ETL and ELT: A Guide and Market Analysis
ETL and related techniques remain a powerful and foundational tool in the data industry. We explain what ETL is and how ETL and ELT processes have evolved over the years, with a close eye toward how third-generation ETL tools are about to disrupt standard data processing practices.
By Louise de_Leyritz, French data science student and growth analyst at Castor, a data catalog solution.

ETL (Extract-Transform-Load) is the most widespread approach to data integration, the practice of consolidating data from disparate source systems with the aim of improving access to data. The story is still the same: businesses have a sea of data at disposition, and making sense of this data fuels business performance. ETL plays a central role in this quest: it is the process of turning raw, messy data into clean, fresh, and reliable data from which business insights can be derived. This article seeks to bring clarity on how this process is conducted, how ETL tools have evolved, and the best tools available for your organization today.
What is ETL?
Today, organizations collect data from multiple different business source systems: Cloud applications, CRM systems, files, etc. The ETL process consists of pooling data from these disparate sources to build a unique source of truth: the data warehouse. ETL pipelines are data pipelines that have a very specific role: extract data from its source system/database, transform it, and load it in the data warehouse, which is a centralized database. Data pipelines themselves are a subset of the data infrastructure, the layer supporting data orchestration, management, and consumption across an organization.
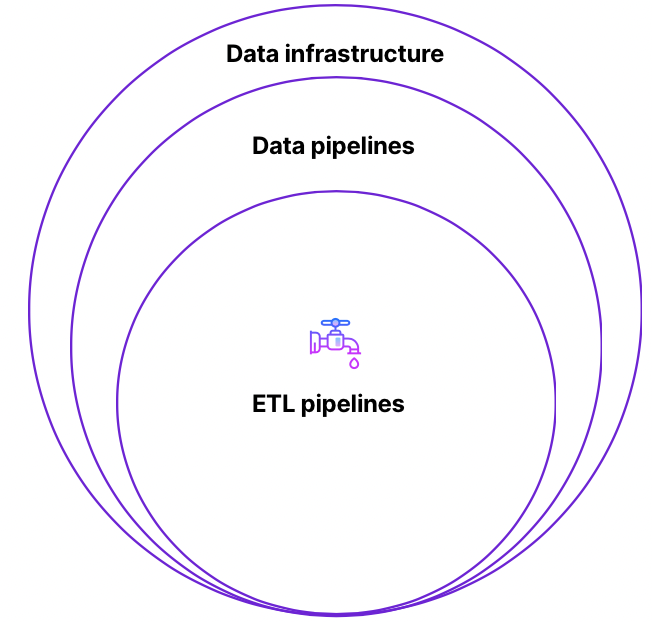
ETL pipelines.
ETL doesn't just move data around: messy data is extracted from its original source system, made reliable through transformations, and finally loaded into the data warehouse.
Extract
The first step of the data integration process is data extraction. This is the stage where data pipelines extract data from multiple data sources and databases and bring it together in a staging area.

ETL Process.
The use of the staging area is the following:
- It's usually impossible to simultaneously extract all the data from all the source systems. The staging area allows for the possibility to bring data together at different times, a way not to overwhelm data sources.
- It avoids performing extractions and transformations simultaneously, which also overburdens data sources.
- Finally, a staging area is useful when there are issues with loading data into the centralized database. This allows syncs to be rolled back and resumed as needed.
Transform
The second step in data integration consists in transforming data, putting it in the right format to make it fit for analysis. There are two parts to making data fit for purpose.
- In its original source system, data is usually messy and thus challenging to interpret. Part of the transformation consists in improving its quality: cleansing invalid data, removing duplicates, standardizing units of measurements, organizing data according to its type, etc.
- At the transformation stage, data is also structured and reformatted to make it fit for its particular business purpose. A lot of the time, transactional data is integrated with operational data, which makes it useful for data analysis and business intelligence. For example, ETL can combine name, place, and pricing data used in business operations with transactional data - such as retail sales or healthcare claims, if that's the structure end-users need to conduct data analysis. Transformations are thus mostly dictated by the specific needs of analysts who are seeking to solve a precise business problem with data.
Load
The final step in data integration is to load the transformed, correctly formatted data in the data warehouse. Data can be loaded all at once (full load) or at scheduled intervals (incremental load). This is achieved using batch or stream loading. Batch loading is when the ETL software extracts batches of data from a source system, usually based on a schedule (every hour, for example). Streaming ETL, also called real-time ETL or stream processing, is an alternative in which information is ingested by the data pipeline as soon as it's made available by the data source system. The specific business use case determines the choice of processing. For example, when you're doing high-frequency trading, you'll usually prefer getting real-time data and a tool that proposes stream processing.
Why do we need ETL?
ETL can be beneficial for your organizations in multiple dimensions:
- ETL combines databases and various forms of data into a single, unified view. This makes it easier to find data and conduct meaningful business analyses.
- ETL improves data people's productivity because it codifies and re-uses processes that move data around.
- ETL offers deep historical context, which fosters trust in the data.
- ETL allows sample data comparison between source and target system
What are the available tools?
ETL Tools have been around for a while, but they have considerably evolved in the past few years as part of their efforts to keep up with the development of data infrastructures.
We distinguish three generations of ETL/ELT tools:
1st generation: Standard ETL (Extract-transform-Load) tools. They follow processes dictated by stringent storage, bandwidth, and computation constraints that characterized the 1990's.
2nd generation: ELT (Extract-Load-Transform) processes result from the arrival of cloud data warehouses and the lifting of storage and bandwidth constraints.
3rd generation: Third-generation ETL tools provide a greater number of connectors thanks to their ability to standardize connectors and leverage their community.
ETL 1.0: Building the data warehouse
The standard approach to data integration (ETL) dates back to the 1970s, when businesses started to use central data repositories. But tools specifically dedicated to helping load data into the data warehouse only appeared in the early 1990s when data warehouses took center stage.
Traditional ETL tools extract the data from siloed systems and databases, transform it according to the desired structure, and then load it in the centralized database. This is achieved according to the following process:
- Define the data project and the business needs it is aligned with
- Identify the relevant data source(s) for the project
- Define the data model/structure that analysts need to solve the particular business problem.
- Build the ETL pipeline (extraction, transformation, and loading functions)
- Conduct data analysis and obtain business insights
The main characteristic of traditional ETL tools is the order in which the process is performed. Specifically, data is transformed before being loaded in the data warehouse. There is a simple reason for that: storage, computation, and bandwidth were extremely scarce and expensive in the 1990s. It was thus crucial to reduce the volume of data before loading it in the warehouse.
The specific order in which this process occurs is at the root of most hurdles associated with first-generation ETL tools.
First, it leads to important scalability issues. ETL pipelines don't just extract data from a database but also perform complex transformations customized to the specific needs of end-users. This involves a considerable amount of time and custom code. When a data user wants to conduct business analyses requiring data in a configuration that doesn't exist yet, data engineers need to rewrite the transformation code for the new use case. When data volumes increase, it becomes impossible to build and maintain highly customized data pipelines.
The second issue with putting the transformation step before the load step is that it leads to constant maintenance of ETL pipelines. Because pipelines extract and transform data altogether, they break as soon as schemas in the data source system change; when a field is removed or added, for example. This invalidates the code used to transform the data into the pre-defined model, and it needs to be re-written by data engineers.
This scalability problem wasn't that big of a deal because the traditional, on-premises data warehouse infrastructure can’t scale to hold and process that much data anyway.
ETL 2.0: The cloud-computing era
In the past decades, storage and computation costs plummeted by a factor of millions, with bandwidth costs shrinking by a factor of thousands. This has led to the exponential growth of the cloud and the arrival of cloud data warehouses such as Amazon Redshift or Google BigQuery**.** The peculiarity of cloud data warehouses is that they are infinitely more scalable than traditional data warehouses, with a capacity to accommodate virtually any amount of data. More than that, cloud data warehouses also support massively parallel processing (MPP), enabling coordination of massive workloads with incredible speed and scalability.
These new cloud data warehouses called for a radical change in ETL processes. Traditional ETL was fine for traditional data warehouses. Now that organizations had a scalable infrastructure, it was time to get scalable ETL pipelines that could process and transform any volumes of data. Traditional ETL tools performance doesn't improve in the cloud because scalability issues are inherent to the process used to move data in the warehouse. Therefore, investing in a cloud data warehouse while using traditional ETL tools would leave you with the same bottlenecks you had in your old data warehouse.
The ETL process had to change, and it did. Notably, data integration technologies were not suffering the storage, computation, and bandwidth constraints anymore. This meant organizations could load large bunches of untransformed data in the warehouse without worrying about costs and constraints. And guess what, they did exactly that.
This is why Extract-Load-Transform (ELT) processes have come to replace traditional ETL. The idea here is to extract data from source systems and directly load it into the cloud data warehouse without transformations taking place. We now speak of ELT connectors, the ****components of ELT tools that establish connections to data sources, build the pipelines, and allow the extracting and loading steps to happen. The transformation for a specific business use case isn't handled by the connectors; it is handled once the data has been loaded in the data warehouse through tools like dbt.

ELT process.
There are key advantages to moving the transformation layer at the end of the workflow:
- Dissociating the load and transformation steps means that data pipelines cease to be highly customized, time-consuming processes. In fact, with ELT, pipelines just move data from source to destination and do nothing more than a bit of data cleaning/normalization. No more customized transformations for end users. This implies that the extraction and loading phases of ELT can be automated and scaled up or down as needed.
- The transformation process is much simpler when it occurs in the cloud data warehouse. Transformations are no longer written in complex languages such as Python. Transformations and data modeling happen in SQL, a language shared by BI professionals, data analysts, and data scientists. This means that transformations, which used to be exclusively owned by data engineers, can now be handled by analysts and technical profiles.
- De-coupling the transformation layer from the extracting and loading has another beneficial effect: Failures at the transformation layer (when upstream schemas or downstream data models change) do not prevent the data from being loaded in the cloud data warehouse. Instead, analysts can re-write the transformations as data continues to be extracted and loaded. Practical.
ETL and ELT thus differ on three levels: when the transformation takes place, where it takes place, and by whom it is performed. The transformation step is by far the most complex in the ETL process, which explains why organizations with cloud data warehouses now use ELT tools.
- Second-generation tools are a great improvement on traditional ETL processes, but they still fail to fully solve the data integration issue. In fact, Most ELT tools on the market haven't cracked the connector case. The most performant ELT tools propose a maximum of 150-200 connectors between data sources and data destinations. And that's already great. The problem is, there are more than 5000 marketing/tech tools used by organizations across the globe. What do these organizations do? Well, they either do away with no tool and build connectors using Airflow or Python (Yes, people still do this!), or they build and maintain their own custom connectors on top of paying for an ETL tool such as Stitch or Fivetran. Not ideal? We know, but the integration game isn't an easy one.
ETL 3.0: Connectors' commoditization
Third-generation ETL tools face a tough challenge: if they want to bring value to customers, they need to meet expectations in terms of connectors and the maintenance efforts needed for them. The solution lies in connector's commoditization, but how can this be achieved?
Connector's standardization
The reason why ETL tools don't propose more than 150/200 out-of-the-box connectors is that these are a real pain to build. Third-generation tools thus put a serious effort into making building new connectors trivial. But how do you make a connector easy to build? You need to standardize the manner in which connectors work. This means building the core of connectors, a core that data engineers will just have to tweak to obtain the custom connector they need.
This comes back to building the Dyson hairdryer for ETL tools. Dyson revolutionized hair care thanks to a small device on which you can plug a hair curler, a hairdryer, a heating brush, a hair straightener, and other fancy bits according to your hair's mood. It took £71 million and hundreds of engineers to develop the device, but customers are happy they don't have to buy six different devices according to how they want their hair to look. It's (weirdly enough) the same challenge for ETL tools: find, build, and make available what defines the core of connectors. They are then easy to customize according to specific use cases, just like switching the end-bit of your hairdryer.

Customize the last part of ETL connectors instead of starting from scratch.
Building a connector to Tableau in a world where connectors aren't standardized takes ages. You need to access the source/destination documentation, test accounts, use the most appropriate language for the task, define inputs, etc. It takes time, and it's tiresome. With standardized connectors, you just need access to the "Analytics" connector core, which has itself been built by enriching a core designed for all connectors. In this configuration, building your Tableau connector takes a few hours instead of a few days.
Open-source: leveraging the strength of community
What's harder than building connectors? Maintaining connectors. Thankfully, open-source ELT tools might have cracked the case here. There is something peculiar about ELT tools: they are built by the same people who use them: data engineers. Hence, open-sourcing ELT tools and growing a strong community of data engineers can lead to an outpouring of great things. Does an engineer want to build a connector that doesn't exist? Thanks to connectors' standardization, it takes them two hours. What's even better is that the whole community, and by definition, all other customers, will benefit from this new connector. Is there a problem with one connector? The engineer that detects it fixes it for everyone. Make maintenance easy: share the burden.
Which ETL/ELT tool for your organization?
There are various considerations at stake when choosing an ETL tool. You want to ensure you pick a tool that's suited to your business. Here are a few aspects we suggest looking at:
- Built-in integrations: Or, more precisely, whether the tools propose the integrations you care about. The most advanced ETL tools propose out-of-the-box connectors to the 150-200 most commonly used applications. If you need an integration with a specific application, make sure you choose a tool that proposes it. It is likely that your ETL tool won't integrate with all your applications/databases. In this case, ensure you pick a tool that integrates with other ETL tools that have the connector you need, connects to an S3 bucket that can act as an intermediary between the original data source and your ETL tool, or ingest data from a manually coded pipeline.
- Maintenance: When looking for a data processing solution, don't forget how critical maintenance is to the process. If you need a full-time engineering team to keep the ETL pipeline running as it should, perhaps you should be considering another solution.
- Scalability: The tool you choose will be different according to whether you're an enterprise customer or a small/mid-market company. If you're an enterprise customer, you should be choosing an ETL tool that can scale easily, with a high availability infrastructure and the ability to process millions of tables every day.
- Support: Regardless of which tool you use, you're eventually going to need help. If you can't get the level of help you need, your team will not be able to carry its critical data processing activity, and this will badly reflect on your business.
Below, you will find an ETL tools landscape, which can hopefully help you choose solutions adapted to the needs of your company.

Click here for a full ETL tools landscape.
More modern data stack benchmarks?
Find more benchmarks and analysis on the modern data stack here. We write about all the processes involved when leveraging data assets: from the modern data stack to data teams composition, to data governance. Our blog covers the technical and the less technical aspects of creating tangible value from data. If you're a data leader and would like to discuss these topics in more depth, join the community we've created for that!
At Castor, we are building a data documentation tool for the Notion, Figma, Slack generation. Or data-wise for the Fivetran, Looker, Snowflake, DBT aficionados. We designed our catalog to be easy to use, delightful and friendly.
Original. Reposted with permission.
Related: