On the contribution of neural networks and word embeddings in Natural Language Processing
In this post I will try to explain, in a very simplified way, how to apply neural networks and integrate word embeddings in text-based applications, and some of the main implicit benefits of using neural networks and word embeddings in NLP.
By Jose Camacho Collados, AI/NLP Researcher
Neural networks have contributed to outstanding advancements in fields such as computer vision [1,2] and speech recognition [3]. Lately, they have also started to be integrated in other challenging domains like Natural Language Processing (NLP). But how do neural networks contribute to the advance of text-based applications? In this post I will try to explain, in a very simplified way, how to apply neural networks and integrate word embeddings in text-based applications, and some of the main implicit benefits of using neural networks and word embeddings in NLP.
First, what are word embeddings? Word embeddings are (roughly) dense vector representations of wordforms in which similar words are expected to be close in the vector space. For example, in the figure below, all the big catscheetah, jaguar, panther, tiger and leopard) are really close in the vector space. Word embeddings represent one of the most successful applications of unsupervised learning, mainly due to their generalization power. The construction of these word embeddings varies, but in general a neural language model is trained on a large corpus and the output of the network is used to learn word vectors (e.g. Word2Vec [4]). For those interested in how to build word embeddings and its current challenges, I would recommend a recent survey on this topic [5].
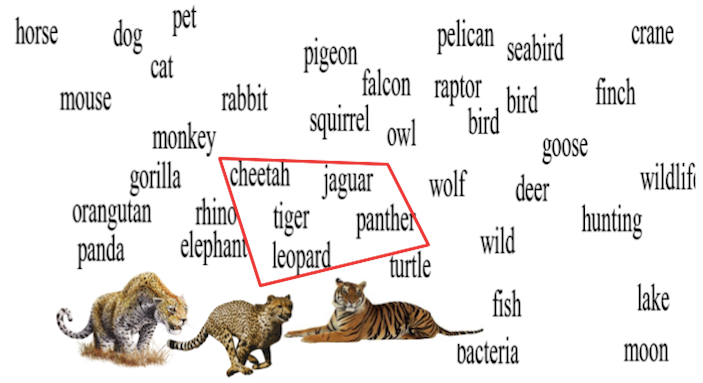
Cluster of the Word2Vec vector space reduced to two dimensions using t-SNE [6]
And then, how can we apply neural networks and word embeddings in text data? This depends on the task, although the general encoding of a text is fairly similar regardless. Given a text, each vector corresponding to each word is passed directly to what we call an embedding layer. Then, there may be zero, one or more hidden layers and an output layer at the end representing the output of the system in a given task. Depending on the specific model, the learning process is carried out in one way or another, but what needs to be learnt are the weights representing the connections (word embeddings are also generally updated throughout the learning process), which is generally achieved through backpropagation. This is a very simplified overview of how neural networks can be applied on text data. If you are interested in knowing more details, the “Neural Network Methods in Natural Language Processing” book by Yoav Goldberg provides an exhaustive overview of neural networks applied to NLP (a short version is also freely available online [7]).
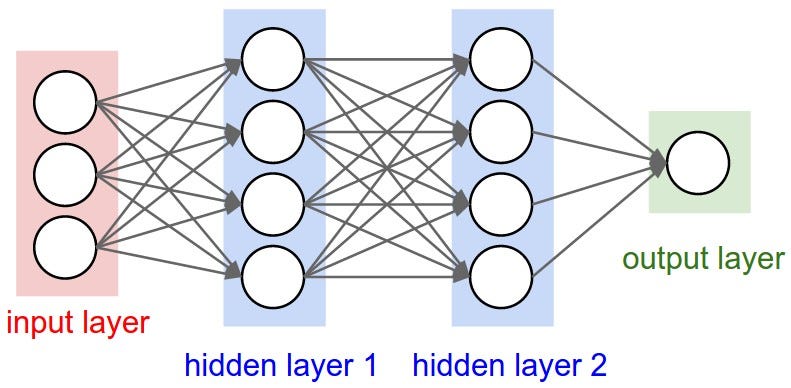
Standard neural network architecture (source: http://cs231n.github.io/convolutional-networks/)
And why are these architectures useful in Natural Language Processing?Let’s take the text classification task as our test-bed application. Given a a text and a pre-defined set of labels (e.g. sports, wildlife, politics, etc.), the goal of text classification consists of associating this text with its most suitable label. To achieve this, usually a training test in which some texts are already associated with their most suitable label is necessary. A few years ago this task used to be solved using supervised linear classification models (e.g. SVMs) over a set of selected features. In its simplest form, these features in the main corresponded to the set of words which were present in a text. For example, given the following sentence inside a text:
“[…] The leap of leopards was seen in the forest […]”
In order to apply our linear model we should first split the text into words (i.e. tokenize) and take these words as the features to classify the text. In this case it seems that such a simple model could correctly classify the text as wildlife, if we consider wildlife as one of the topics we were given.
However, there are several issues:
- First, it is not obvious that the word “leopards” in its plural form (which would be one of the main clues to correctly classify the text) would occur in our training data. If this word does not occur in the training data our model would not be able to infer anything from its occurrence. This is often alleviated by lemmatizing the text, i.e., associating all variants of the same word with the same lemma: “leopards” -> “leopard”. All these preprocessing techniques, while useful for linear models [8,9], are not really necessary in neural architectures [10].
- Second, even with this preprocessing of the input text, it is still likely that the lemma “leopard” is not present in our training corpus (or occurs only a few times). Here is where word embeddings come into play. If you look again at the image from the beginning of the post, you will see that “leopard” is very close in the vector space to words like “tiger” or “panther”. This means that properties across these similar words are shared, and therefore we can infer decisions when “leopard” occurs, even if this word has not been explicitly seen during training.
- Finally, relying on simple word-based features may work fine for detecting the topic of a text, but may fail in other complex tasks. For example, understanding the syntactic structure of a sentence is generally essential to succeed in a task like sentiment analysis. Let’s consider the polarity detection subtask in which we should predict whether a movie review is positive or negative:
“The movie was excellent”
This sentence seems clearly positive. However, if we simply add “far from” in between, we get the sentence “The movie was far from excellent”, which clearly does not imply a positive feeling. Negative words like “not”, or in this case “far from”, could be taken into account as features for changing the polarity of the sentence. Nevertheless, this would require further feature engineering, and even with this integration, it is likely some negative words are left out, or that they are simply not enough given the richness of the human language. For example the same sentence could have been completed with “The movie was far from excellent in its technical aspect but I really enjoyed it and I highly recommend it”. There have been approaches attempting to deal with negation and the polarity of sentences at the phrase level [11], but these kinds of solution get increasingly specific and over-complicated. Therefore, instead of adding complex features for dealing with all cases (practically impossible), neural architectures take the whole sorted sequence into account, and not each word in isolation. With the appropriate amount of training data (not always trivial in many tasks and domains though) they are expected to learn these nuances.
In this post I have described some general implicit benefits of using neural networks for NLP. I hope this could serve as a starting point to newcomers of the field to understand the contribution of these kinds of architecture in NLP. These are common to most neural architectures modeling text corpora, but of course there are more in-depth details of each specific learning algorithm which need to be studied separately and may contribute to other aspects of the learning process.
[1] Yann LeCun, Koray Kavukcuoglu, and Clément Farabet. 2010. Convolutional networks and applications in vision. In Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on IEEE, pages 253–256.
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. 2012. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems. pages 1097–1105.
[3] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. Speech recognition with deep recurrent neural networks. Acoustics, speech and signal processing (icassp), 2013 ieee international conference on. IEEE, 2013.
[4] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word represen- tations in vector space. CoRR abs/1301.3781. https://code.google.com/archive/p/word2vec/
[5] Sebastian Ruder. 2017. Word embeddings in 2017: Trends and future directions. http://ruder.io/word-embeddings-2017/
[6] Laurens van der Maaten and Geoffrey E. Hinton. 2008. Visualizing High-Dimensional Data Using t-SNE. Journal of Machine Learning Research9(Nov):2579–2605. https://lvdmaaten.github.io/tsne/
[7] Yoav Goldberg. 2016. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res.(JAIR), 57, pp.345–420. https://www.jair.org/media/4992/live-4992-9623-jair.pdf
[8] Edda Leopold and Jörg Kindermann. 2002. Text categorization with support vector machines. how to represent texts in input space? Machine Learning 46(1-3):423–444.
[9] Alper Kursat Uysal and Serkan Gunal. 2014. The impact of preprocessing on text classification. Information Processing & Management 50(1):104–112.
[10] Jose Camacho-Collados and Mohammad Taher Pilehvar. 2017. On the Role of Text Preprocessing in Neural Network Architectures: An Evaluation Study on Text Categorization and Sentiment Analysis. arXiv preprint arXiv:1707.01780. https://arxiv.org/abs/1707.01780
[11] Theresa Wilson, Janyce Wiebe, and Paul Hoffmann. Recognizing contextual polarity in phrase-level sentiment analysis. Proceedings of the conference on human language technology and empirical methods in natural language processing. Association for Computational Linguistics, 2005.
Bio: Jose Camacho Collados is a mathematician, AI/NLP researcher and chess International Master.
Original. Reposted with permission.
Related:
- Getting Started with spaCy for Natural Language Processing
- Implementing Deep Learning Methods and Feature Engineering for Text Data: The Skip-gram Model
- Implementing Deep Learning Methods and Feature Engineering for Text Data: The Continuous Bag of Words (CBOW)