Where are the Opportunities for Machine Learning Startups?
Machine learning has permeated data-driven businesses, which means almost all businesses. Here are a few areas where it’s possible that big corporations haven’t already eaten everybody’s lunch.
By Libby Kinsey, Venture Investor.
Machine Learning and AI are fast becoming ubiquitous in data driven businesses, that is to say, an awful lot of businesses. Here I choose a few areas where it’s possible that big corporations haven’t already eaten everybody’s lunch. It’s not uncharted territory — if I could think of the next killer application, I’d be trying to do it!
‘Pick and shovel’ plays
So-called after the California Gold Rush where the purveyors of picks and shovels made a killing (whereas the outcome for prospectors was mixed), the picks and shovels of machine intelligence are hardware, data feeds,and (arguably) the algorithms themselves.
- It’s striking that algorithm developments for machine intelligence have been overwhelmingly open source. Of course there are exceptions — last year, Oxford University filed a patent on an efficient alternative to backprop called the Feedback Alignment Algorithm (page 14) — I wonder how they intend to commercialise it? High quality SaaS offerings that make it easy for people to utilise learning algorithms will find eager customers, and MetaMind, bringing cutting-edge deep learning to your dataset, is one such with all the right credentials. Another initiative I like is The Automatic Statistician project, which searches models to discover the best explanation for your data using Bayesian inference. The Curious AI Company, a General AI company whose first venture is waste sorting (the very definition of unsexy but lucrative), reportedly aims to sell its AI software as a toolkit.
- Large corporations have access to huge datasets and can acquire more (pace IBM’s recent acquisition of The Weather Channel data assets for $1.5bn). But focus to date has been on the low-hanging fruit such as social or ecommerce data, so there’s still opportunity where data is harder to acquire and/or to label. Affectiva’s database of facial emotional responses is in this category, as are Pallas Ludens (end to end data annotation service), and opensensors.io (adding value to public sources of sensor data). Genome and medical image data — subject to some knotty privacy issues — will enable personalised treatment and care, and better diagnostics. On that note, it will be interesting to see howGenomics England proceeds with its industry engagement.
- On the hardware front, GPUs have enabled some extraordinary leaps forward. (And very pedestrian ones — an NVIDIA GeForce GTX Titan enabled me to detect bat calls in audio).
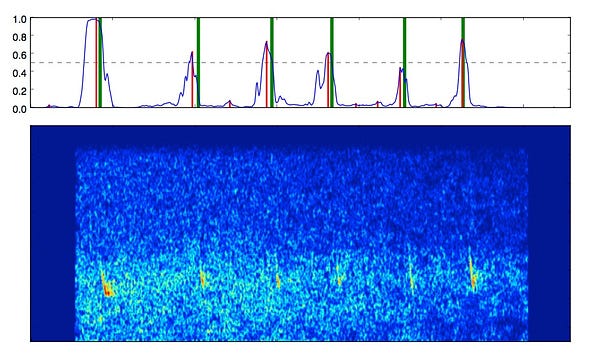
But these processors were designed for graphics. The next step-change for efficient learning and inference will come from processors designed specifically for machine learning. Graphcore calls them Intelligent Processor Units. In the meantime, Nervana Systems, Teradeep (Yann LeCun is an adviser) and Thinci are building their own custom hardware.
It also makes sense to include in this category companies that help toeducate (Udacity, Coursera, Kaggle etc), or that manage code bases and projects (e.g. Atlassian, readying itself to float).
Exploiting emotion
This is an underserved application area in terms of number of startups. To quote from MIT’s Affective Computing group:
“ Emotion is fundamental to human experience, influencing cognition, perception, and everyday tasks such as learning, communication, and even rational decision-making. However, technologists have largely ignored emotion and created an often frustrating experience for people...”

The first task is to train models to recognise emotion in humans. Emotient, RealEyes and Affectiva all use facial expressions to infer emotion, largely (it appears) for marketing purposes right now. Cogito Corp and Beyond Verbal concentrate on understanding emotional cues in voice to conduct market research and to deliver better customer experiences.
Then, to model affective behaviour, e.g. in order to interact in a natural way with humans. Jibo, the ‘friendly’ robot, is a fascinating example using only an ‘eye’ to express itself. There will surely be inexpensive toys that are adaptive and responsive (like Paro the therapeutic seal robot, but for play), although I haven’t managed to find any yet. These would have the advantage of avoiding the privacy concerns of conversational toys like Toy Talk and Mattel’s ‘Hello BarbieTM’, at least until voice can be processed locally rather than in the cloud.
Other applications include personalised care and education, conflict resolution and negotiation training, and adaptive games. These tasks seem to be well suited to machine learning because affective experience is subjective and variable.
Infiltrating the professions
I’ll leave speculation about whether machine intelligence will make us all redundant to others, and instead note that it of course has the potential to assist humans in many professional tasks (and in so doing, deliver greater choice and value for money to the customer).
What might these technologies do? Well, to take the legal profession as an example. Ravn Systems automates the (repetitive, boring) review of documents in legal workloads; Bitproof’s Peter is an AI legal assistant that can request signatures, generate contracts and notarise documents; andPremonition.ai uses data to search for unconscious bias in the judiciary (for anyone who saw The Good Wife S1 E10, this is not new!).
Similar tools for recruitment, insurance, financial management etc. will allow professionals to spend more time on the more satisfying aspects of their jobs, like exercising judgement, decision-making, and … client entertainment.
Revolution healthcare
Drug discovery is expensive and risky, so goes the prevailing wisdom. But what if you can use data to reduce the risk, by finding better targets for development? That’s Stratified Medical’s hypothesis, using deep learning for pharmaceutical R&D.
Elsewhere, Enlitic and Zebra Medical seek to use deep learning for accurate diagnosis / decision support tools, whereas Your.MD has partnered with the National Health Service in the UK to deliver personalised health assistance via an app.
Better search
“What’s that film, the one with the German actor that my sister likes… something to do with aliens… really punky soundtrack?”
Search needs to be able to deal with the inexact, subjective and personal, just like humans do. It needs to help us to discover and curate content that is relevant to us from all the noise. This involves learning context and content attributes. Actually, that’s a blog post all of its own, but here are a few examples:
- Clarify makes audio and video searchable via its API. It’s the equivalent of scanning text for key words to determine relevance, a fantastic time-saving application
- Lumi learns your tastes from your browsing history in order to deliver relevant, current content. A service for the insatiably curious.
- Yossarian Lives is a search engine that can make lateral connections, like humans can, to aid creativity.
- EyeEm has incorporated machine leaning in to its photography marketplace to enable search for attributes such as ‘cheerful’ and ‘rainy London’, without tagging, whilst Cortexica and Sentient Technologies / Shoes.com use similarity to refine product searches.
One essential aspect of search relevance is surely ‘trustworthiness’ so that content and claims made in social media and news sites can be verified or scored for authenticity. Is anyone doing this?
Cyber Security
Machine learning in cyber security has already attracted a substantial amount of venture capital (e.g. $282m in Lookout, $78m in Vectra Networks, $40m in Darktrace, and $89m in Cybereason), but a steady stream of bad news stories (like the recent hack of TalkTalk’s customer data) shows that the market is far from being sewn up.
Like any ‘hot’ area, though, it’s hard to differentiate between multiple startups with ostensibly similar offerings. I certainly need to do more work on this space and will watch Cyber London, an accelerator for cyber security start-ups, closely.
There are so many application areas it’s difficult to focus only on a few. I have missed out some of my favourite companies because they don’t fit one of these categories, and I will inevitably change my mind about what the categories are as soon as this post is published. Especially because I will be attending NIPS next week, which I expect to blow my mind. (Editor's note: NIPS is not next week).
The pace of development and application to new data sets is what makes machine intelligence such an exciting space. In particular, there’s a real sense of momentum in London at the moment, with its proximity to a host of world-class academic institutions (Imperial, UCL, Oxford and Cambridge), an established start-up ecosystem (e.g. accelerators like Entrepreneur First actively targeting machine learning talent), and the location of target customer hubs — financial, legal, and governmental.
So tell me, what have I missed?
Bio: Libby Kinsey works with machine learning startups and VCs in the UK. She completed UCL's MSc in machine learning last year after spending about a decade investing in high-tech startups.
Original. Reposted with permission.
Related: