A/B Testing: 7 Common Questions and Answers in Data Science Interviews, Part 1
In this article, we’ll take an interview-driven approach by linking some of the most commonly asked interview questions to different components of A/B testing, including selecting ideas for testing, designing A/B tests, evaluating test results, and making ship or no ship decisions.
Note: This is the first part of this article. You can read the second part here.
A/B tests, a.k.a controlled experiments, are used widely in industry to make product launch decisions. It allows tech companies to evaluate a product/feature with a subset of users to infer how the product may be received by all users. Data scientists are at the forefront of the A/B testing process, and A/B testing is considered one of a data scientist’s core competencies. Data science interviews reflect this reality. Interviewers routinely ask candidates A/B testing questions along with business case questions (a.k.a metric questions, product sense questions) to evaluate a candidate’s product knowledge and ability to drive the A/B testing process.
In this article, we’ll take an interview-driven approach by linking some of the most commonly asked interview questions to different components of A/B testing, including selecting ideas for testing, designing A/B tests, evaluating test results, and making ship or no ship decisions. Specifically, we’ll cover 7 most commonly asked interview questions and answers.
Before you start reading, if you are a video person, feel free to check out this YouTube video for an abbreviated version of this post.
Before a Test — Not Every Idea Is Worth Testing
An A/B test is a powerful tool but not every idea is selected by running a test. Some ideas can be expensive to test, and companies in early phases may have resource constraints, so it’s not practical to run a test for every single idea. Thus, we want to first select which ideas are worth testing, particularly when people have different opinions and ideas on improving a product, and there are many ideas from which to choose. For example, a UX designer may suggest changing some UI elements, a product manager may propose simplifying the checkout flow, an engineer may recommend optimizing a back-end algorithm, etc. In times like this, stakeholders rely on data scientists to drive data-informed decision making. A sample interview question is:
There are a few ideas to increase conversion on an e-commerce website, such as enabling multiple-items checkout (currently users can check out one item at the time), allowing non-registered users to checkout, changing the size and color of the ‘Purchase’ button, etc., how do you select which idea to invest in?
One way to evaluate the value of different ideas is to conduct quantitative analysis using historical data to obtain the opportunity sizing of each idea. For example, before investing in multiple items checkout for an e-commerce website, obtain an upper-bound sizing of the impact by analyzing the number of multiple-items purchased per user. If only a very small percentage of users purchased more than one item, it may not be worth the effort to develop this feature. It’s more important to investigate users’ purchasing behaviors to understand why users do not purchase multiple items together. Is it because the selection of items is too small? Are the items too pricey, and they can only afford one? Is the checkout process too complicated, and they do not want to go through it again?
This kind of analysis provides directional insights on which idea is a good candidate for A/B testing. However, historical data only tells us how we’ve done in the past. It’s not able to predict the future accurately.
To get a comprehensive evaluation of each idea, we could conduct qualitative analysis with focus groups and surveys. Feedback gathered from focus groups (guided discussion with users or perceptive users) or questions from surveys provide more insights into users’ pain points and preferences. A combination of qualitative and qualitative analysis can help further the idea selection process.
Designing A/B Tests
Once we select an idea to test, we need to decide how long we want to run a test and how to select the randomization unit. In this section, we’ll go through these questions one by one.
How long to run a test?
To decide the duration of a test, we need to obtain the sample size of a test, which requires three parameters. These parameters are:
- Type II error rate β or Power, because Power = 1 — β. You know one of them, you know the other.
- Significance level α
- Minimum detectable effect
The rule of thumb is that sample size n approximately equals 16 (based on α = 0.05 and β = 0.8) multiplied by sample variance divided by δ square, whereas δ is the difference between treatment and control:
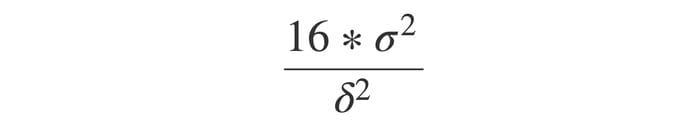
This formula is from Trustworthy Online Controlled Experiments by Ron Kohavi, Diane Tang and Ya Xu
If you are interested in learning how we come up with the rule of thumb formula, check out this video for a step by step walkthrough.
During the interview, you are not expected to explain how you came up with the formula, but you do want to explain how we obtain each parameter and how each parameter influences the sample size. For example, we need more samples if the sample variance is larger, and we need fewer samples if the delta is larger.
Sample variance can be obtained from the existing data, but how do we estimate δ, i.e the difference between treatment and control?
Actually, we don’t know this before we run an experiment, and this is where we use the last parameter: the minimum detectable effect. It is the smallest difference that would matter in practice. For example, we may consider a 0.1% increase in revenue as the minimum detectable effect. In reality, this value is discussed and decided by multiple stakeholders.
Once we know the sample size, we can obtain the number of days to run the experiment by dividing the sample size by the number of users in each group. If the number is less than a week, we should run the experiment for at least seven days to capture the weekly pattern. It is typically recommended to run it for two weeks. When it comes to collecting data for a test, more is almost always better than not enough.
Interference between control and treatment groups
Normally we split the control and treatment groups by randomly selecting users and assigning each user to either the control or treatment group. We expect each user is independent and no interference between control and treatment groups. However, sometimes this independence assumption does not hold. This may happen when testing social networks, such as Facebook, Linkedin, and Twitter, or two-sided markets such as Uber, Lyft, and Airbnb. A sample interview question is:
Company X has tested a new feature with the goal to increase the number of posts created per user. They assigned each user randomly to either the control or treatment group. The Test won by 1% in terms of the number of posts. What do you expect to happen after the new feature is launched to all users? Will it be the same as 1%, if not, would it be more or less? (assume there’s no novelty effect)
The answer is that we will see a value larger than 1%. Here’s why.
In social networks (e.g. Facebook, Linkedin, and Twitter), users’ behavior is likely impacted by that of people in their social circles. A user tends to use a feature or a product if people in their network, such as friends and family, use it. That is called a network effect. Therefore if we use “user” as the randomization unit and the treatment has an impact on users, the effect may spill over to the control group, meaning people’s behaviors in the control group are influenced by those in the treatment group. In that case, the difference between control and treatment groups underestimates the real benefit of the treatment effect. For the interview question, it will be more than 1%.
For two-sided markets (e.g. Uber, Lyft, ebay, and Airbnb): interference between control and treatment groups can also lead to biased estimates of treatment effect. It is mainly because resources are shared among control and treatment groups, meaning that control and treatment groups will compete for the same resources. For example, if we have a new product that attracts more drivers in the treatment group, fewer drivers will be available in the control group. Thus, we’ll not be able to estimate the treatment effect accurately. Unlike social networks where the treatment effect underestimates the real benefit of a new product, in two-sided markets, the treatment effect overestimates the actual effect.
How to deal with interference?

Photo by Chris Lawton on Unsplash
Now that we know why interference between control and treatment can cause the post-launch effect to behave differently than the treatment effect, it leads us to the next question: how do we design the test to prevent the spillover between control and treatment? A sample interview question is:
We are launching a new feature that provides coupons to our riders. The goal is to increase the number of rides by decreasing the price for each ride. Outline a testing strategy to evaluate the effect of the new feature.
There are many ways to tackle the spillover between groups and the main goal is to isolate users in the control and treatment groups. Below are a few commonly used solutions, each applies in different scenarios, and all of them have limitations. In practice, we want to choose the method that works the best under certain conditions, and we could also combine multiple methods to get reliable results.
Social networks:
- One way to ensure isolation is to create network clusters to represent groups of users who are more likely to interact with people within the group than people outside of the group. Once we have those clusters, we could split them into control and treatment groups. Check out this paper for more details on this approach.
- Ego-cluster randomization. The idea originated from Linkedin. A cluster is composed of an “ego” (a focal individual), and her “alters” (the individuals she is immediately connected to). It focuses on measuring the one-out network effect, meaning the effect of a user’s immediate connection’s treatment on that user, then each user either has the feature or does not, and no complicated interactions between users are needed. This paper explains this method in detail.
Two-sided markets:
- Geo-based randomization. Instead of splitting by users, we could split by geo-locations. For example, we could have the New York Metropolitan area in the control group and the San Francisco Bay Area in the treatment group. This will allow us to isolate users in each group, but the pitfall is that there will be a larger variance because each market is unique in certain ways through things such as the customer’s behavior, competitors, etc.
- Another method, though used less commonly, is time-based randomization. Basically, we select a random time, for example, a day of a week, and assign all users to either the control or treatment group. It works when the treatment effect only lasts for a short amount of time, such as when testing a new surge price algorithm performs better. It does not work when the treatment effect takes a long time to be effective, such as a referral program. It can take some time for a user to refer to his or her friends.
Bio: Emma Ding is a Data Scientist & Software Engineer at Airbnb.
Original. Reposted with permission.
Related:
- 5 Things to Know About A/B Testing
- How to Get Data Science Interviews: Finding Jobs, Reaching Gatekeepers, and Getting Referrals
- How I Got 4 Data Science Offers and Doubled my Income 2 Months After Being Laid Off