In Deep Learning, Architecture Engineering is the New Feature Engineering
A discussion of architecture engineering in deep neural networks, and its relationship with feature engineering.
By Stephen Merity, Smerity.com.
Two of the most important aspects of machine learning models are feature extraction and feature engineering. Those features are what supply relevant information to the machine learning models.
Representing the word overfitting using various feature representations:
- Morphological = [(prefix, over-), (root, fit), (suffix=imperfect tense, -ing)]
- Unigrams = ['o', 'v', 'e', 'r', 'f', 'i', 't', 't', 'i', 'n', 'g']
- Bigrams = ['ov', 've', 'er', 'rf', 'fi', 'it', 'tt', 'ti', 'in', 'ng']
- Trigrams = ['ove', 'ver', 'erf', 'rfi', 'fit', 'itt', 'tti', 'tin', 'ing']
- One-hot = [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- Word vector = [-0.26, 0.34, 0.48, -0.06, 0.16, 0.11, 0.13, -0.15, 0.47, -0.49, 0.07, -0.39, -0.13, -0.15, 0.06, 0.09]
- ...
If the features are few or irrelevant, your model may have a hard time making any useful predictions. If there are too many features, your model will be slow and likely overfit.
Humans don't necessarily know what feature representation are best for a given task. Even if they do, relying on feature engineering means that a human is always in the loop. This is a far cry from the future we might want, where you can throw any dataset at a machine learning system and have it produce insights without human help.
The promise of deep learning
The romanticized description of deep learning usually promises that the days of hand crafted feature engineering are gone - that the models are advanced enough to work this out themselves. Like most advertising, this is simultaneously true and misleading.
Whilst deep learning has simplified feature engineering in many cases, it certainly hasn't removed it. As feature engineering has decreased, the architectures of the machine learning models themselves have become increasingly more complex. Most of the time, these model architectures are as specific to a given task as feature engineering used to be.
To clarify, this is still an important step. Architecture engineering is more general than feature engineering and provides many new opportunities. Having said that, however, we shouldn't be oblivious to the fact that where we are is still far from where we intended to be.
Any time a human being forces an architectural decision that couldn't be learned, we're essentially hard coding a feature.
The Convolutional Neural Network (CNN)
A major reason for the resurgence in popularity of neural networks were their impressive results from the ImageNet contest in 2012. The model produced and documented by Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry. That's a staggeringly large improvement - and the model did allow the removal of many hand crafted features too!
CNNs are a prime example of the promise of deep learning - removing complicated and problematic hand crafted feature engineering. Edge detection is no longer handled by an explicitly coded human program but is instead learned by the first convolutional layer. Indeed, the filters learned by the first layer of CNNs when given images are highly reminiscent of Gabor filters, traditionally used for edge and texture detection.

How are CNNs hard coded?
CNNs are feature engineering that enforce 2D locality and weight re-usability. None of that is learned.
Humans are the ones injecting the relationship between pixels (and later CNN neurons) into the machine learning model. There is no way for the model to learn these itself.
At no point can the neural network itself say "I think I need the convolution to be larger" or "Sharing my weights with everyone else doesn't make any sense in this area of the image - this area is always text whilst the other areas are always real world images".
You might not consider this an issue for 2D images - but what if a human doesn't know the relationship between certain parameters in a complex input space?
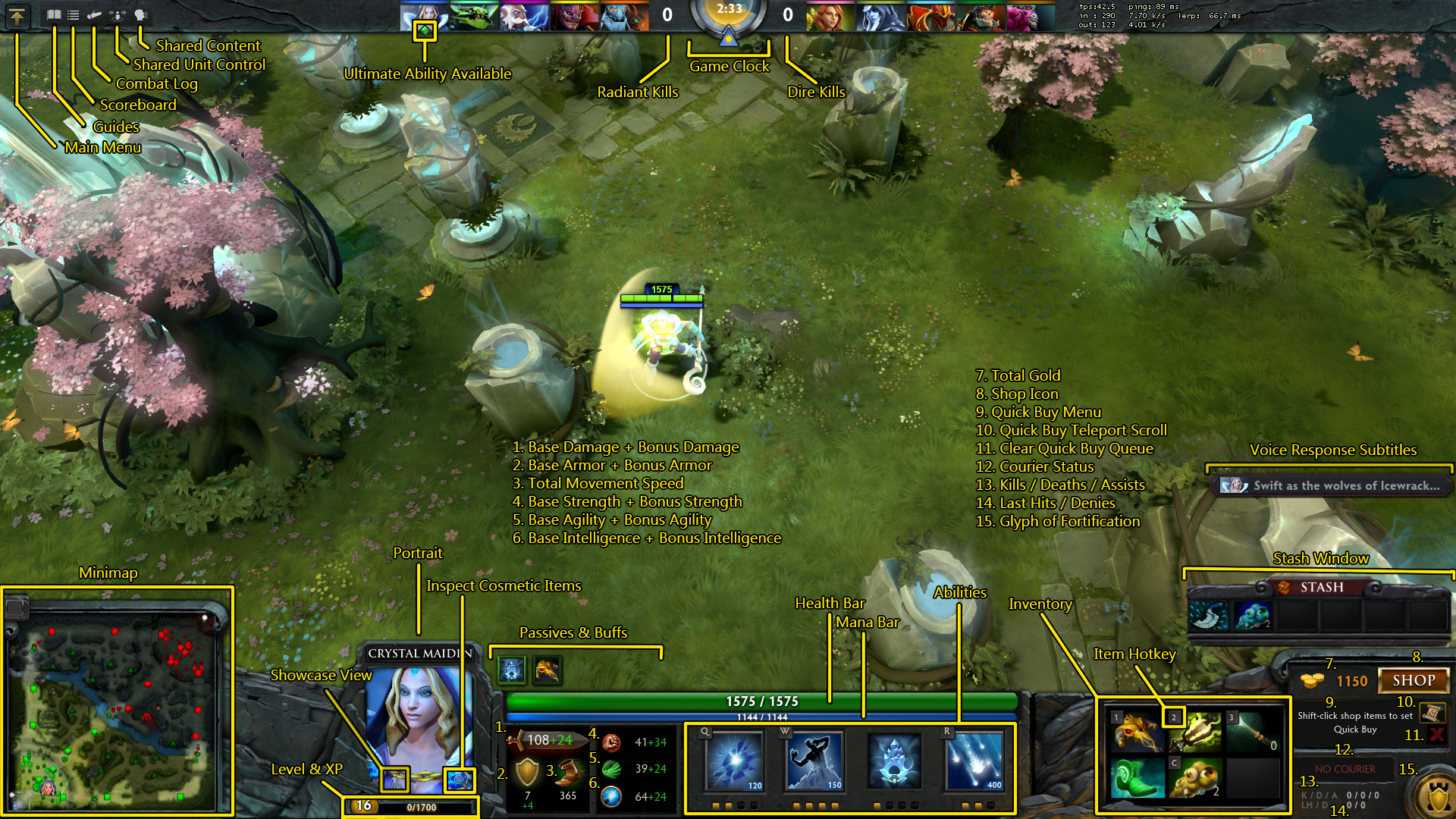
As a simple example, imagine we wanted to extract information from a game. In DotA 2, as with most games, you're provided additional context via an in-game heads-up display on the top and bottom with the middle containing a "viewport" into the game's world. Re-using weights between all these elements would at best be wasteful and at worst result in a poor representation. The mini-map in the bottom left would likely benefit from a very small convolutional window size compared to the viewport. Teaching all potential convolutional windows to be able to read the numbers for XP / HP / gold / level / move speed / etc would likely be a massive waste.
And this is a game. In the grand scheme of things, it's "not complex".
Whilst it would be possible to learn 2D locality by beginning with a fully dense layer, this would be far slower and require larger amounts of training data to get comparable results. Initially, each neuron would be connected to all other neurons in the previous layer. Given enough training data, the model may learn to zero out the majority of the connections, especially if those neurons are spatially distant. You may want to help "nudge" the model in this direction by using L1 regularization to enforce sparsity - though it'd be worth remembering that you just injected external knowledge again.
There is no standard way for allowing a machine learning model to take advantage of weight re-use though. This is a major problem given that weight re-use is a major component of why CNNs work so well. Each filter is shared across all the visual field, allowing a feature to be detected regardless of the position in the field, even if it has never been seen at that location before. On top of decreasing the number of parameters that need to be learned, this weight re-use allows the model to achieve better generalization.
Why is this an issue?
All of these hand coded architectural modifications are enforced, not learned. This directly limits the generality of the models.
In the case of images, you may argue that this is fine - we're only injecting a minor amount of knowledge. Fair enough for images maybe - but what about tasks where humans can't see such "obvious" relations however? If a machine learning model can't divine the "obvious" relations within a 2D image, do you trust it to reason over more complex input where a human dare not tread?
In an optimal world, a meta machine learning algorithm would explore and decide upon the model features and model architecture best suited to the task at hand. This would happen with little to no human intervention.
This is not an optimal world however. We generally have to settle for either human made or badly brute forced. There are people trying to improve our ability to "search" over the theoretical model architecture space - but even then progress is limited.
(Note: I'm not providing a full literature review in the follow two sections, only providing some interesting jumping points for interested explorers - I omit many notable publications such as the NeuroEvolution of Augmented Topologies (NEAT) algorithm and others)
Searching for recurrent neural network architectures
Long ago, in 1994, Angeline et al. produced An evolutionary algorithm that constructs recurrent neural networks. They tried to move away from genetic algorithms towards evolutionary algorithms for searching architectures.
More recently, in An Empirical Exploration of Recurrent Network Architectures, Jozefowicz et al. perform a thorough architecture search where they evaluated over ten thousand different RNN architectures. They were motivated to explore whether the human hand crafted LSTM, one of the most frequently used of RNN architectures, was actually optimal. Whilst they produced interesting insights, the approach is not likely scalable to more general architectural modifications.
Searching for convolutional neural network architectures
Very recently, indeed just after I'd ranted that CNNs provided enforced constraints on the model, Fernando et al. from Google DeepMind released Convolution by Evolution. They evolve / train a neural network to rediscover an (approximate) convolutional neural network structure with a fully connected (read: dense) layer. This means it not only learns about 2D locality but it also learns how to share / compress weights. Whilst exciting, their technique has only been done over relatively toy datasets so far however.
Far from utopia
We're still far away from a world where machine learning models can live without their human tutors. If you investigate the state of the art model architectures for given tasks, you'll inevitably find instances of specific architectural engineering in almost every one of them. Those changes will generally be human specified and integral to achieving state of the art performance...
If we tailor a model to each and every task, do we really have anything generic?
Surely there's a better way?
Addendum:
- ResNets - one of the most exciting recent techniques - is explicitly working around the inability of deep neural networks to just perform the identity function (i.e. nothing) when it's of their best interest!
- Attention models are allowing a form of iterative analysis over the data and provide fascinating insights (such as discovering word alignment for machine translation with no help from humans) but could not be constructed (at least so far) by any of our architectural search procedures
Bio: Stephen Merity is a deep learning research scientist working on memory networks and neural attention mechanisms. His publications are available at Smerity.com.
Original. Reposted with permission.
Related: