 Top 10 AI, Machine Learning Research Articles to know
Top 10 AI, Machine Learning Research Articles to know
 Top 10 AI, Machine Learning Research Articles to know
Top 10 AI, Machine Learning Research Articles to knowWe’ve seen many predictions for what new advances are expected in the field of AI and machine learning. Here, we review a “data set” based on what researchers were apparently studying at the turn of the decade to take a fresh glimpse into what might come to pass in 2020.
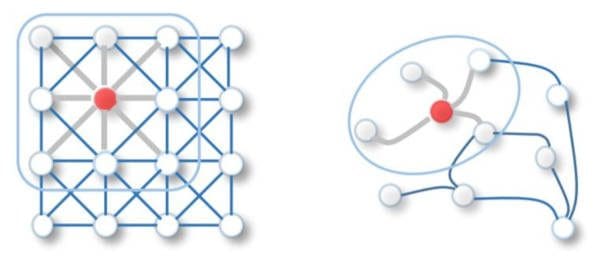 Comparison of a 2-D vs. Graph convolution network. Many real-world data sets can be better described through connections on a graph, and interest is increasing for extending deep learning techniques to graph data (image from Wu, Z., et al., 2019 [1]).
Comparison of a 2-D vs. Graph convolution network. Many real-world data sets can be better described through connections on a graph, and interest is increasing for extending deep learning techniques to graph data (image from Wu, Z., et al., 2019 [1]).
Now that we are well underway into 2020, many predictions already exist for what the top research tracks and greatest new ideas may emerge in the next decade. Even KDnuggets features many future-looking articles to consider, including Top 5 AI trends for 2020, Top 10 Technology Trends for 2020, The 4 Hottest Trends in Data Science for 2020, and The Future of Machine Learning.
Predictions tend to be based on the best guesses or gut reactions from practitioners and subject matter experts in the field. As someone who spends all day and every day messing about with AI and machine learning, any one of the above-cited prediction authors can lay claim to a personal sense for what may come to pass in the following twelve months.
While experience drives expertise in visions for the future, data scientists remain experimentalists at their core. So, it should sound reasonable that predictions for the next important movements in AI and machine learning should be based on collectible data. With machine learning-themed papers continuing to churn out at a rapid clip from researchers around the world, monitoring those papers that capture the most attention from the research community seems like an interesting source of predictive data.
The Arxiv Sanity Preserver by Andrej Karpathy is a slick off-shoot tool of arXiv.org focusing on topics in computer science (cs.[CV|CL|LG|AI|NE]) and machine learning (stat.ML) fields. On December 31, 2019, I pulled the first ten papers listed in the “top recent” tab that filters papers submitted to arXiv that were saved in the libraries of registered users. While the intention of this feature on the site is not to predict the future, this simple snapshot that could represent what machine learning researchers are apparently learning about at the turn of the year might be an interesting indicator for what will come next in the field.
The following list presents yet another prediction of what might come to pass in the field of AI and machine learning – a list presented based in some way on real “data.” Along with each paper, I provide a summary from which you may dive in further to read the abstract and full paper. From graph machine learning, advancing CNNs, semi-supervised learning, generative models, and dealing with anomalies and adversarial attacks, the science will likely become more efficient, work at larger scales, and begin performing better with less data soon as we progress into the '20s.
1) A Comprehensive Survey on Graph Neural Networks
Wu, Zonghan, et al. in cs.LG and stat.ML, latest revision 12/4/2019
1901.00596v4: Abstract – Full Paper (pdf)
Not only is data coming in faster and at higher volumes, but it is also coming in messier. Such “non-Euclidean domains” can be imagined as complicated graphs comprised of data points with specified relationships or dependencies with other data points. Deep learning research is now working hard to figure out how to approach these data-as-spaghetti sources through the notion of GNNs, or graph neural networks. With so much happening in this emerging field recently, this survey paper took the top of the list as the most saved article in users’ collections on arXiv.org, so something must be afoot in this area. The survey also summarized open source codes, benchmark datasets, and model evaluations to help you start to untangle this exciting new approach in machine learning.
2) EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Tan, Mingxing and Le, Quoc in cs.LG, cs.CV and stat.ML, latest revision 11/23/2019
1905.11946v3: Abstract – Full Paper (pdf)
Convolutional Neural Networks (CNNs or ConvNets) are used primarily to process visual data through multiple layers of learnable filters that collectively iterate through the entire field of an input image. Great successes have been seen by applying CNNs to image or facial recognition, and the approach has been further considered in natural language processing, drug discovery, and even gameplay. Improving the accuracy of a CNN is often performed by scaling up the model, say through creating deeper layers or increasing the image resolution. However, this scaling process is not well understood and there are a variety of methods to try. This work develops a new scaling approach that uniformly extends the depth, width, and resolution in one fell swoop into a family of models that seem to achieve better accuracy and efficiency.
3) MixMatch: A Holistic Approach to Semi-Supervised Learning
Berthelot, D., et al. in cs.LG | cs.AI | cs.CV | stat.ML, latest revision 10/23/2019
1905.02249v2: Abstract – Full Paper (pdf)
Semi-supervised learning works in the middle ground of data set extremes where the data includes some hard-to-get labels, but most of it is comprised of typical, cheap unlabeled information. One approach is to make a good guess based on some foundational assumption as to what labels would be for the unlabeled sources, and then it can pull these generated data into a traditional learning model. This research enhances this approach by not only making that first pass with a good guess for the unlabeled data but then mixes everything up between the initially labeled data and the new labels. While it sounds like a tornadic approach, the authors demonstrated significant reductions in error rates through benchmark testing.
4) XLNet: Generalized Autoregressive Pretraining for Language Understanding
Yang, Z., et al. in cs.CL | cs.LG, latest revision 6/19/2019
1906.08237v1: Abstract – Full Paper (pdf)
In the field of natural language processing (NLP), unsupervised models are used to pre-train neural networks that are then finetuned to perform machine learning magic on text. BERT, developed by Google in 2018, is state of the art in pre-training contextual representations but demonstrates discrepancy between the artificial masks used during pretraining that do not exist during the finetuning on real text. The authors here develop a generalized approach that tries to take the best features of current pretraining models without their pesky limitations.
5) Unsupervised Data Augmentation for Consistency Training
Xie, Q., et al. in cs.LG | cs.AI | cs.CL | cs.CV | stat.ML, latest revision 9/30/2019
1904.12848v4: Abstract – Full Paper (pdf)
When you just don’t have enough labeled data, semi-supervised learning can come to the rescue. Here, the authors demonstrated better-than-state-of-the-art results on classic datasets using only a fraction of the labeled data. They applied advanced data augmentation methods that work well in supervised learning techniques to generate high-quality noise injection for consistency training. Their results on a variety of language and vision tasks outperformed previous models, and they even tried out their method with transfer learning while performing fine-tuning from BERT.
6) An Introduction to Variational Autoencoders
Kingma, D., et al. in cs.LG | stat.ML, latest revision 12/11/2019
1906.02691v3: Abstract – Full Paper (pdf)
With generative adversarial networks (GANs) being all the rage these past few years, they can offer the limitation that it is difficult to make sure the network creates something that you are interested in based on initial conditions. Variational autoencoders (VAE) can help with this by incorporating an encoded vector of the target that can seed the generation of new, similar information. The authors provide a thorough overview of variational autoencoders to provide you a strong foundation and reference to leverage VAEs into your work.
7) Deep Learning for Anomaly Detection: A Survey
Chalapathy, R. and Chawla, S. in cs.LG | stat.ML, latest revision 1/23/2019
1901.03407v2: Abstract – Full Paper (pdf)
Discovering outliers or anomalies in data can be a powerful capability for a wide range of applications. From picking up on fraudulent activity on your credit card to finding a networked computer sputtering about before it takes down the rest of the system, flagging unexpected rare events within a data set can significantly reduce the time required for humans to sift through mountains of logs or apparently unconnected data to get to the root cause of a problem. This paper offers a comprehensive overview of research methods in deep learning-based anomaly detection along with the advantages and limitations of these approaches with real-world applications. If you plan on leveraging anomaly detection in your work this year, then make sure this paper finds a permanent spot on your workspace.
8) Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Dai, Z., et al. in cs.LG | cs.CL | stat.ML, latest revision 6/2/2019
1901.02860v3: Abstract – Full Paper (pdf)
In natural language processing, transformers handle the ordered sequence of textual data for translations or summarizations, for example. A great feature of transformers is that they do not have to process the sequential information in order, as would a Recurrent Neural Network (RNN). Introduced in 2017, transformers are taking over RNNs and, in particular, the Long Short-Term Memory (LSTM) network as architectural building blocks. However, transformers remain limited by a fixed-length context in language modeling. The authors here propose an extension by including a segment-level recurrence mechanism and a novel positional encoding scheme. This approach is a new novel neural architecture that expands transformers to handle longer text lengths (hence, the “XL” for “extra long”). Results on standard text data sets demonstrate major improvements in long and short text sequences, so suggests the potential for important advancements in language modeling techniques.
9) Pay Less Attention with Lightweight and Dynamic Convolutions
Wu, F., et al. in cs.CL, latest revision 2/22/2019
1901.10430v2: Abstract – Full Paper (pdf)
Next, sticking with the theme of language modeling, researchers from Facebook AI and Cornell University looked at self-attention mechanisms that relate the importance of positions along a textual sequence to compute a machine representation. This approach is useful for generating language and image content. They develop an alternate lightweight convolution approach that is competitive to previous approaches as well as a dynamic convolution that is even more simple and efficient. Promising results were performed for machine translation, language modeling, and text summarization.
10) Adversarial Examples Are Not Bugs, They Are Features
Illyas, A., et al. in stat.ML | cs.CR | cs.CV | cs.LG, latest revision 8/12/2019
1905.02175v4: Abstract – Full Paper (pdf)
This final top saved article of 2019 was featured in an overview I wrote on KDnuggets. A research group from MIT hypothesized that previously published observations of the vulnerability of machine learning to adversarial techniques are the direct consequence of inherent patterns within standard data sets. While incomprehensible to humans, these exist as natural features that are fundamentally used by supervised learning algorithms. As adversarial attacks that exploit these inconceivable patterns have gained significant attention over the past year, there may be opportunities for developers to harness these features instead, so they won’t lose control of their AI.
Related: