 4 Machine Learning Concepts I Wish I Knew When I Built My First Model
4 Machine Learning Concepts I Wish I Knew When I Built My First Model
 4 Machine Learning Concepts I Wish I Knew When I Built My First Model
4 Machine Learning Concepts I Wish I Knew When I Built My First ModelDiving into building your first machine learning model will be an adventure -- one in which you will learn many important lessons the hard way. However, by following these four tips, your first and subsequent models will be put on a path toward excellence.

Photo by Anthony Tori on Unsplash.
One of the reasons that I love to write is that it gives me an opportunity to look back, reflect on my experiences, and think about what worked well and what didn’t.
For the past 3 months, I was tasked with building a machine learning model to predict whether a product should be RMA'ed or not. I would say that this was the first “serious” machine learning model that I’ve ever developed — and I say “serious” in quotes because this was the first model that created actual business value.
Given that it was my first “serious” model, I had a naïve misconception of what I thought my journey building the model would look like:
Image created by Author.
While in fact, my journey looked more like this:
Image created by Author.
Overall, I would say that it was a success, but there were certainly a lot of ups and downs throughout building the model — why? I spent a lot of time learning new concepts that I didn’t already know. In this article, I wanted to reflect and document what I wish I knew before building this model.
With that said, here are 4 concepts that I wish I knew before building this model!
1. Model Deployment w/ Simple Web UI’s

Image taken by Gradio (with permission)
Something that I recently came across was Gradio, which is a Python package that allows you to build and deploy a web app for your machine learning model in as little as three lines of code. It serves the same purpose as Streamlit or Flask, but I found it much faster and easier to get a model deployed.
Why is this so useful? A couple of reasons:
- It allows for further model validation. Specifically, it allows you to interactively test different inputs into the model. This also allows you to get feedback from other stakeholders and domain experts, especially from non-coders.
- It’s a good way to conduct demos. Personally, I found that showing a Jupyter Notebook to certain stakeholders didn’t do my model any justice, despite it performing very well. Using a library like this makes it easier to communicate your results and sell yourself better.
- It’s easy to implement and distribute. To reiterate, there’s a tiny learning curve, as it only takes 3 lines of code to implement this. As well, it’s really easy to distribute because the web app is accessible by anyone through a public link.
TLDR: Take advantage of ML model GUI’s like Gradio for better testing and communication.
2. Feature Importance
Feature importance refers to a set of techniques for assigning scores to input variables based on how good they are at predicting the target variable. The higher the score, the more important the feature is in the model.
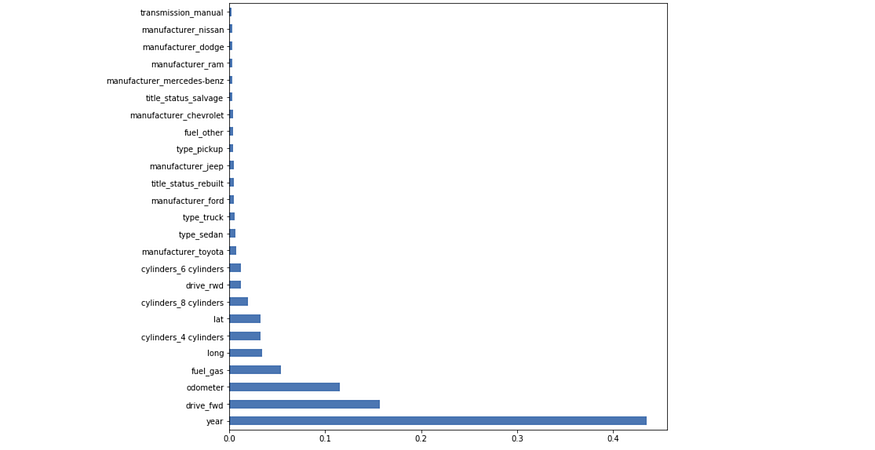
Image created by Author.
For example, if I wanted to predict the price of a car using the features in the graph, by conducting feature importance, I can determine that the year of the model, whether it’s front-wheel drive or not, and the mileage (odometer) of the car are the most important factors when predicting the price of a car.
Pretty awesome right? I bet you’re starting to see why this is so useful.
Feature importance is really useful when it comes to feature selection. By conducting feature importance on a preliminary model, you can easily determine which features have a say in the model and which don’t.
More importantly, feature importance makes it easier to interpret your model and explain your findings because it directly tells you what features are the most indicative of the target variable.
TLDR: Use feature importance to improve feature selection, model interpretability, and communication.
If you want to see an example of how feature importance is implemented, check out my walkthrough of my first machine learning model here.
3. Hyperparameter tuning
The essence of machine learning is finding model parameters that best fit a dataset. This is done through training the model.
On the other hand, hyperparameters are parameters that cannot be directly learned from the model training process. These are higher-level concepts about the model that are generally fixed before training the model.
Examples of hyperparameters are:
- The learning rate
- The number of leaves or the max depth that a tree can have
- The number of hidden layers in a neural network
The thing about hyperparameters is that while they are not determined by the data itself, setting the right hyperparameters can improve your machine learning model from an 80% accuracy to a 95%+ accuracy. This was what happened in my case.
Now to my main point, there are techniques that you can use that will automatically optimize your model’s hyperparameters for you, so that you don’t have to test a bunch of different numbers.
Two of the most common techniques are grid search and random search, which you can read more about here.
TLDR: Techniques like grid search & random search allow you to optimize your model’s hyperparameters, which can significantly improve the performance of your model.
4. Model Evaluation Metrics
This is probably one of the most overlooked areas in online courses, bootcamps, and online resources. And yet, it’s arguably one of the most important concepts in data science.
Knowing what metric(s) to evaluate your machine learning model on ultimately requires you to have a solid understanding of the business problem that you are trying to solve.
As the graph above shows, I didn’t make much progress for the first few weeks because I didn’t clearly understand the business problem, and so I didn’t know what metric I was trying to optimize my model for.
Therefore, we can break this point up into two subpoints:
- Understanding the business requirements of the problem. This means understanding what problem the business is trying to solve, what the parameters of the problem are, what data is available, who the stakeholders, and how the model will be integrated into the business process/product.
- Choosing the right metric(s) to evaluate your model on. In our case, we had the compare the consequences of classifying a false positive vs a false negative. Our final decision ultimately depended on how the model was going to be integrated into the business process.
TLDR: Understand the business problem. Have a solid understanding of all relevant metrics, and understand the consequences of choosing each metric.
Original. Reposted with permission.
Related: