7 Steps to Understanding Deep Learning
There are many deep learning resources freely available online, but it can be confusing knowing where to begin. Go from vague understanding of deep neural networks to knowledgeable practitioner in 7 steps!
Step 4: Getting Practical
 The specific neural network architectures that will be introduced in the following steps will include practical implementations using some of the most popular Python deep learning libraries present in research today. Since different libraries are, in some cases, optimized for particular neural network architectures, and have established footholds in certain fields of research, we will be making use of 3 separate deep learning libraries. This is not redundant; keeping up with the latest libraries for particular areas of practice is a critical part of learning. The following exercises will also allow you to evaluate different libraries for yourself, and form an intuition as to which to use for which problems.
The specific neural network architectures that will be introduced in the following steps will include practical implementations using some of the most popular Python deep learning libraries present in research today. Since different libraries are, in some cases, optimized for particular neural network architectures, and have established footholds in certain fields of research, we will be making use of 3 separate deep learning libraries. This is not redundant; keeping up with the latest libraries for particular areas of practice is a critical part of learning. The following exercises will also allow you to evaluate different libraries for yourself, and form an intuition as to which to use for which problems.
At this point you are welcome to choose any library or combination of libraries to install, and move forward implementing those tutorials which pertain to your choice. If you are looking to try one library and use it to implement one of each of the following steps' tutorials, I would recommend TensorFlow, for a few reasons. I will mention the most relevant (at least, in my view): it performs auto-differentiation, meaning that you (or, rather, the tutorial) does not have to worry about implementing backpropagation from scratch, likely making code easier to follow (especially for a newcomer).
I wrote about TensorFlow when it first came out in the post TensorFlow Disappoints – Google Deep Learning Falls Shallow, the title of which suggests that I had more disappointment with it than I actually did; I was primarily focused on its lack of GPU cluster-enabled network training (which is likely soon on its way). Anyhow, if you are interested in reading more about TensorFlow without consulting the whitepaper listed below, I would suggest reading my original article, and then following up with Zachary Lipton's well-written piece, TensorFlow is Terrific – A Sober Take on Deep Learning Acceleration.
Google's TensorFlow is an all-purpose machine learning library based on data flow graph representation.
- Install TensorFlow by visiting here
- Have a look at its whitepaper
- Try out its introductory tutorial
- Keep its documentation handy
Theano is actively developed by the LISA group at the University of Montreal.
- Install Theano by visiting here
- Try out an introductory tutorial
- Refer to its documentation here
Caffe is developed by the Berkeley Vision and Learning Center (BVLC) at UC Berkeley. While Theano and TensorFlow can be considered "general-purpose" deep learning libraries, Caffe, being developed by a computer vision group, is mostly thought of for just such tasks; however, it is also a fully general-purpose library for use building various deep learning architectures for different domains.
- Go here to install Caffe
- Read its introductory tutorial presentation to familiarize yourself
- Have a look at its documentation as well
Keep in mind that these are not the only popular libraries in use today. In fact, there are many, many others to choose from, and these were selected based on the prevelance of tutorials, documentation, and acceptance among research in general.
Other deep learning library options include:
- Keras - a high-level, minimalist Python neural network library for Theano and TensorFlow
- Lasagne - lightweight Python library for atop Theano
- Torch - Lua machine learning algorithm library
- Deeplearning4j - open source, distributed deep learning library for Java and Scala
- Chainer - a flexible, intuitive Python neural network library
- Mocha - a deep learning framework for Julia
With libraries installed, we now move on to practical implementation.
Step 5: Convolutional Neural Nets and Computer Vision
Computer vision deals with the processing and understanding of images and its symbolic information. Most of the field's recent breakthroughs have come from the use of deep neural networks. In particular, convolutional neural networks have played a very important role in computer vision of late.
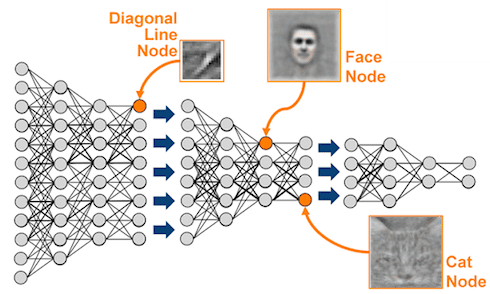
The convolutional neural network.
First, read this deep learning with computer vision tutorial by Yoshua Bengio, in order to gain an understanding of the topic.
Next, if you have TensorFlow installed, take a look at, and implement, this tutorial, which classifies CIFAR-10 images using a convolutional neural network.
If you have Caffe installed, as an alternative to the above tutorial (or alongside), implement a convolutional neural network in Caffe for classifying MNIST dataset images.
Here is a Theano tutorial which is roughly equivalent to the above Caffe exercise.
Afterward, read a seminal convolutional neural network paper by Krizhevsky, Sutskever, and Hinton for additional insight.
Step 6: Recurrent Nets and Language Processing
Natural language processing (NLP) is another domain which has seen benefits from deep learning. Concerned with understanding natural (human) languages, NLP has had a number of its most recent successes come by way of recurrent neural networks (RNN).
Andrej Karpathy has a fantastic blog post titled "The Unreasonable Effectiveness of Recurrent Neural Networks" which outlines the effectiveness of RNNs in training character-level language models. The code it references is written in Lua using Torch, so you can skip over that; the post is still useful on a purely conceptual level.
This tutorial implements a recurrent neural in TensorFlow for language modeling.
You can then use Theano and try your hand at this tutorial, which implements a recurrent neural network with word embeddings.
Finally, you can read Yoon Kim's Convolutional Neural Networks for Sentence Classification for another application of CNNs in language processing. Denny Britz has a blog post titled "Implementing A CNN For Text Classification in TensorFlow," which does just as it suggests using movie review data.
Step 7: Further Topics
The previous steps have progressed from theoretical to practical topics in deep learning. By installing and implementing convolutional neural nets and recurrent neural nets in the previous 2 steps, it is hoped that one has gained a preliminary appreciation for their power and functionality. As prevalent as CNNs and RNNs are, there are numerous other deep architectures in existence, with additional emerging from research on a regular basis.
There are also numerous other considerations for deep learning beyond those presented in the earlier theoretical steps, and as such, the following is a quick survey of some of these additional architectures and concerns.
For a further understanding of a particular type of recurrent neural network suited for time series prediction, the Long Short Term Memory Network, read this article by Christopher Olah.
This blog post by Denny Britz is a great tutorial on RNNs using LSTMs and Gated Recurrent Units (GRUs). See this paper for a further discussion of GRUs and LSTMs.
This clearly does not cover all deep learning architectures. Restrictive Boltzmann Machines are an obvious exclusion which comes to mind, as are autoencoders, and a whole series of related generative models including Generative Adversarial Networks. However, a line had to be drawn somewhere, or this post would continue ad infinitum.
For those interested in learning more about various deep learning architectures, I suggest this lengthy survey paper by Yoshua Bengio.
For our final number, and for something a bit different, have a look at A Statistical Analysis of Deep Learning by Shakir Mohamed of Google DeepMind. It is more theoretical and (surprise, statistical) than much of the other material we have encountered, but worth looking at for a different approach to familiar matter. Shakir wrote the series of articles over the course of 6 months, and is presented as testing wide-held beliefs, highlighting statistical connections, and the unseen implications of deep learning. There is a combined PDF of all posts as well.
It is hoped that enough information has been presented to give the reader an introductory overview of deep neural networks, as well as provide some incentive to move forward and learn more on the topic.
Related: