. Due to Python's popularity, there are many resources available to learn it independently of your goal application field.
Some of my favorite Python learning resources are CodeAcademy, Google Classes, Learn Python the Hard Way.
However, if you decide to go with R, both Coursera and edX have great courses that you can audit for free.
Some of you might already know how to program and might be transferred to data science from another technical field. In that case, you can skip this step and move forward to the next step of the journey.
Step №2: Databases
The heart of data science is data. You can think of data science as the art of telling a story using data.
Whenever you work on a data science project, you will need to have data to analyze, visualize, and build a valid project. This data are often stored in some database.
An essential step to standing out as a data scientist is to interact and communicate with databases effectively. If you could design a simple database, then this will take you to the next level.
To communicate with a database, you will need to speak its language. That is SQL. SQL stands for Structured Query Language and is used to communicate with a database.
My favorite resources to learn SQL are CodeAcademy, Khan Academy, and interactive learning, SQLCourse.
Step №3: Math
The core of data science is math. To understand how the different concepts of data science function, you need to have a basic understanding of the math behind them.
I know math is one thing that could make some backup from pursuing a career in data science.
But,
You need to understand the basics of probability theory, statistics, and linear algebra to comprehend data science. However, most tools you would use in your career will eliminate implementing the math itself in your projects.
So, you need to understand how it works, how, and when to use it.
Don’t let math intimidate you from exploring the world of data science. I would say it’s well worth it. There are some helpful materials on Coursera that can help you tackle the math you need.
- Data Science Math Skills
- Mathematics for Data Science Specialization
- Data Science is All About Probabilities
- 5 Applications of Linear Algebra In Data Science
Step №4: Version Control
In software development and data science, one of the most important concepts to master — or try to — is version control.
Whenever you work on a data science project, you will need to write different code files, explore datasets, and collaborate with other data scientists. Managing, all changes in the code, is done via version control, namely, using Git.
Git is a version control system used to track changes in source code during the software development process. Git was built to coordinate work among a group of programmers or to be used to track changes in any set of files by a single programmer.
Although Git is a system, some websites allow you to use Git easily without needing to interact much with the command line — you will eventually move to the command line eventually, though — such as GitHub or GitLab.
Luckily, there are many resources to help you understand the inner functionality of Git; my top choices are BitBucket Learn Git Tutorials and this lecture from the Harvard CS50 course.
Step №5: Data Science Basics
Data science is an extensive term, as it includes different concepts and technologies. But before you take a deep dive into the big sea of data science, you need to familiarize yourself with some basics first.
There are important skills you need to develop and work on to become a successful data scientist, for example:
- Finding datasets: there are two ways to kickstart any data science project: you either have a dataset you want to use to build a project, or you have an idea and need to find a dataset for. Exploring datasets and choosing the right one for your project is an important skill to obtain.
- Science communication: as a data scientist, you will need to communicate with a general audience to deliver your process and findings. So, you will need to develop your science communication skills and explain complex concepts using simple terms.
- Effective visualization: the only way to validate your findings is to visualize them. Visualization plays a big role in data science, from exploring your data to delivering your results. Getting familiar with effective visualization of data can save you tons of time and effort during your project.
Step №6: Machine Learning Basics
So, you worked on your programming skills, brushed up your math, and dived into databases. You’re now ready to start the fun part, applying what you learned so far to build your first projects.
Machine learning basics is the place to start. Here is when you start learning and exploring basic machine learning algorithms and techniques, such as linear and logistic regression, decision trees, Naive Bayes, and support vector machines (SVM).
Here where you also start discovering the different Python or R packages to deal with and implement your data. You will get to use Scikit-learn, Scipy, and Numpy.
You will learn how to clean up your data to have more accurate positions and results. This is the part where you’ll get to experience what you can do with data science and will be able to see the impact the field has on our daily lives.
The best place to start learning about the different aspects of machine learning is the various article on Towards Data Science.
Step №7: Time Series and Model Validation
It’s time to dive deeper into machine learning. Your data is not going to be stationary; it’s often related to time somehow. Time series are data points ordered based on time.
Most commonly, time series are sequences of data taken at successive equally spaced points in time. Making them discrete-time data. Time series shows you how time changes your data. This allows you to gain insights about trends, periodicity in the data and predict the data's future behavior.
When dealing with time series, you will need to work on two main parts:
- Analyzing time-series data.
- Forecasting time series data.
Building models to predict future behavior is not enough. You need to validate this model's correctness. Here’s where you will learn how to build and test models efficiently.
Moreover, you will learn how to estimate the threshold of error for each project and how to keep your models within the acceptable ranges.
Step №8: Neural Networks
Neural networks (Artificial Neural Networks or ANN) are a biologically-inspired programming paradigm that enables a computer to learn from observational data.
ANNs started as an approach to mimic the human brain's architecture to perform different learning tasks. For an ANN to resemble the human brain, it was designed to contain the same components a human cell has.
So, ANN contains a collection of neurons, with each representing a node connected to another via links. These links correspond to the biological axon-synapse-dendrite connections. Moreover, each of these links has a weight that determines the strength one node has on another.
Learning ANN enables you to tackle a wider range of tasks, including recognizing handwriting, pattern recognition, and face identification.
ANN represents the basic logic you need to know to proceed to the next step in your data science journey, deep learning.
Step №9: Deep Learning
Neural networks are paradigms that power deep learning. Deep learning represents a powerful set of techniques that harness the learning power of neural networks.
You can use neural networks and deep learning to tackle the best solutions to many problems in various fields, including image recognition, speech recognition, and natural language processing.
By now, you’ll be familiar with many Python packages that deal with different aspects of data science. In this step, you will get the chance to try popular packages such as Keras and TensorFlow.
Also, by this step, you will be able to read recent research advances in data science and maybe develop your own.
Step №10: Natural language Processing
You’re almost at the end. You can already see the finish sign. You have gone through many theoretical and practical concepts so far, from simple math to complex deep learning concepts.
So, what’s next?
My favorite sub-field of data science is natural language processing (NLP). Natural language processing is an exciting branch that enables you to use the power of machine learning to “teach” the computer to understand and process human languages.
This will include speech recognition, text-to-speech application (and vise versa), virtual assistance (like Siri and BERT), and all kinds of different conversational bots.
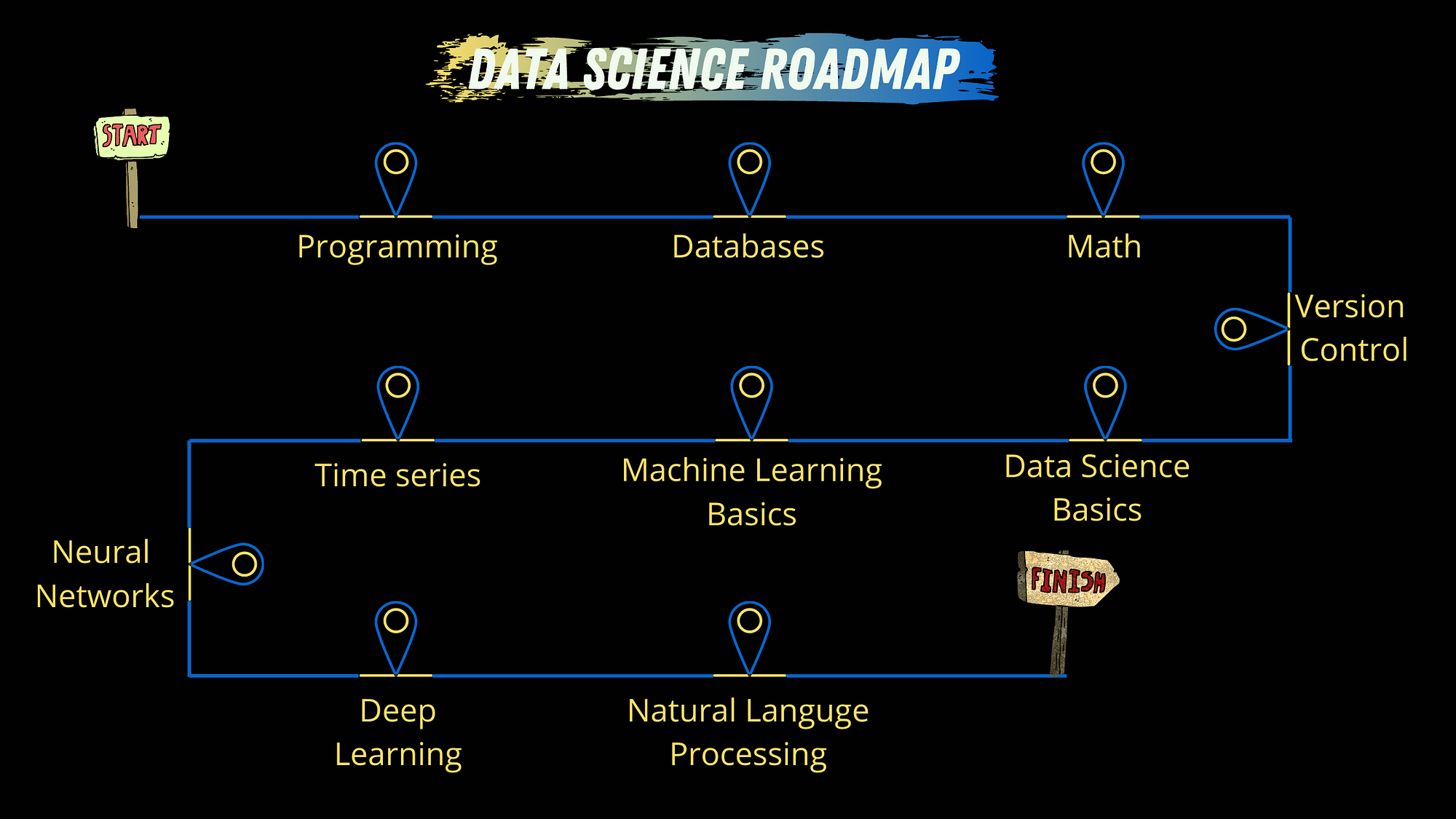
Image by the author (made using Canva).
Conclusion
Here we are at the “end” of the road. End here between quotation, because just like any other technology-related field, there’s no end. The field is developing rapidly because new algorithms and techniques are under research as I type this article.
So, being a data scientist means you will be in a continuous learning stage. You will be developing your knowledge and your style as you go. You will probably feel more attracted to a specific sub-field than another and dig even deeper and maybe specialize in that sub-field.
The most important thing to know as you embark on this journey is, you can do it. You need to be open-minded and dedicate enough time and effort to achieve your end goals.
Original. Reposted with permission.
Related: