Towards Automatic Text Summarization: Extractive Methods
The basic idea looks simple: find the gist, cut off all opinions and detail, and write a couple of perfect sentences, the task inevitably ended up in toil and turmoil. Here is a short overview of traditional approaches that have beaten a path to advanced deep learning techniques.
By Sciforce.
For those who had academic writing, summarization — the task of producing a concise and fluent summary while preserving key information content and overall meaning — was if not a nightmare, then a constant challenge close to guesswork to detect what the professor would find important. Though the basic idea looks simple: find the gist, cut off all opinions and detail, and write a couple of perfect sentences, the task inevitably ended up in toil and turmoil.
On the other hand, in real life we are perfect summarizers: we can describe the whole War and Peace in one word, be it “masterpiece” or “rubbish”. We can read tons of news about state-of-the-art technologies and sum them up in “Musk sent Tesla to the Moon”.
We would expect that the computer could be even better. Where humans are imperfect, artificial intelligence depraved of emotions and opinions of its own would do the job.
The story began in the 1950s. An important research of these days introduced a method to extract salient sentences from the text using features such asword and phrase frequency. In this work, Luhl proposed to weight the sentences of a document as a function of high frequency words, ignoring very high frequency common words –the approach that became the one of the pillars of NLP.
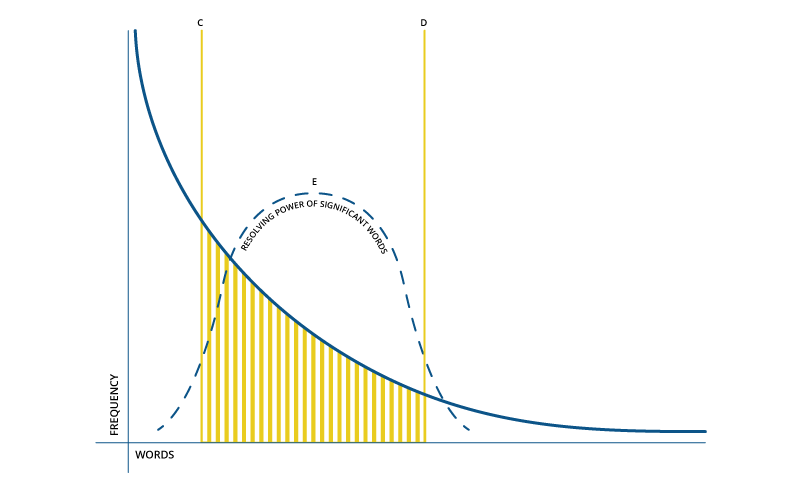
World-frequency diagram. Abscissa represents individual words arranged in order of frequency
By now, the whole branch of natural language processing dedicated to summarization emerged, covering a variety of tasks:
- headlines (from around the world);
- outlines (notes for students);
- minutes (of a meeting);
- previews (of movies);
- synopses (soap opera listings);
- reviews (of a book, CD, movie, etc.);
- digests (TV guide);
- biography (resumes, obituaries);
- abridgments (Shakespeare for children);
- bulletins (weather forecasts/stock market reports);
- sound bites (politicians on a current issue);
- histories (chronologies of salient events).
The approaches to text summarization vary depending on the number of input documents (single or multiple), purpose (generic, domain specific, or query-based) and output (extractive or abstractive).
Extractive summarization means identifying important sections of the text and generating them verbatim producing a subset of the sentences from the original text; while abstractive summarization reproduces important material in a new way after interpretation and examination of the text using advanced natural language techniques to generate a new shorter text that conveys the most critical information from the original one.
Obviously, abstractive summarization is more advanced and closer to human-like interpretation. Though it has more potential (and is generally more interesting for researchers and developers), so far the more traditional methods have proved to yield better results.
That is why in this blog post we’ll give a short overview of such traditional approaches that have beaten a path to advanced deep learning techniques.
By now, the core of all extractive summarizers is formed of three independent tasks:
1) Construction of an intermediate representation of the input text
There are two types of representation-based approaches: topic representation and indicator representation. Topic representation transforms the text into an intermediate representation and interpret the topic(s) discussed in the text. The techniques used for this differ in terms of their complexity, and are divided into frequency-driven approaches, topic word approaches, latent semantic analysis and Bayesian topic models. Indicator representation describes every sentence as a list of formal features (indicators) of importance such as sentence length, position in the document, having certain phrases, etc.
2) Scoring the sentences based on the representation
When the intermediate representation is generated, an importance score is assigned to each sentence. In topic representation approaches, the score of a sentence represents how well the sentence explains some of the most important topics of the text. In indicator representation, the score is computed by aggregating the evidence from different weighted indicators.
3) Selection of a summary comprising of a number of sentences
The summarizer system selects the top k most important sentences to produce a summary. Some approaches use greedy algorithms to select the important sentences and some approaches may convert the selection of sentences into an optimization problem where a collection of sentences is chosen, considering the constraint that it should maximize overall importance and coherency and minimize the redundancy.
Let’s have a closer look at the approaches we mentioned and outline the differences between them:
Topic Representation Approaches
Topic words
This common technique aims to identify words that describe the topic of the input document. An advance of the initial Luhn’s idea was to use log-likelihood ratio test to identify explanatory words known as the “topic signature”. Generally speaking, there are two ways to compute the importance of a sentence: as a function of the number of topic signatures it contains, or as the proportion of the topic signatures in the sentence. While the first method gives higher scores to longer sentences with more words, the second one measures the density of the topic words.
Frequency-driven approaches
This approach uses frequency of words as indicators of importance. The two most common techniques in this category are: word probability and TF-IDF (Term Frequency Inverse Document Frequency). The probability of a word w is determined as the number of occurrences of the word, f (w), divided by the number of all words in the input (which can be a single document or multiple documents). Words with highest probability are assumed to represent the topic of the document and are included in the summary. TF-IDF, a more sophisticated technique, assesses the importance of words and identifies very common words (that should be omitted from consideration) in the document(s) by giving low weights to words appearing in most documents. TF-IDF has given way to centroid-based approaches that rank sentences by computing their salience using a set of features. After creation of TF-IDF vector representations of documents, the documents that describe the same topic are clustered together and centroids are computed — pseudo-documents that consist of the words whose TF-IDF scores are higher than a certain threshold and form the cluster. Afterwards, the centroids are used to identify sentences in each cluster that are central to the topic.
Latent Semantic Analysis
Latent semantic analysis (LSA) is an unsupervised method for extracting a representation of text semantics based on observed words. The first step is to build a term-sentence matrix, where each row corresponds to a word from the input (n words) and each column corresponds to a sentence. Each entry of the matrix is the weight of the word i in sentence j computed by TF-IDF technique. Then singular value decomposition (SVD) is used on the matrix that transforms the initial matrix into three matrices: a term-topic matrix having weights of words, a diagonal matrix where each row corresponds to the weight of a topic, and a topic-sentence matrix. If you multiply the diagonal matrix with weights with the topic-sentence matrix, the result will describe how much a sentence represent a topic, in other words, the weight of the topic i in sentence j.
Discourse Based Method
A logical development of analyzing semantics, is perform discourse analysis, finding the semantic relations between textual units, to form a summary. The study on cross-document relations was initiated by Radev, who came up withCross-Document Structure Theory (CST) model. In his model, words, phrases or sentences can be linked with each other if they are semantically connected. CST was indeed useful for document summarization to determine sentence relevance as well as to treat repetition, complementarity and inconsistency among the diverse data sources. Nonetheless, the significant limitation of this method is that the CST relations should be explicitly determined by human.
Bayesian Topic Models
While other approaches do not have very clear probabilistic interpretations, Bayesian topic models are probabilistic models that thanks to their describing topics in more detail can represent the information that is lost in other approaches. In topic modeling of text documents, the goal is to infer the words related to a certain topic and the topics discussed in a certain document, based on the prior analysis of a corpus of documents. It is possible with the help of Bayesian inference that calculates the probability of an event based on a combination of common sense assumptions and the outcomes of previous related events. The model is constantly improved by going through many iterations where a prior probability is updated with observational evidence to produce a new posterior probability.
Indicator representation approaches
The second large group of techniques aims to represent the text based on a set of features and use them to directly rank the sentences without representing the topics of the input text.
Graph Methods
Influenced by PageRank algorithm, these methods represent documents as a connected graph, where sentences form the vertices and edges between the sentences indicate how similar the two sentences are. The similarity of two sentences is measured with the help of cosine similarity with TF-IDF weights for words and if it is greater than a certain threshold, these sentences are connected. This graph representation results in two outcomes: the sub-graphs included in the graph create topics covered in the documents, and the important sentences are identified. Sentences that are connected to many other sentences in a sub-graph are likely to be the center of the graph and will be included in the summary Since this method do not need language-specific linguistic processing, it can be applied to various languages [43]. At the same time, such measuring only of the formal side of the sentence structure without the syntactic and semantic information limits the application of the method.
Machine Learning
Machine learning approaches that treat summarization as a classification problem are widely used now trying to apply Naive Bayes, decision trees, support vector machines, Hidden Markov models and Conditional Random Fields to obtain a true-to-life summary. As it has turned out, the methods explicitly assuming the dependency between sentences (Hidden Markov model and Conditional Random Fields) often outperform other techniques.

Figure 1: Summary Extraction Markov Model to Extract 2 Lead Sentences and Additional Supporting Sentences

Figure 2: Summary Extraction Markov Model to Extract 3 Sentences
Yet, the problem with classifiers is that if we utilize supervised learning methods for summarization, we need a set of labeled documents to train the classifier, meaning development of a corpus. A possible way-out is to apply semi-supervised approaches that combine a small amount of labeled data along with a large amount of unlabeled data in training.
Overall, machine learning methods have proved to be very effective and successful both in single and multi-document summarization, especially in class-specific summarization such as drawing scientific paper abstracts or biographical summaries.
Though abundant, all the summarization methods we have mentioned could not produce summaries that would similar to human-created summaries. In many cases, the soundness and readability of created summaries are not satisfactory, because they fail to cover all the semantically relevant aspects of data in an effective way and afterwards they fail to connect sentences in a natural way.
Original. Reposted with permission.
Bio: Sciforceis a Ukraine-based IT company specialized in development of software solutions based on science-driven information technologies. We have wide-ranging expertise in many key AI technologies, including Data Mining, Digital Signal Processing, Natural Language Processing, Machine Learning, Image Processing and Computer Vision.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- PDF Data Extraction: What You Need to Know
- Top 10 Books on NLP and Text Analysis
- Text Preprocessing in Python: Steps, Tools, and Examples