Interpretability, Explainability, and Machine Learning – What Data Scientists Need to Know
The terms “interpretability,” “explainability” and “black box” are tossed about a lot in the context of machine learning, but what do they really mean, and why do they matter?
By Susan Sivek, Alteryx.
I use one of those credit monitoring services that regularly emails me about my credit score: “Congratulations, your score has gone up!” “Uh oh, your score has gone down!”
These fluctuations of a couple of points don’t mean much. I shrug and delete the emails. But what’s causing those fluctuations?
Credit scores are just one example of the many automated decisions made about us as individuals on the basis of complex models. I don’t know exactly what causes those little changes in my score.
Some machine learning models are “black boxes,” a term often used to describe models whose inner workings — the ways different variables ended up related to one another by an algorithm — may be impossible for even their designers to completely interpret and explain.

Photo by Christian Fregnan on Unsplash.
This strange situation has resulted in questions about priorities: How do we prioritize accuracy, interpretability, and explainability in the development of models? Does there have to be a tradeoff among those values?
But first, a disclaimer: There are a lot of different ways of defining some of the terms you’ll see here. This article is just one take on this complex issue!
Interpreting and Explaining Models
Let’s take a closer look at interpretability and explainability with regard to machine learning models. Imagine I were to create a highly accurate model for predicting a disease diagnosis based on symptoms, family history, and so forth.
If I created a logistic regression model for this purpose, you would be able to see exactly what weights were assigned to each variable in my model to predict the diagnosis (i.e., how much each variable contributed to my prediction).
But what if I built a complex neural network model using those same variables? We could look at the layers of the model and their weights, but we might have a difficult time understanding what that configuration actually meant in the “real world,” or, in other words, how the layers and their weights corresponded in recognizable ways to our variables. The neural network model might have lower interpretability, even for experts.
Additionally, we can consider global interpretability (how does the model work for all our observations?) and local interpretability (given these specific data points, how is the model generating a specific prediction?). Both of those levels of understanding have value.
As you can imagine, with something like disease prediction, patients would want to know exactly how my model predicted that they had or didn’t have a disease. Similarly, my credit score calculation could have a significant impact on my life. Therefore, we’d ideally like to have models that are not just interpretable by the experts who construct them but also explainable to people affected by them.

This explainability is so important that it has even been legislated in some places. The EU’s General Data Protection Regulation (GDPR) includes a “right to explanation” that has proven somewhat challenging to interpret, but that mandates greater “algorithmic accountability” for institutions making data-driven decisions that affect individuals. The U.S. Equal Credit Opportunity Act requires that financial institutions provide people who are denied credit or given less favorable lending terms a clear explanation of how that decision was made. If an algorithm was used in that decision, it should be explainable. As the Federal Trade Commission says, “... the use of AI tools should be transparent, explainable, fair, and empirically sound while fostering accountability.”
But even if explainability isn’t legally required for a particular situation, it’s still important to be able to communicate about a model’s workings to stakeholders affected by it. Some kinds of models are inherently easier to translate to a less technical audience. For example, some models can be visualized readily and shared. Decision tree models can often be plotted in a familiar flowchart-esque form that will be explainable in many cases. (If you want to see a super cool animated visualization, scroll through this tutorial on decision trees.) Some natural language processing methods, like topic modeling with LDA, may provide visuals that help viewers understand the rationale for their results.

Photo by Morning Brew on Unsplash.
In other cases, you may have to rely on quantitative measures that demonstrate how a model was constructed, but their meaning is less obviously apparent, especially for non-technical audiences. For example, many statistical models display how each variable is related to the model’s output (e.g., the coefficients for predictor variables in linear regression). Even a random forest model can offer a measure of the relative importance of each variable in generating the model’s predictions. However, you won’t know exactly how all the trees were constructed and how they all contributed together to the final predictions offered by the model.

An example of the variable (feature) importance plot generated by the Forest Model Tool.
Whichever method is used to gain insight into a model’s operation, being able to discuss how it makes predictions with stakeholders is important for improving the model with their informed input, ensuring the model’s fairness, and increasing trust in its output. This need for insight into the model might make you wonder if black boxes are worth the challenges they pose.
Should Black Boxes be Avoided? What About Accuracy?
There are some tasks that today rely on black-box models. For example, image classification tasks are often handled by convolutional neural networks whose detailed operation humans struggle to understand — even though humans built them! As I’ll discuss in the next section, fortunately, humans have also built some tools to peek into those black boxes a little bit. But right now, we have many tools in our everyday lives that rely on difficult-to-interpret models, such as devices using facial recognition.
However, a model that is a “black box” doesn’t necessarily promise greater accuracy in its predictions just because it’s opaque. As one researcher puts it, “When considering problems that have structured data with meaningful features, there is often no significant difference in performance between more complex classifiers (deep neural networks, boosted decision trees, random forests) and much simpler classifiers (logistic regression, decision lists) after preprocessing.”
It appears there doesn’t always have to be a tradeoff between accuracy and interpretability, especially given new tools and strategies being developed that lend insight into the operation of complex models. Some researchers have also proposed “stacking” or otherwise combining “white-box” (explainable) models with black-box models to maximize both accuracy and explainability. These are sometimes called “gray-box” models.

Tools for Peeking Into Black Boxes
As mentioned above, humans are building tools to better understand the tools they’ve already created! In addition to the visual and quantitative approaches described above, there are a few other techniques that can be used to glimpse the workings of these opaque models.
Python and R packages for model interpretability can lend insight into your models’ functioning. For example, LIME (Local Interpretable Model-agnostic Explanations), creates a local, linear, interpretable model around a specific observation in order to understand how the global model generates a prediction with that data point. (Check out the Python package, the R port and vignette, an introductory overview, or the original research paper.)
This video offers a quick overview of LIME from its creators.
Another toolkit called SHAP, which relies on the concept of Shapley values drawn from game theory, calculates each feature’s contribution toward the model’s predictions. This approach provides both global and local interpretability for any kind of model. (Here again, you have options in Python or R, and can read the original paper explaining how SHAP works.)
Partial dependence plots can be used with many models and allow you to see how a model’s prediction “depends” on the magnitude of different variables. These plots are limited to just two features each, though, which may make them less useful for complex, high-dimensional models. Partial dependence plots can be built with scikit-learn in Python or pdp in R.
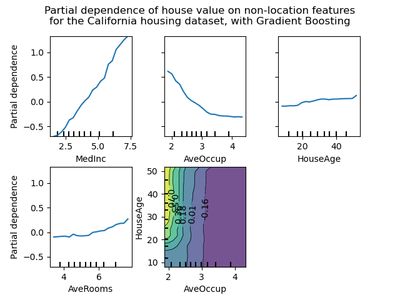
Image from the scikit-learn documentation that shows how each feature affected the outcome variable of house value.
This paper shows an interesting example of an interactive interface built to explain a random forest model for a diabetes diagnosis to stakeholders. The interface used the concept of partial dependence in a user-friendly format. With this explanation, the stakeholders not only better understood how the model operated but also felt more confident about supporting further development of additional predictive tools.
Even the operation of complex image recognition algorithms can be glimpsed in part. “Adversarial patches,” or image modifications, can be used to manipulate the classifications predicted by neural networks, and in doing so, offer insight into what features the algorithm is using to generate its predictions. The modifications can sometimes be very small but still produce an incorrect prediction for an image that the algorithm previously classified accurately. Check out some examples here. (Cool/worrisome side note: This approach can also be used to fool computer vision systems, like tricking surveillance systems, sometimes with a change to just one pixel of an image.)
Whatever approach you take to peek inside your model, being able to interpret and explain its operation can increase trust in the model, satisfy regulatory requirements, and help you communicate your analytic process and results to others.
Recommended reading:
- The Mythos of Model Interpretability, paper by Zachary C. Lipton, for a deep dive into definitions and their usefulness
- Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, free online book by Christoph Molnar
- "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead," article by Cynthia Rudin in Nature Machine Intelligence
Original. Reposted with permission.
Bio: Susan Currie Sivek, Ph.D., is a writer and data geek who enjoys figuring out how to explain complicated ideas in everyday language. After 15 years as a journalism professor and researcher in academia, Susan shifted her focus to data science and analytics, but still loves to share knowledge in creative ways. She appreciates good food, science fiction, and dogs.
Related: