Improving the Performance of a Neural Network
There are many techniques available that could help us achieve that. Follow along to get to know them and to build your own accurate neural network.

Neural networks are machine learning algorithms that provide state of the accuracy on many use cases. But, a lot of times the accuracy of the network we are building might not be satisfactory or might not take us to the top positions on the leaderboard in data science competitions. Therefore, we are always looking for better ways to improve the performance of our models. There are many techniques available that could help us achieve that. Follow along to get to know them and to build your own accurate neural network.
Check for Overfitting
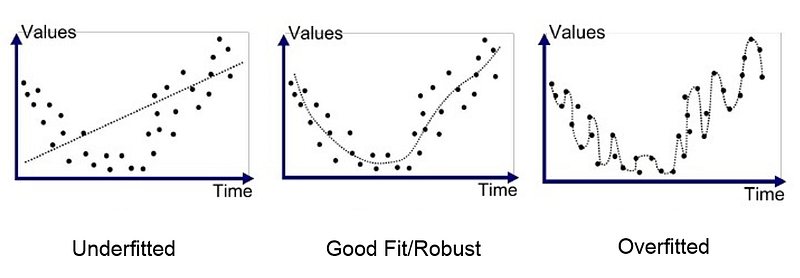
The first step in ensuring your neural network performs well on the testing data is to verify that your neural network does not overfit. Ok, stop, what is overfitting? overfitting happens when your model starts to memorise values from the training data instead of learning from them. Therefore, when your model encounters a data it hasn’t seen before, it is unable to perform well on them. To give you a better understanding, let’s look at an analogy. We all would have a classmate who is good at memorising, and suppose a test on maths is coming up. You and your friend, who is good at memorising start studying from the text book. Your friend goes on memorising each formula, question and answer from the textbook but you, on the other hand, are smarter than him, so you decide to build on intuition and work out problems and learn how these formulas come into play. Test day arrives, if the problems in the test paper are taken straight out of the textbooks, then you can expect your memorising friend to do better on it but, if the problems are new ones that involve applying intuition, you do better on the test and your memorising friend fails miserably.
How to identify if your model is overfitting? you can just cross check the training accuracy and testing accuracy. If training accuracy is much higher than testing accuracy then you can posit that your model has overfitted. You can also plot the predicted points on a graph to verify. There are some techniques to avoid overfitting:
- Regularisation of data (L1 or L2).
- Dropouts — Randomly dropping connections between neurons, forcing the network to find new paths and generalise.
- Early Stopping — Precipitates the training of the neural network, leading to reduction in error in the test set.
Hyperparameter Tuning
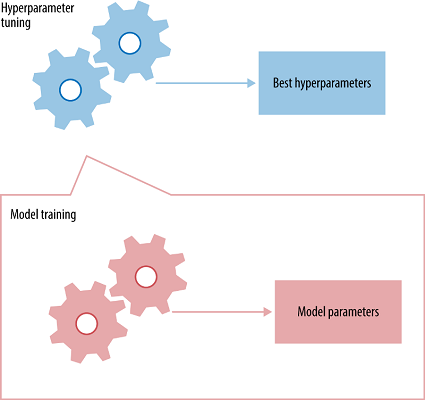
Hyperparameters are values that you must initialise to the network, these values can’t be learned by the network while training. E.x: In a convolutional neural network, some of the hyperparameters are kernel size, the number of layers in the neural network, activation function, loss function, optimizer used(gradient descent, RMSprop), batch size, number of epochs to train etc.
Each neural network will have its best set of hyperparameters which will lead to maximum accuracy. You might ask, “there are so many hyperparameters, how do I choose what to use for each?”, Unfortunately, there is no direct method to identify the best set of hyperparameter for each neural network so it is mostly obtained through trial and error. But, there are some best practices for some hyperparameters which are mentioned below,
- Learning Rate — Choosing an optimum learning rate is important as it decides whether your network converges to the global minima or not. Selecting a high learning rate almost never gets you to the global minima as you have a very good chance of overshooting it. Therefore, you are always around the global minima but never converge to it. Selecting a small learning rate can help a neural network converge to the global minima but it takes a huge amount of time. Therefore, you have to train the network for a longer period of time. A small learning rate also makes the network susceptible to getting stuck in local minimum. i.e the network will converge onto a local minima and unable to come out of it due to the small learning rate. Therefore, you must be careful while setting the learning rate.
- Network Architecture — There is no standard architecture that gives you high accuracy in all test cases. You have to experiment, try out different architectures, obtain inference from the result and try again. One idea that I would suggest is to use proven architectures instead of building one of your own. E.x: for image recognition task, you have VGG net, Resnet, Google’s Inception network etc. These are all open sourced and have proven to be highly accurate, therefore, you could just copy their architecture and tweak them for your purpose.
- Optimizers and Loss function — There is a myriad of options available for you to choose from. In fact, you could even define your custom loss function if necessary. But the commonly used optimizers are RMSprop, Stochastic Gradient Descent and Adam. These optimizers seem to work for most of the use cases. Commonly used loss functions are categorical cross entropy if your use case is a classification task. If you are performing a regression task, mean squared error is the commonly used loss function. Feel free to experiment with the hyperparameters of these optimizers and also with different optimizers and loss functions.
- Batch Size & Number of Epochs — Again, there is no standard value for batch size and epochs that works for all use cases. You have to experiment and try out different ones. In general practice, batch size values are set as either 8, 16, 32… The number of epochs depends on the developer’s preference and the computing power he/she has.
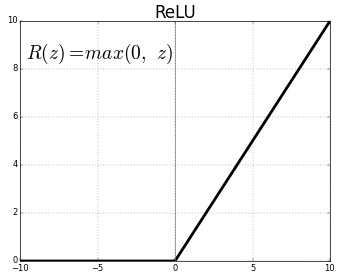
ReLU Activation Function
- Activation Function — Activation functions map the non-linear functional inputs to the outputs. Activation functions are highly important and choosing the right activation function helps your model to learn better. Nowadays, Rectified Linear Unit(ReLU) is the most widely used activation function as it solves the problem of vanishing gradients. Earlier Sigmoid and Tanh were the most widely used activation function. But, they suffered from the problem of vanishing gradients, i.e during backpropagation, the gradients diminish in value when they reach the beginning layers. This stopped the neural network from scaling to bigger sizes with more layers. ReLU was able to overcome this problem and hence allowed neural networks to be of large sizes.
Ensemble of Algorithms

If individual neural networks are not as accurate as you would like them to be, you can create an ensemble of neural networks and combine their predictive power. You can choose different neural network architectures and train them on different parts of the data and ensemble them and use their collective predictive power to get high accuracy on test data. Suppose, you are building a cats vs dogs classifier, 0-cat and 1-dog. When combining different cats vs dogs classifiers, the accuracy of the ensemble algorithm increases based on the Pearson Correlation between the individual classifiers. Let us look at an example, take 3 models and measure their individual accuracy.
Ground Truth: 1111111111 Classifier 1: 1111111100 = 80% accuracy Classifier 2: 1111111100 = 80% accuracy Classifier 3: 1011111100 = 70% accuracy
The Pearson Correlation of the three models is high. Therefore, ensembling them does not improve the accuracy. If we ensemble the above three models using a majority vote, we get the following result.
Ensemble Result: 1111111100 = 80% accuracy
Now, let us look at three models having a very low Pearson Correlation between their outputs.
Ground Truth: 1111111111 Classifier 1: 1111111100 = 80% accuracy Classifier 2: 0111011101 = 70% accuracy Classifier 3: 1000101111 = 60% accuracy
When we ensemble these three weak learners, we get the following result.
Ensemble Result: 1111111101 = 90% accuracy
As you can see above, an ensemble of weak learners with low Pearson Correlation is able to outperform an ensemble with high Pearson Correlation between them.
Dearth of Data

After performing all of the techniques above, if your model still doesn’t perform better in your test dataset, it could be ascribed to the lack of training data. There are many use cases where the amount of training data available is restricted. If you are not able to collect more data then you could resort to data augmentation techniques.

Data Augmentation Techniques
If you are working on a dataset of images, you can augment new images to the training data by shearing the image, flipping the image, randomly cropping the image etc. This could provide different examples for the neural network to train on.
Conclusion
These techniques are considered as best practices and often seem to be effective in increasing the model’s ability to learn features. This might seem like a long post, thank you for reading through it and let me know if any of these techniques did work for you :)
Bio: Rohith Gandhi G: "What I cannot create, I do not understand" - Richard Feynman.
Original. Reposted with permission.
Related:
- Is Learning Rate Useful in Artificial Neural Networks?
- Regularization in Machine Learning
- Top 8 Free Must-Read Books on Deep Learning