Is Bias in Machine Learning all Bad?
We have been taught over our years of predictive model building that bias will harm our model. Bias control needs to be in the hands of someone who can differentiate between the right kind and wrong kind of bias.
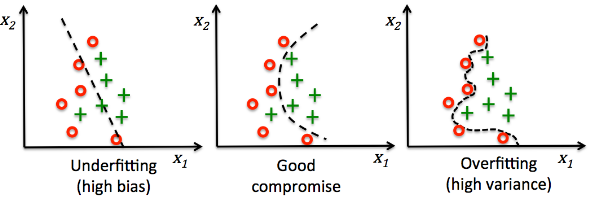
Tom M. Mitchell published a paper in 1980:The Need for Biases in Learning Generalizations
that states:
Learning involves the ability to generalize from past experience in order to deal with new situations that are ”related to” this experience. The inductive leap needed to deal with new situations seems to be possible only under certain biases for choosing one generalization of the situation over another. This paper defines precisely the notion of bias in generalization problems, then shows that biases are necessary for the inductive leap.
We have been taught over our years of predictive model building that bias will harm our model. Bias control needs to be in the hands of someone who can differentiate between the right kind and wrong kind of bias.
His paper states that there are certain biases that help us to create an appropriate model for the problem at hand:
- Factual knowledge of the domain
- In learning generalizations for a particular purpose, it may be possible to
limit the generalizations considered, by appealing to knowledge about the task domain. In a program that learns the rules of baseball (Soloway & Riseman 1978), general knowledge about competitive games constrains the number of generalizations considered. This kind of prior knowledge can provide a strong, justifiable constraint on the generalizations considered. In such a case, the goal of the generalization system becomes ”determine generalizations consistent with the training instances, and with other known facts about the task domain”. - Intended use of the learned generalizations
- Knowledge of the intended use of learned generalizations can provide a strong bias for learning. As a simple example, if the intended use of the learned generalizations involves a much higher cost for incorrect positive than for incorrect negative classifications, then the learning program should prefer more specific generalizations over more general alternatives that are consistent with the same training data.
- Knowledge about the source of training data
- Knowledge about the source of the training instances can also provide a useful constraint on learning. For instance, in learning from a human teacher, we seem to take advantage of many assumptions about the existence of an organized curriculum to constrain our search for appropriate generalizations. In an organized curriculum, our attention is carefully focused on particular features of instances, in a way that
removes ambiguity about which of the possible generalizations is most appropriate. - Bias toward simplicity and generality
- One bias that humans seem to use is a bias toward simple, general explanations. Interpretability allows us to communicate our models to a lay audience and black-box models could leave the model builder at a wall.
- Analogy with previously learned generalizations
- If a system is learning a collection of related concepts, or generalizations, then a possible constraint on generalizing any one of them is to consider successful generalization of others. For example, consider a task of learning structural descriptions of blocks-world objects, such as ”arch”, ”tower”, etc. After learning several concepts, the learned descriptions may reveal that certain features are more significant for describing this class of concepts than are others. For example, if the generalization language contained features such as ”shape”, ”color”, and ”age” of each block in the structure, the system may notice that ”age” is rarely a relevant feature
for characterizing structural classes, and may develop a bias in favor of other features. The justification for this learned bias must be based upon some presumed similarity in the intended use of the concepts being learned.
While this paper was from 1980, the logic behind it does make us think about how to distinguish between necessary and unnecessary biases that are in our models. Certainly we have to eliminate biases that would be a hindrance but as we practice and dig deep into the data, we may realize that some biases actually improve our model to what we actually want.
In a follow-up post, I will talk about the types of biases that one should avoid in a machine learning.
Related:
- 3 Big Problems with Big Data and How to Solve Them
- Designing Ethical Algorithms
- The Algorithms Aren’t Biased, We Are