The Reinforcement-Learning Methods that Allow AlphaStar to Outcompete Almost All Human Players at StarCraft II
The new AlphaStar achieved Grandmaster level at StarCraft II overcoming some of the limitations of the previous version. How did it do it?

In January, artificial intelligence(AI) powerhouse DeepMind announced it had achieved a major milestone in its journey towards building AI systems that resemble human cognition. AlphaStar was a DeepMind agent designed using reinforcement learning that was able to beat two professional players at a game of StarCraft II, one of the most complex real-time strategy games of all time. During the last few months, DeepMind continued evolving AlphaStar to the point that the AI agent is now able to play a full game of StarCraft II at a Grandmaster level outranking 99.8% of human players. The results were recently published in Nature and they show some of the most advanced self-learning techniques used in modern AI systems.
DeepMind’s milestone is better explained by illustrating the trajectory from the first version of AlphaStar to the current one as well as some of the key challenges of StarCraft II. The use of reinforcement learning to master multi-player games is certainly nothing novel. In recent months, AI agents such as OpenAI Five and DeepMind’s FTW demonstrated the value of reinforcement learning to master modern games of Dota 2 and Quake III. However, StarCraft II is no ordinary game. The StarCraft II environment requires players to balance high level economic decisions with individual control of hundreds of units. To master the game, an AI agent needs to address several key challenges:
- Exploration-Exploitation Balance: In StarCraft II there is no single winning strategy. At any given time, the AI agent needs to balance the need of exploring the environment in order to expand its strategic knowledge instead of taking actions that can yield immediate benefits.
- Imperfect Information: Unlike games like chess in which players can observe the entire environment, StarCraft II never presents the complete environment configuration at any given time. From that perspective, an AI agent needs to be able to operate using imperfect information.
- Long-Term Planning: A typical StarCraft II game takes about 1 hour to complete and, during that time, players are constantly taking actions to execute on an overall strategy. Actions that are taken early in the game might not take effect until much more later which require constant long-term planning abilities.
- Real Time: One thing is strategic planning and another one is real time strategic planning ???? In classic chess, players can safely take 1 hour to evaluate a single more but, in StarCraft II actions need to be taken real time. From the AI perspective, this means that agents need to evaluate thousands of options real time and detect the best match for the long term strategy.
- Large Action Space: If you think that a 19x19 Go board is a large AI environment think again ????. The StarCraft II environment requires players to control hundreds of units at any given time and the combinatorial combinations of actions grow proportional to the complexity to the environment.
AlphaStar v1
To tackle the aforementioned challenges, the DeepMind originally relied on a self-play learning strategy that allow the AlphaStar agent to master the StarCraft game by playing against itself. The core of the AlphaStar architecture is a deep neural network that receives input data from a game interface and outputs a series of actions. The neural network was initially trained using traditional supervised learning leveraging a dataset of anonymized human games released by Blizzard. This initial training allowed AlphaStar to master the initial strategies of the game at a decent level but it was still far from beating a professional player.

After AlphaStar was able to successfully play StarCraft II, the DeepMind team created a multi-agent reinforcement learning environment in which multiple variations of the agent will play against themselves. Named the AlphaStar league, the system allows the agent to improve on specific strategies by playing against a specific version specialized on that strategy.
Challenges and the new AlphaStar
Despite the impressive achievement of the early versions of AlphaStar, the DeepMind team discovered several challenges that were preventing the agents to achieve top level performance in a professional tournament. A classic challenge was “forgetting” in which, despite the improvements in AlphaStar, the agent continuously forgot how to win against a previous version of itself. The new AlphaStar incorporates a series of imitation learning methods to prevent the agent from forgetting learned strategies.
A more difficult challenge presented when the DeepMind team realized that the original version of the AlphaStar league was insufficient in order to consistently improve the level of AlphaStar. To explain this, think about how a human StarCraft II player will go about improving his skills. Most likely, a human player will choose a training partner that will help him train on a particular strategy. As such, their training partners are not playing to win against every possible opponent, but are instead exposing the flaws of their friend, to help them become a better and more robust player. That approach contrasted with the previous version of the AlphaStar league in which all player were focusing on winning. To address that challenge, the new version of AlphaStar created a new version of the league that combine main agents whose goal is to win versus everyone, and also exploiter agents that focus on helping the main agent grow stronger by exposing its flaws, rather than maximizing their own win rate against all players.
The following figure might help to explain how do the exploiters exactly help to create better strategies. In a game of StarCraft, players can create different units( workers, fighters, transporters…)that can be deployed in different strategy moves similar to a game of rock-paper-scissors. Because some strategies are easier to improve, a naïve reinforcement learning model will focus on those rather than on other strategies that might require more learning. The role of the exploiters is to highlight flaws on the main agents forcing then to discover new strategies. At the same time, AlphaStar used imitation learning techniques to prevent the agent from forgetting previous strategies.
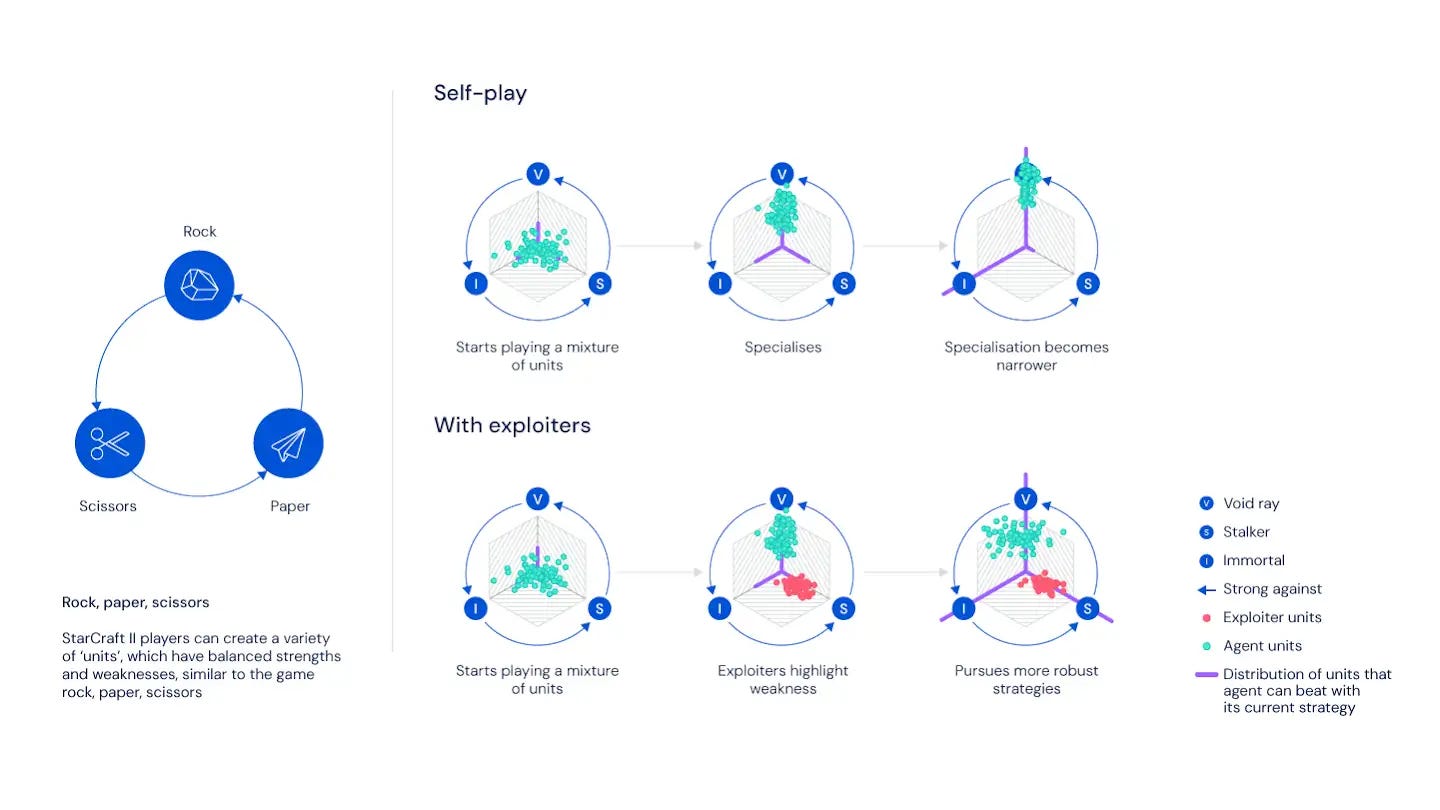
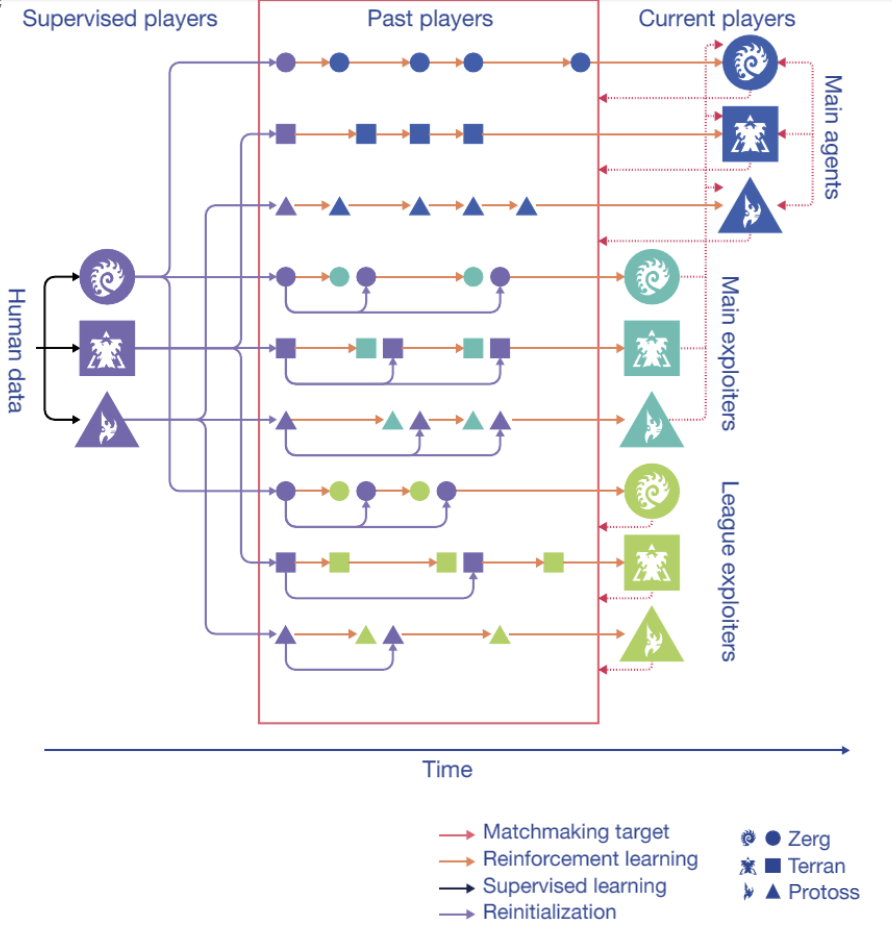
A more technical viewpoint of the new AlphaStar training environment. Three pools of agents, each initialized by supervised learning, were subsequently trained with reinforcement learning. As they train, these agents intermittently add copies of themselves — ‘players’ that are frozen at a specific point — to the league. The main agents train against all of these past players, as well as themselves. The league exploiters train against all past players. The main exploiters train against the main agents. Main exploiters and league exploiters can be reset to the supervised agent when they add a player to the league.
Using these techniques, the new AlphaStar was able to achieve a remarkable progression until reaching grandmaster level. AlphaStar played using restrictions that simulate the conditions of human players and was able to outperform 99.8% of its opponents.
The new AlphaStar is the first AI agents to achieve Grandmaster level in StarCraft II. The lessons learned building AlphaStar apply to many self-learning scenarios such as self-driving vehicles, digital assistants or robotics in which agents need to make decisions over combinatorial action spaces. AlphaStar showed that self-learning AI systems can be apply to many complex scenarios in the real world and deliver remarkable results.
Original. Reposted with permission.
Related:
- DeepMind Has Quietly Open Sourced Three New Impressive Reinforcement Learning Frameworks
- DeepMind is Using This Old Technique to Evaluate Fairness in Machine Learning Models
- Three Things to Know About Reinforcement Learning