The Mirage of a Citizen Data Scientist
The term "citizen data scientist" has been irritating me recently. I explain why I think it both a bad term and a bad idea, and what we need instead.
The term "citizen data scientist" has been irritating me recently.
It started appearing in 2015 following Gartner research director Alexander Linden suggestion to cultivate
This term was picked up by publications like TechRepublic and NGData which proclaim the rise of the citizen data scientist.
I dislike "citizen data scientist" for two reasons.
First, the word "citizen" has very misleading connotations, especially given the heated debate now in the US regarding immigration.
Having organized and attended many US conferences on data mining and data science, I observed that the majority of researchers and attendees are actually immigrants or visitors. Whether they have become US citizens like me, or are permanent residents, or visitors, has very little relation to the quality of their work.
Second, the term "citizen" Data Scientist implies that people without much training can do the work of a Data Scientist.
I think that in the era of Big Data, training is even more important than before.
The big demand for Data Science skills can be met by either training more people in Data Science, or by creating fully automated software, eg like one that works in a plane auto-pilot or in current self-driving cars.
What will not work is creating a partly automated software and expect people with little training or understanding of data to be able to use it in new situations. Imagine a combination of untrained pilot and an auto-pilot that works 90% of the time. The plane will fly fine for a while until an unpredictable situation will arise, and the autopilot will signal a problem and revert control to the untrained pilot. Bad things will happen. Similar logic is behind Google decision to remove a steering wheel from its self-driving cars - a driver who is relying on a car almost all the time is unlikely to react quickly and adequately in an emergency when the car cannot cope.

We see examples of such Data Science crashes in frequent overfitting of data, especially in social sciences and medicine, with too many unreliable and irreproducible results. These flaws were reported by John P. A. Ioannidis in his landmark paper Why Most Published Research Findings Are False (PLoS Medicine, 2005).
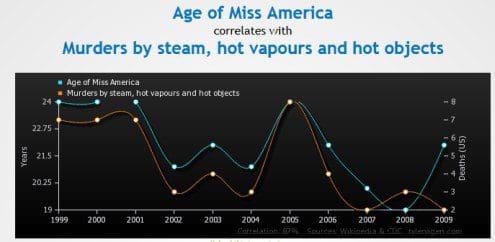
"Citizen" Data Scientists are likely to be misled by false correlations in data. We can recognize the problem in this example below, but what if the field names mean nothing to us?
Age of Miss America correlates to Murders by Steam, hot vapours, and hot objects.

Here are a couple examples from my experience. KDnuggets has recently tested IBM Watson Analytics for social media analysis, which is one of the semi-automated tools that is supposed to be suitable for "citizen" Data Scientist.
We applied IBM Watson to KDnuggets Twitter data from January and one of the key findings was that there was a much higher engagement on Thursdays.
The data was convincing enough, however when I checked the February data, Thursday was no longer the most engaging day for tweets. When I digged deeper, I found that January results were due to one particularly popular tweet. However, someone without understanding Twitter would have reached the conclusion that Thursday is always the best day for tweeting.
Another example from my practice deals with analyzing cerebrospinal fluid for biomarkers of early Alzheimer disease. I worked on this as a Data Science consultant for a very respectable bionformatics firm. The study had about 100 patients diagnosed with early Alzheimer and an equal number of healthy controls. My first results from Mass Spectrometry data analysis were amazing. We found 13 perfect biomarkers that separated Alzheimer from controls with 100% accuracy. Some of them were even biologically plausible - controls had a higher level of vitamin C, and for a while my friends whom I told about the preliminary results started to take extra vitamin C. However, as experienced data scientist, I did not trust the the results - they looked too good to be true. Perhaps the samples were contaminated at some point in the process. So we had to get another data set from different patients, and alas, the biomarkers in the second set had little correlation to the first set.
In the age of Big Data, it is very easy to find spurious correlations and come to wrong conclusions - not tragic when dealing with Twitter, but critical in many other areas of our increasingly data-driven society. Of course, many types of analysis don't require Ph.D. level Data Scientist, and can be done by more junior people with less training.
But such people are not "citizen" Data Scientists. Such people need to combine domain knowledge and sufficient Data Science/Statistical training, possibly with certification.
There is already a good title for such a job - Data Analyst.
Related:
It started appearing in 2015 following Gartner research director Alexander Linden suggestion to cultivate
"citizen data scientists" - people on the business side that may have some data skills, possibly from a math or even social science degree-and putting them to work exploring and analyzing data.
This term was picked up by publications like TechRepublic and NGData which proclaim the rise of the citizen data scientist.
I dislike "citizen data scientist" for two reasons.
First, the word "citizen" has very misleading connotations, especially given the heated debate now in the US regarding immigration.
Having organized and attended many US conferences on data mining and data science, I observed that the majority of researchers and attendees are actually immigrants or visitors. Whether they have become US citizens like me, or are permanent residents, or visitors, has very little relation to the quality of their work.
Second, the term "citizen" Data Scientist implies that people without much training can do the work of a Data Scientist.
I think that in the era of Big Data, training is even more important than before.
The big demand for Data Science skills can be met by either training more people in Data Science, or by creating fully automated software, eg like one that works in a plane auto-pilot or in current self-driving cars.
What will not work is creating a partly automated software and expect people with little training or understanding of data to be able to use it in new situations. Imagine a combination of untrained pilot and an auto-pilot that works 90% of the time. The plane will fly fine for a while until an unpredictable situation will arise, and the autopilot will signal a problem and revert control to the untrained pilot. Bad things will happen. Similar logic is behind Google decision to remove a steering wheel from its self-driving cars - a driver who is relying on a car almost all the time is unlikely to react quickly and adequately in an emergency when the car cannot cope.

We see examples of such Data Science crashes in frequent overfitting of data, especially in social sciences and medicine, with too many unreliable and irreproducible results. These flaws were reported by John P. A. Ioannidis in his landmark paper Why Most Published Research Findings Are False (PLoS Medicine, 2005).
"Citizen" Data Scientists are likely to be misled by false correlations in data. We can recognize the problem in this example below, but what if the field names mean nothing to us?
Age of Miss America correlates to Murders by Steam, hot vapours, and hot objects.
Here are a couple examples from my experience. KDnuggets has recently tested IBM Watson Analytics for social media analysis, which is one of the semi-automated tools that is supposed to be suitable for "citizen" Data Scientist.
We applied IBM Watson to KDnuggets Twitter data from January and one of the key findings was that there was a much higher engagement on Thursdays.
The data was convincing enough, however when I checked the February data, Thursday was no longer the most engaging day for tweets. When I digged deeper, I found that January results were due to one particularly popular tweet. However, someone without understanding Twitter would have reached the conclusion that Thursday is always the best day for tweeting.
Another example from my practice deals with analyzing cerebrospinal fluid for biomarkers of early Alzheimer disease. I worked on this as a Data Science consultant for a very respectable bionformatics firm. The study had about 100 patients diagnosed with early Alzheimer and an equal number of healthy controls. My first results from Mass Spectrometry data analysis were amazing. We found 13 perfect biomarkers that separated Alzheimer from controls with 100% accuracy. Some of them were even biologically plausible - controls had a higher level of vitamin C, and for a while my friends whom I told about the preliminary results started to take extra vitamin C. However, as experienced data scientist, I did not trust the the results - they looked too good to be true. Perhaps the samples were contaminated at some point in the process. So we had to get another data set from different patients, and alas, the biomarkers in the second set had little correlation to the first set.
In the age of Big Data, it is very easy to find spurious correlations and come to wrong conclusions - not tragic when dealing with Twitter, but critical in many other areas of our increasingly data-driven society. Of course, many types of analysis don't require Ph.D. level Data Scientist, and can be done by more junior people with less training.
But such people are not "citizen" Data Scientists. Such people need to combine domain knowledge and sufficient Data Science/Statistical training, possibly with certification.
There is already a good title for such a job - Data Analyst.
Related:
- 21 Must-Know Data Science Interview Questions and Answers, part 2
- Data scientists keep forgetting the one rule
- Big Idea To Avoid Overfitting: Reusable Holdout to Preserve Validity in Adaptive Data Analysis