Exploring the SwAV Method
This post discusses the SwAV (Swapping Assignments between multiple Views of the same image) method from the paper “Unsupervised Learning of Visual Features by Contrasting Cluster Assignments” by M. Caron et al.
By Antonio Ferraioli, AI Aficionado
In this post we discuss SwAV (Swapping Assignments between multiple Views of the same image) method from the paper “Unsupervised Learning of Visual Features by Contrasting Cluster Assignments” by M. Caron et al.
For those interested in coding, several code repositories about SwAV algorithm are on GitHub; if in doubt, take a look at the repo mentioned in the paper.
Self-supervised learning of visual features
Supervised learning works with labeled training data; for example, in supervised image classification algorithms a cat photo needs to be annotated and labeled as “cat”. Self-supervised learning aims at obtaining features without using manual annotations. We will consider, in paticular, visual features.
There are two main classes of self-supervised learning methods for visual representation learning:
- clustering-based methods require a pass over the entire dataset to form image “codes” (cluster assignments) that are used as targets during training, then some form of clustering is used to group similar image features;
- contrastive methods use a loss function that explicitly compares pairs of image representations to push away representations from different images while pulling together those from transformations, or views, of the same image.
Online learning
Contrastive methods require computing all the pairwise comparisons on a large dataset; this is not practical. Typical clustering-based methods require to process entire datasets to determine codes, and this is expensive. A cheaper method would be better: online learning methods allow to train a system feeding a single data (or a mini-batch) instance at a time (no need to provide or process the whole input dataset at the start). The model can learn about new data on the fly and it keeps learning as new data comes in.
The SwAV method is a clustering-based online method whose goal is to learn visual features in an online fashion without supervision.
The method
The SwAV method computes a code from an augmented version of the image and predicts this code from other augmented versions of the same image.
Each image xn (we suppose there are N original images in total) is transformed into an augmented view xnt where t is a transformation like cropping, rotation, reducing image size, color change. The authors use a multi-crop stage where two standard resolution crops are used and V additional low resolution crops that cover only small parts of the image are sampled (V + 2 images in total, low resolution images ensures only a small increase in the compute cost).
The augmented view is mapped to a vector representation fθ (xnt) and this feature is then normalized into znt. In practice, fθ is a sort of image encoder implemented by a convolutional neural network (ResNet50 for example) followed by a projection head that consists of a two layered MLP with ReLU activations.
After this normalization, a code qnt is computed mapping znt to a set of K trainable normal vectors {c1 , . . . , cK}, called prototypes, that may be thought as the “clusters” in which the dataset should be partitioned (details about how to compute codes and update prototypes online are in the next paragraph). The number of prototypes K is given and not inferred. The authors set a default test value of 3000 prototypes for classification on ImageNet dataset. In neural networks implementation, a prototype vector is just the weights of a dense layer (with linear activation).
A little swapping trick comes in the end. Consider two different features zt and zs from two different augmentations of the same image and compute their codes qt and qs by matching these features to a set of K prototypes {c1 , . . . , cK}. Then consider the following loss:
L(zt , zs) = ℓ (zt , qs) + ℓ (zs , qt) .
The intuition is that if the two features zt and zs capture the same information (in essence, they are features deriving from the same image), then it should be possible to predict a given feature’s code from the other feature. The network and prototypes will be updated following this loss function.
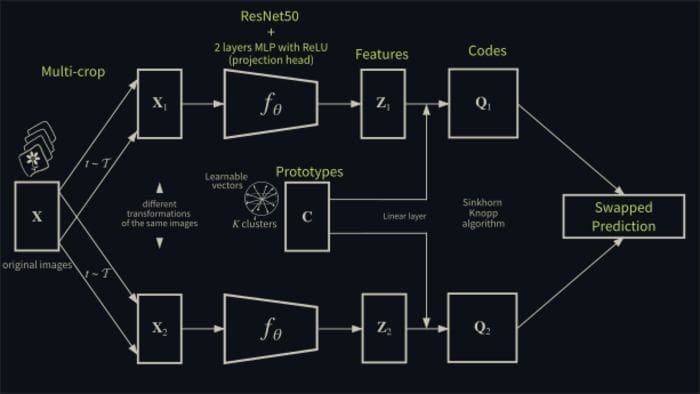 Fig 1. SwAV architecture (enlarged)
Fig 1. SwAV architecture (enlarged)
Loss function details
The loss function has two terms. Each term represents the cross entropy loss between the code 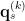 and the probability
and the probability 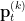 obtained by taking the softmax of the dot products of zi and all prototypes, that is
obtained by taking the softmax of the dot products of zi and all prototypes, that is
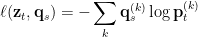
(k ranges over all prototypes) where for each fixed k

The parameter τ is called temperature. The logarithm in the cross-entropy expression is applied element-wise. If we call C the matrix whose columns are the prototype vectors and if we use the fact that natural logarithm is the inverse function of exp, we can express the total loss for every image and for every pair of transformations varying in their respective domains:
![\displaystyle - \frac{1}{N}\sum_{n=1}^N \sum_{s,t\,\sim \mathcal{T}} \left[ \frac{1}{\tau} \mathbf{z}_{nt}^\top \mathbf{C} \mathbf{q}_{ns} + \frac{1}{\tau} \mathbf{z}_{ns}^\top \mathbf{C} \mathbf{q}_{nt} - \log \sum_{k=1}^K \exp \left( \frac{\mathbf{z}_{nt}^\top \mathbf{c}_k}{\tau} \right) - \log \sum_{k=1}^K \exp \left( \frac{\mathbf{z}_{ns}^\top \mathbf{c}_k}{\tau} \right) \right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-+%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bn%3D1%7D%5EN+%5Csum_%7Bs%2Ct%5C%2C%5Csim+%5Cmathcal%7BT%7D%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B%5Ctau%7D+%5Cmathbf%7Bz%7D_%7Bnt%7D%5E%5Ctop+%5Cmathbf%7BC%7D+%5Cmathbf%7Bq%7D_%7Bns%7D+%2B+%5Cfrac%7B1%7D%7B%5Ctau%7D+%5Cmathbf%7Bz%7D_%7Bns%7D%5E%5Ctop+%5Cmathbf%7BC%7D+%5Cmathbf%7Bq%7D_%7Bnt%7D++-+%5Clog+%5Csum_%7Bk%3D1%7D%5EK+%5Cexp+%5Cleft%28+%5Cfrac%7B%5Cmathbf%7Bz%7D_%7Bnt%7D%5E%5Ctop+%5Cmathbf%7Bc%7D_k%7D%7B%5Ctau%7D++%5Cright%29+-+%5Clog+%5Csum_%7Bk%3D1%7D%5EK+%5Cexp+%5Cleft%28+%5Cfrac%7B%5Cmathbf%7Bz%7D_%7Bns%7D%5E%5Ctop+%5Cmathbf%7Bc%7D_k%7D%7B%5Ctau%7D+%5Cright%29+%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Here C ≡ D ⨉ K, features z ≡ D ⨉ 1, codes q ≡ K ⨉ 1, prototypes c ≡ D ⨉ 1. The loss function is minimized jointly with respect to the prototypes C and the parameters θ of the image encoder fθ. Prototype vectors are learned along with the ConvNet parameters by backpropragation.
Computing codes online
Codes are computed using only the image features within a batch to make the method online. A problem to solve is the cluster assignment: assign B samples [z1 , . . . , zB ] to K (prototype) clusters [ c1 , . . . , cK ].
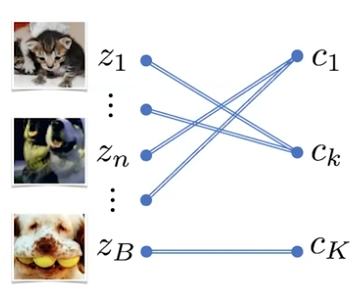 Fig. 2. Cluster assignment
Fig. 2. Cluster assignmentSo we have to map B samples to K prototypes: let Q be the matrix representing this mapping. There is a trivial solution that must be discarded: assigning all samples to just one cluster! To solve this issue we introduce an equipartition constraint. Intuitively, we want that all prototypes are selected the same amounts of time. So, as a constraint, we restrict our attention only to those matrices whose projections onto their rows and columns — respectively — are probability distributions that split the data uniformly, which is captured by
r = 1/K · 1K
c = 1/B · 1B
where 1K and 1B are vectors of all ones of the appropriate dimensions. Therefore, we restrict our attention to the set
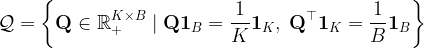 .
.
These constraints enforce that on average each prototype is selected at least B/K times in the batch.
We introduce a cost matrix, that is –C⊤Z. Each entry of this matrix is the dot product between a sample and a prototype and roughly represents the cost we are going to pay when we assign a sample to a prototype.
| Cluster 1 | Cluster 2 | … | Cluster K | |
| z1 | … | … | … | … |
| … | … | … | … | … |
| zn | 0.34 | -0.83 | … | 0.92 |
| … | … | … | … | … |
| zB | … | … | … | … |
We want to solve assignment problem under equipartition constraint and following a cost matrix.
Recall that, if M is a given D ⨉ D cost matrix, the cost of mapping r to c (two probability vectors) using a transport matrix (or joint probability) P can be quantified as ⟨P , M⟩, where ⟨.⟩ is the Frobenius product. If
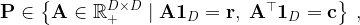
then the problem
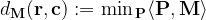
is called optimal transport (OT) problem between r and c given cost M (Cuturi, 2013). In this setting it is easy to restate the cluster assignment as the optimal transport problem

where H is the entropy function
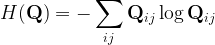
and  is a parameter. In essence, H(Q) is a regularization term. A solution to this regularized transport problem is in the form
is a parameter. In essence, H(Q) is a regularization term. A solution to this regularized transport problem is in the form

where u ∈ ℝK and v ∈ ℝB are two non negative vectors and the center matrix is the element-wise exponential of the matrix C⊤Z/ . The vectors u and v are computed with a small number of matrix multiplications using the iterative Sinkhorn-Knopp algorithm (see next paragraph for pseudocode).
Pseudocode
The following PyTorch pseudocode provides a better overall understanding.
# C: prototypes (DxK)
# model: convnet + projection head
# temp: temperature
for x in loader: # load a batch x with B samples
x_t = t(x) # t is a random augmentation
x_s = s(x) # s is another random augmentation
z = model(cat(x_t, x_s)) # embeddings: 2BxD
scores = mm(z, C) # prototype scores: 2BxK
scores_t = scores[:B]
scores_s = scores[B:]
# compute assignments
with torch.no_grad():
q_t = sinkhorn(scores_t)
q_s = sinkhorn(scores_s)
# convert scores to probabilities
p_t = Softmax(scores_t / temp)
p_s = Softmax(scores_s / temp)
# swap prediction problem
loss = - 0.5 * mean(q_t * log(p_s) + q_s * log(p_t))
# SGD update: network and prototypes
loss.backward()
update(model.params)
update(C)
# normalize prototypes
with torch.no_grad():
C = normalize(C, dim=0, p=2)The pseudocode for the Sinkhorn-Knopp algorithm is the following.
# Sinkhorn-Knopp
def sinkhorn(scores, eps=0.05, niters=3):
Q = exp(scores / eps).T
Q /= sum(Q)
K, B = Q.shape
u, r, c = zeros(K), ones(K) / K, ones(B) / B
for _ in range(niters):
u = sum(Q, dim=1)
Q *= (r / u).unsqueeze(1)
Q *= (c / sum(Q, dim=0)).unsqueeze(0)
return (Q / sum(Q, dim=0, keepdim=True)).TCheck the original article code implementation using PyTorch here.
Useful links
Original SwAV paper.
Original code implementation here.
Paper about optimal transport here.
Interesting video on the SwAV method.
Bio: Antonio Ferraioli is an AI aficionado living in southern Italy. Admin of "m0nads", a blog about AI (and its subfields) and Data Science.
Original. Reposted with permission.
Related: