How To Create Natural Language Semantic Search For Arbitrary Objects With Deep Learning
An end-to-end example of how to build a system that can search objects semantically.
Part 3 — Train a Language Model To Encode Natural Language Phrases
Now that we have built a mechanism for representing code as a vector, we need a similar mechanism for encoding natural language phrases like those found in docstrings and search queries.
There are a plethora of general purpose pre-trained models that will generate high-quality embeddings of phrases (also called sentence embeddings). This article provides a great overview of the landscape. For example, Google’s universal sentence encoder works very well for many use cases and is available on Tensorflow Hub.
Despite the convenience of these pre-trained models, it can be advantageous to train a model that captures the domain-specific vocabulary and semantics of docstrings. There are many techniques one can use to create sentence embeddings. These range from simple approaches, like averaging word vectors to more sophisticated techniques like those used in the construction of the universal sentence encoder.
For this tutorial, we will leverage a neural language model using an AWD LSTM to generate embeddings for sentences. I know that might sound intimidating, but the wonderful fast.ai library provides abstractions that allow you to leverage this technology without worrying about too many details. Below is a snippet of code that we use to build this model. For more context on how this code works, see this notebook.
Part of the train_lang_model function called in this notebook. Uses fast.ai.
It is important to carefully consider the corpus you use for training when building a language model. Ideally, you want to use a corpus that is of a similar domain to your downstream problem so you can adequately capture the relevant semantics and vocabulary. For example, a great corpus for this problem would be stack overflow data, since that is a forum that contains an extremely rich discussion of code. However, in order to keep this tutorial simple, we re-use the set of docstrings as our corpus. This is sub-optimal as discussions on stack overflow often contain richer semantic information than what is in a one-line docstring. We leave it as an exercise for the reader to examine the impact on the final outcome by using an alternate corpus.
After we train the language model, our next task is to use this model to generate an embedding for each sentence. A common way of doing this is to summarize the hidden states of the language model, such as the concat pooling approach found in this paper. However, to keep things simple we will simply average across all of the hidden states. We can extract the average across hidden states from a fast.ai language model with this line of code:
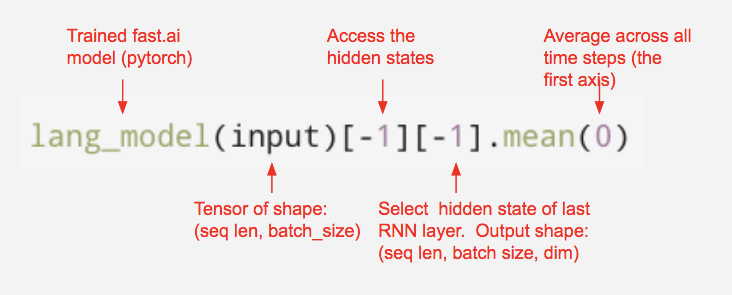
How to extract a sentence embedding from a fast.ai language model. This pattern is used here.
A good way to evaluate sentence embeddings is to measure the efficacy of these embeddings on downstream tasks like sentiment analysis, textual similarity etc. You can often use general-purpose benchmarks such as the examples outlined here to measure the quality of your embeddings. However, these generalized benchmarks may not be appropriate for this problem since our data is very domain specific. Unfortunately, we have not designed a set of downstream tasks for this domain that we can open source yet. In the absence of such downstream tasks, we can at least sanity check that these embeddings contain semantic information by examining the similarity between phrases we know should be similar. The below screenshot illustrates some examples where we search the vectorized docstrings for similarity against user-supplied phrases (taken from this notebook):
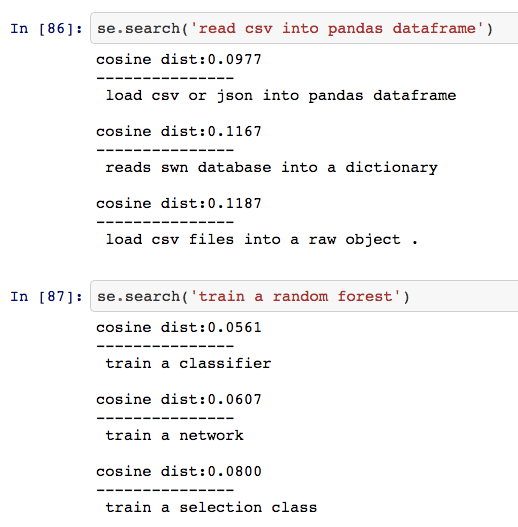
Manual inspection of text similarity as a sanity check. More examples in this notebook.
It should be noted that this is only a sanity check — a more rigorous approach is to measure the impact of these embeddings on a variety of downstream tasks and use that to form a more objective opinion about the quality of your embeddings. More discussion about this topic can be found in this notebook.
Part 4 — Train Model To Map Code Vectors Into The Same Vector Space As Natural Language
At this point, it might be useful to revisit the diagram introduced at the beginning of this tutorial to review where you are. In that diagram you will find this representation of part 4:

A visual representation of the tasks we will perform in Part 4
Most of the pieces for this step come from prior steps in this tutorial. In this step, we will fine-tune the seq2seq model from part 2 to predict docstring embeddings instead of docstrings. Below is code that we use to extract the encoder from the seq2seq model and add dense layers for fine-tuning:
Build a model that maps code to natural language vector space. For more context, see this notebook.
After we train the frozen version of this model, we unfreeze all layers and train the model for several epochs. This helps fine-tune the model a little more towards this task. You can see the full training procedure in this notebook.
Finally, we want to vectorize the code so we can build a search index. For evaluation purposes, we will also vectorize code that does not contain a docstring in order to see how well this procedure generalizes to data we have not seen yet. Below is a code snippet (taken from this notebook) that accomplishes this task. Note that we use the ktext library to apply the same pre-processing steps that we learned on the training set to this data.
Map code to the vector space of natural language with the code2emb model. For more context, see this notebook.
After collecting the vectorized code, we are ready to proceed to the last and final step!
Part 5 — Create A Semantic Search Tool
In this step, we will build a search index using the artifacts we created in prior steps, which is illustrated below:

Diagram of Part 5 (extracted from the main diagram presented at the beginning)
In part 4, we vectorized all the code that did not contain any docstrings. The next step is to place these vectors into a search index where nearest neighbors can be quickly retrieved. A good python library for fast nearest neighbors lookups is nmslib. To enjoy fast lookups using nmslib you must precompute the search index like so:
How to create a search index with nmslib.
Now that you have built your search index of code vectors, you need a way to turn a string (query) into a vector. To do this you will use the language model from Part 3. To make this process easy we provided a helper class in lang_model_utils.py called Query2Emb, which is demonstrated in this notebook.
Finally, once we are able to turn strings into query vectors, we can retrieve the nearest neighbors for that vector like so:
idxs, dists = self.search_index.knnQuery(query_vector, k=k)
The search index will return two items (1) a list of indexes which are integer positions of the nearest neighbors in the dataset (2) distances of these neighbors from your query vector (in this case we defined our index to use cosine distance). Once you have this information, it is straightforward to build semantic search. An example of how you can do this is outlined in the below code:
A class that glues together all the parts we need to build semantic search.
Finally, this notebook shows you how to use the search_engine object above to create an interactive demo that looks like this:

This is the same gif that was presented at the beginning of this tutorial.
Congratulations! You have just learned how to create semantic search. I hope it was worth the journey.
Wait, But You Said Search of Arbitrary Things?
Even though this tutorial describes how to create semantic search for code, you can use similar techniques to search video, audio, and other objects. Instead of using a model that extracts features from code (part 2), you need to train or find a pre-trained model that extracts features from your object of choice. The only prerequisite is that you need a sufficiently large dataset with natural language annotations (such as transcripts for audio, or captions for photos).
We believe you can use the ideas you learned in this tutorial to create your own search and would love to hear from you to see what you create (see the getting in touch section below).
Limitations and Omissions
- The techniques discussed in this blog post are simplified and are only scratching the surface of what is possible. What we have presented is a very simple semantic search — however, in order for such a search to be effective, you may have to augment this search with keyword search and additional filters or rules (for example the ability to search a specific repo, user, or organization and other mechanisms to inform relevance).
- There is an opportunity to use domain-specific architectures that take advantage of the structure of code such as tree-lstms. Furthermore, there are other standard tricks like utilizing attention and random teacher forcing that we omitted for simplicity.
- One part we glossed over is how to evaluate search. This is a complicated subject which deserves its own blog post. In order to iterate on this problem effectively, you need an objective way to measure the quality of your search results. This will be the subject of a future blog post.
Get In Touch!
We hope you enjoyed this blog post. Please feel free to get in touch with us:
Resources
- The GitHub repo for this article.
- To make it easier for those trying to reproduce this example, we have packaged all of the dependencies into a Nvidia-Docker container. For those that are not familiar with Docker you might find this post to be helpful. Here is a link to the docker image for this tutorial on Dockerhub.
- My top recommendation for anyone trying to acquire deep learning skills is to take Fast.AI by Jeremy Howard. I learned many of the skills I needed for this blog post there. Additionally, this tutorial leverages the fastai library.
- Keep an eye on this book, it is still in early release but goes into useful details on this subject.
- This talk by Avneesh Saluja highlights how Airbnb is researching the use of shared vector spaces to power semantic search of listings as well as other data products.
Thanks
Mockup search UI was designed by Justin Palmer (you can see some of his other work here). Also thanks to the following people for their review and input: Ike Okonkwo, David Shinn, Kam Leung.
Disclaimer
Any ideas or opinions presented in this article are our own. Any ideas or techniques presented do not necessarily foreshadow future products of GitHub. The purpose of this blog is for educational purposes only.
Original. Reposted with permission.
Related:
- On the contribution of neural networks and word embeddings in Natural Language Processing
- Getting Started with spaCy for Natural Language Processing
- Implementing Deep Learning Methods and Feature Engineering for Text Data: FastText