Deep Learning for Text Understanding from Scratch
Forget about the meaning of words, forget about grammar, forget about syntax, forget even the very concept of a word. Now let the machine learn everything by itself.
By François Petitjean, @LeDataMiner.
Forget about the meaning of words, forget about grammar, forget about syntax, forget even the very concept of a word. Now let the machine learn everything by itself.
This is the amazing story that Xiang Zhang and Yann LeCun from NYU tell us in their recent paper “Text Understanding from Scratch”. They posit that deep learning could make it possible to understand text, without having any knowledge about the language.
The brief – Deep learning for text classification
The paper shows how to use deep learning to perform text classification, for instance to determine if a review given by a customer on a product is positive or negative.
Deep learning has been very successful for big data in the last few years, in particular for temporally and spatially structured data such as images and videos. But it has been less successful in dealing with text: texts are usually treated as a sequence of words, and one big problem with that is that there are too many words in a language to directly use deep learning systems.
English has more than a quarter of a million distinct words, so neural networks would have a quarter of a million neurons in the input layer. This high-dimensionality would prevent us from discovering the most interesting patterns with (deep) networks, and we would have to meticulously engineer the model to include knowledge about syntax and semantic structures.
LeCun’s team has developed a solution to this problem:
Now, this is a very audacious idea, because what they’re basically saying here is “Let’s forget everything we know about languages: meaning of words, the very concept of a word, grammar, syntax – let’s make the machine learning system discover everything relevant to the task, by itself”.
And the amazing thing? It works!
The core – ConvNets
Convolutional Networks (ConvNets) [1,2] is the deep learning system used in the paper. Invented by LeCun in the late 80s, ConvNets work by trying to discover the convolutions that, applied to the data, would be useful to perform the recognition/classification task. The intuition behind convolutions is that they can be used to code many different mathematical transformations of the input.
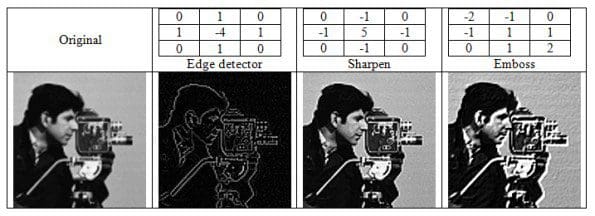
For images, a convolution is often used with a kernel to reveal certain properties of the image. For example, I depict below the application of different kernels (or matrix) to the same image (see also here for a great explanation of convolutions); the convolution uses the matrix the matrix is the function that is applied.
 ConvNets use this idea but instead of using fixed values for the kernel, they let the network infer them automatically so that the produced transformation of the image is specifically designed to perform the recognition task.
ConvNets use this idea but instead of using fixed values for the kernel, they let the network infer them automatically so that the produced transformation of the image is specifically designed to perform the recognition task.
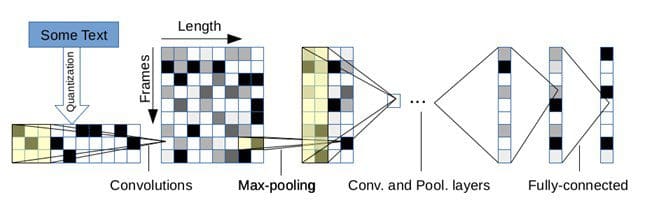
 They use the same idea in this paper: each character is transformed into a binary vector (‘a’ is [1,0,…,0], ‘b’ is [0,1,0,…,0] and ‘z’ is [0,…,0,1]). Broadly speaking, a sequence of characters looks like an image, on which convolutions can be applied.
They use the same idea in this paper: each character is transformed into a binary vector (‘a’ is [1,0,…,0], ‘b’ is [0,1,0,…,0] and ‘z’ is [0,…,0,1]). Broadly speaking, a sequence of characters looks like an image, on which convolutions can be applied.
The network is designed as a traditional deep ConvNet, with successions of convolutional and pooling layers, finishing with 2 fully connected layers. The succession of convolutions makes it possible to learn very diverse sets of features, by learning convolutions of convolutions of convolutions (as if we looked at, for example, the blurred embossed image of the edges of an image, but with the actual operation being learned by the system).
How well does it work?
As I mentioned at the start of the paper, the first amazing thing is that it works at all. Remember, they do not even tell the system how to construct words! But not only have they shown proof of concept, but the team’s experiments show that their system actually works very well on many different tasks, including:
My take I really liked the work and the paper, particularly the authors’ capacity to think out of the box –it’s an audacious idea to classify text without any knowledge of words (would you have bet on it succeeding so well?).
I do however hope to see the team compare their method to stronger competitors in follow-up work, and keep working towards a deeper understanding of text than mere classification allows.
Deep learning has proved useful to bring lower bias classifier, essential characteristics to tackle classification for big data [3]. This paper enables deep learning to be applied to text data, a very useful addition to the data mining toolbox. I look forward to seeing what the authors will do about extending this approach from sequences (of characters) to time series.
(Update: Here is Crepe, code in Torch 7 for text classification from character-level using convolutional networks, used for this work, released by Xiang Zhang on github, April 2015)
Bio
François Petitjean completed his PhD working for the French Space Agency in 2012, and is now a Research Fellow in Geoff Webb’s team at Monash University’s Centre for Data Science. He tweets at @LeDataMiner.
References
[1] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, November1998.
[2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Handwritten digit recognition with a back-propagation network,” in NIPS’89.
[3] S. Chen, A. Martinez, and G.I. Webb (2014). Highly Scalable Attribute Selection for AODE. In Proceedings of the 18th Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 86-97.
Forget about the meaning of words, forget about grammar, forget about syntax, forget even the very concept of a word. Now let the machine learn everything by itself.
This is the amazing story that Xiang Zhang and Yann LeCun from NYU tell us in their recent paper “Text Understanding from Scratch”. They posit that deep learning could make it possible to understand text, without having any knowledge about the language.
The brief – Deep learning for text classification
The paper shows how to use deep learning to perform text classification, for instance to determine if a review given by a customer on a product is positive or negative.
Deep learning has been very successful for big data in the last few years, in particular for temporally and spatially structured data such as images and videos. But it has been less successful in dealing with text: texts are usually treated as a sequence of words, and one big problem with that is that there are too many words in a language to directly use deep learning systems.
English has more than a quarter of a million distinct words, so neural networks would have a quarter of a million neurons in the input layer. This high-dimensionality would prevent us from discovering the most interesting patterns with (deep) networks, and we would have to meticulously engineer the model to include knowledge about syntax and semantic structures.
LeCun’s team has developed a solution to this problem:
what if, instead of seeing a text as a sequence of words, we saw it as a sequence of characters?Since there are only a few dozen possible characters, that would make it possible to directly use deep learning systems for text classification.
Now, this is a very audacious idea, because what they’re basically saying here is “Let’s forget everything we know about languages: meaning of words, the very concept of a word, grammar, syntax – let’s make the machine learning system discover everything relevant to the task, by itself”.
And the amazing thing? It works!
The core – ConvNets
Convolutional Networks (ConvNets) [1,2] is the deep learning system used in the paper. Invented by LeCun in the late 80s, ConvNets work by trying to discover the convolutions that, applied to the data, would be useful to perform the recognition/classification task. The intuition behind convolutions is that they can be used to code many different mathematical transformations of the input.
For images, a convolution is often used with a kernel to reveal certain properties of the image. For example, I depict below the application of different kernels (or matrix) to the same image (see also here for a great explanation of convolutions); the convolution uses the matrix the matrix is the function that is applied.
 ConvNets use this idea but instead of using fixed values for the kernel, they let the network infer them automatically so that the produced transformation of the image is specifically designed to perform the recognition task.
ConvNets use this idea but instead of using fixed values for the kernel, they let the network infer them automatically so that the produced transformation of the image is specifically designed to perform the recognition task.
 They use the same idea in this paper: each character is transformed into a binary vector (‘a’ is [1,0,…,0], ‘b’ is [0,1,0,…,0] and ‘z’ is [0,…,0,1]). Broadly speaking, a sequence of characters looks like an image, on which convolutions can be applied.
They use the same idea in this paper: each character is transformed into a binary vector (‘a’ is [1,0,…,0], ‘b’ is [0,1,0,…,0] and ‘z’ is [0,…,0,1]). Broadly speaking, a sequence of characters looks like an image, on which convolutions can be applied.
The network is designed as a traditional deep ConvNet, with successions of convolutional and pooling layers, finishing with 2 fully connected layers. The succession of convolutions makes it possible to learn very diverse sets of features, by learning convolutions of convolutions of convolutions (as if we looked at, for example, the blurred embossed image of the edges of an image, but with the actual operation being learned by the system).
 How well does it work?
How well does it work? As I mentioned at the start of the paper, the first amazing thing is that it works at all. Remember, they do not even tell the system how to construct words! But not only have they shown proof of concept, but the team’s experiments show that their system actually works very well on many different tasks, including:
- Deciding if a review posted on Amazon is positive or negative with 96% accuracy, and predict the actual number of stars with 73% accuracy.
- Predicting the main topic of news articles (both in English and Chinese) or the one of Yahoo! Answers with accuracies of 92%, 97% and 70% respectively.
My take I really liked the work and the paper, particularly the authors’ capacity to think out of the box –it’s an audacious idea to classify text without any knowledge of words (would you have bet on it succeeding so well?).
Related:
- Juergen Schmidhuber AMA: The Principles of Intelligence and Machine Learning
- Facebook Open Sources deep-learning modules for Torch
- Deep Learning, The Curse of Dimensionality, and Autoencoders
I do however hope to see the team compare their method to stronger competitors in follow-up work, and keep working towards a deeper understanding of text than mere classification allows.
Deep learning has proved useful to bring lower bias classifier, essential characteristics to tackle classification for big data [3]. This paper enables deep learning to be applied to text data, a very useful addition to the data mining toolbox. I look forward to seeing what the authors will do about extending this approach from sequences (of characters) to time series.
(Update: Here is Crepe, code in Torch 7 for text classification from character-level using convolutional networks, used for this work, released by Xiang Zhang on github, April 2015)
Bio
François Petitjean completed his PhD working for the French Space Agency in 2012, and is now a Research Fellow in Geoff Webb’s team at Monash University’s Centre for Data Science. He tweets at @LeDataMiner.
References
[1] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, November1998.
[2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Handwritten digit recognition with a back-propagation network,” in NIPS’89.
[3] S. Chen, A. Martinez, and G.I. Webb (2014). Highly Scalable Attribute Selection for AODE. In Proceedings of the 18th Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 86-97.