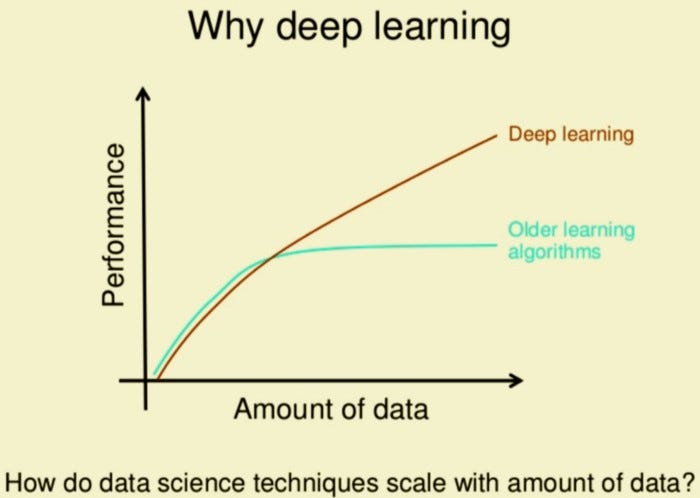
Deep Learning for Image Classification with Less Data
In this blog I will be demonstrating how deep learning can be applied even if we don’t have enough data.
It’s not who has the best algorithm that wins; It’s who has the most data — Andrew Ng.
Image classification is the task of assigning an input image one label from a fixed set of categories. This is one of the core problems in Computer Vision that, despite its simplicity, has a large variety of practical applications.
In this blog I will be demonstrating how deep learning can be applied even if we don’t have enough data. I have created my own custom car vs bus classifier with 100 images of each category. The training set has 70 images while validation set makes up for the 30 images.

Challenges
- Viewpoint variation. A single instance of an object can be oriented in many ways with respect to the camera.
- Scale variation. Visual classes often exhibit variation in their size (size in the real world, not only in terms of their extent in the image).
- Deformation. Many objects of interest are not rigid bodies and can be deformed in extreme ways.
- Occlusion. The objects of interest can be occluded. Sometimes only a small portion of an object (as little as few pixels) could be visible.
- Illumination conditions. The effects of illumination are drastic on the pixel level.

Applications
1. Stock Photography and Video Websites. It’s fueling billions of searches daily in stock websites. It provides the tools to make visual content discoverable by users via search.
2. Visual Search for Improved Product Discoverability. Visual Search allows users to search for similar images or products using a reference image they took with their camera or downloaded from internet.
3. Security Industry. This emerging technology is playing one of the vital roles in the security industry. Many security devices have been developed that includes drones, security cameras, facial recognition biometric devices, etc.
4. Healthcare Industry. Microsurgical procedures in the healthcare industry powered by robots use computer vision and image recognition techniques.
5. Automobile Industry. It can be used for decreasing the rate of road accidents, follow traffic rules and regulations in order, etc.
Environment and tools
- matplotlib
- keras
Data
This is a binary classification problem. I downloaded 200 images of which 100 are bus images and the rest are car images. For downloading the data, I have used this. I have split the data as shown-
dataset train
car
car1.jpg
car2.jpg
//
bus
bus1.jpg
bus2.jpg
// validation
car
car1.jpg
car2.jpg
//
bus
bus1.jpg
bus2.jpg
//...






Image Classification
The complete image classification pipeline can be formalized as follows:
- Our input is a training dataset that consists of N images, each labeled with one of 2 different classes.
- Then, we use this training set to train a classifier to learn what every one of the classes looks like.
- In the end, we evaluate the quality of the classifier by asking it to predict labels for a new set of images that it has never seen before. We will then compare the true labels of these images to the ones predicted by the classifier.
Let’s get started with the code.
I started with loading keras and its various layers which will be required for building the model.
The next step was to build the model. This can be described in the following 3 steps.
- I used two convolutional blocks comprised of convolutional and max-pooling layer. I have used relu as the activation function for the convolutional layer.
- On top of it I used a flatten layer and followed it by two fully connected layers with relu and sigmoid as activation respectively.
- I have used Adam as the optimizer and cross-entropy as the loss.
Data Augumentation
The practice of Data Augumentation is an effective way to increase the size of the training set. Augumenting the training examples allow the network to “see” more diversified, but still representative, datapoints during training.
The following code defines a set of augumentations for the training-set: rotation, shift, shear, flip, and zoom.
Whenever the dataset size is small, data augmentation should be used to create additional training data.
Also I created a data generator to get our data from our folders and into Keras in an automated way. Keras provides convenient python generator functions for this purpose.
Next I trained the model for 50 epochs with a batch size of 32.
Batch size is one of the most important hyperparameters to tune in deep learning. I prefer to use a larger batch size to train my models as it allows computational speedups from the parallelism of GPUs. However, it is well known that too large of a batch size will lead to poor generalization. On the one extreme, using a batch equal to the entire dataset guarantees convergence to the global optima of the objective function. However this is at the cost of slower convergence to that optima. On the other hand, using smaller batch sizes have been shown to have faster convergence to good results. This is intuitively explained by the fact that smaller batch sizes allow the model to start learning before having to see all the data. The downside of using a smaller batch size is that the model is not guaranteed to converge to the global optima.Therefore it is often advised that one starts at a small batch size reaping the benefits of faster training dynamics and steadily grows the batch size through training.
Let’s visualize the loss and accuracy plots.
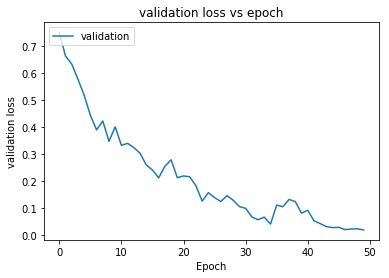

The model is able to reach 100% validation accuracy in 50 epochs.
Conclusions
Thus deep learning is indeed possible with less data. With just 100 images of each categories the model is able to achieve 100% validation accuracy in 50 epochs. This model can be extended for other binary and multi class image classification problems. One could argue that this was fairly easy as car and bus look quite different even for the naked eye. Can we extend this and make a benign/malignant cancer classifier? Sure, we can but the key is using data augmentation whenever data-set size is small. Another approach could be using transfer learning using pre-trained weights.
References/Further Readings
Transfer Learning for Image Classification in Keras
One stop guide to Transfer Learning
Transfer Learning vs Training from Scratch in Keras
Whether to transfer learn or not ?
Don't Decay the Learning Rate, Increase the Batch Size
It is common practice to decay the learning rate. Here we show one can usually obtain the same learning curve on both…
NanoNets : How to use Deep Learning when you have Limited Data
Disclaimer: I’m building nanonets.com to help build ML with less data
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium. These are some of my contacts details:
Happy reading, happy learning and happy coding!
Bio: Abhinav Sagar is a senior year undergrad at VIT Vellore. He is interested in data science, machine learning and their applications to real-world problems.
Original. Reposted with permission.
Related:
- How to Build Your Own Logistic Regression Model in Python
- Convolutional Neural Network for Breast Cancer Classification
- How to Easily Deploy Machine Learning Models Using Flask