Recycling Deep Learning Models with Transfer Learning
Deep learning exploits gigantic datasets to produce powerful models. But what can we do when our datasets are comparatively small? Transfer learning by fine-tuning deep nets offers a way to leverage existing datasets to perform well on new tasks.
Deep learning models are indisputably the state of the art for many problems in machine perception. Using neural networks with many hidden layers of artificial neurons and millions of parameters, deep learning algorithms exploit both hardware capabilities and the abundance of gigantic datasets. In comparison, linear models saturate quickly and under-fit. But what if you don't have big data?
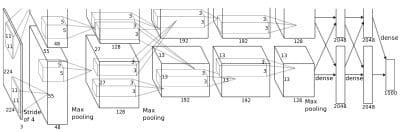
Say you have a novel research problem, such as identifying cancerous moles given photographs. Assume further that you generated a dataset of 10,000 labeled images. While this might seem like big data, it's a pittance by comparison to the authoritative datasets on which deep learning has its greatest successes. It might seem that all is lost. Fortunately there's hope.
Consider the famous ImageNet database created by Stanford Professor Fei-Fei Li. The dataset contains millions of images, each belonging to 1 of 1000 distinct hierarchically organized object categories. As Dr. Li relates in her TED talk, a child sees millions of distinct images while growing up. Intuitively, to train a model strong enough to compete with human object recognition capabilities, a similarly large training set might be required. Further, the methods which dominate at this scale of data might not be those which dominate on the same task given smaller datasets. Dr. Li's insight quickly paid off. Alex Krizhevsky, Ilya Sutskever and Geoffrey Hinton handily won the 2012 ImageNet competition, establishing convolutional neural networks (CNNs) as the state of the art in computer vision.
To extend Dr. Li's metaphor, although a child sees millions of images throughout development, once grown, a human can easily learn to recognize a new class of object, without learning to see from scratch. Now consider a CNN trained for object recognition on the ImageNet dataset. Given an image from any among the 1000 ImageNet categories, the top-most hidden layer of the neural network constitutes a single vector representation sufficiently flexible to be useful for classifying images into each of the 1000 categories. It seems reasonable to guess that this representation would also be useful for an additional as-of-yet unseen object category.
Following this line of thinking, computer vision researchers now commonly use pre-trained CNNs to generate representations for novel tasks, where the dataset may not be large enough to train an entire CNN from scratch. Another common tactic is to take the pre-trained ImageNet network and then to fine-tune the entire network to the novel task. This is typically done by training end-to-end with backpropagation and stochastic gradient descent. I first learned about this fine-tuning technique last year in conversations with Oscar Beijbom. Beijbom, a vision researcher at UCSD, has successfully used this technique to differentiate pictures of various types of coral.
A terrific paper from last year's NIPs conference by Jason Yosinski of Cornell, in collaboration with Jeff Clune, Yoshua Bengio and Hod Lipson, tackles this issue with a rigorous empirical investigation. The authors focus on the ImageNet dataset and the 8-layer AlexNet architecture of ImageNet fame. They note that the lowest layers of convolutional neural networks have long been known to resemble conventional computer vision features like edge detectors and Gabor filters. Further, they note that the topmost hidden layer is somewhat specialized to the task it was trained for. Therefore they systematically explore the following questions:
- Where does the transition from broadly useful to highly specialized features take place?
- What is the relative performance of fine-tuning an entire network vs. freezing the transferred layers?
To study these questions, the authors restrict their attention to the ImageNet dataset, but consider two 50-50 splits of the data into subsets A and B. In the first set of experiments, they split the data by randomly assigning each image category to either subset A or subset B. In the second set of experiments, the authors consider a split with greater contrast, assigning to one set only natural images and to the other only images of man-made objects.
The authors examine the case in which the network is pre-trained on task A and then trained further on B, keeping the first k layers and randomly initializing. They also consider the same experiment but pre-training on task B, randomly initializing the top 8-k layers, and then continuing to train on the same task B.
In all cases, they find that fine-tuning end-to-end on a pre-trained network outperforms freezing the transferred k layers completely. Interestingly they also find that when pre-trained layers are frozen, the transferability of features is nonlinear in the number of pre-trained layers. They hypothesize that this owes to complex interactions between the nodes in adjacent layers which are difficult to relearn.
To wax poetic, this might be analogous to performing a hemispherectomy on a fully grown human, replacing the right half of the brain with a blank slate child's brain. Ignoring the biological absurdity of this example it might seem intuitive that a fresh right brain hemisphere would have trouble filling the expected role of one to which the left hemisphere was fully adapted.
I defer to the original paper for a complete description of the experiments. One question which is not addressed in this paper but could inspire future research, is how these results hold up when the new task has far fewer examples than the original task. In practice, this imbalance in the number of labeled examples between the original task and the new one, is often what motivates transfer learning. A preliminary approach could be to repeat this exact work but with a 999 to 1 split instead of a 500-500 split of the categories.
Generally, data labeling is expensive. For many tasks it may even be prohibitively expensive. Thus it's of economic and academic interest to develop a deeper understanding of how we could leverage the labels we do have to perform well on tasks not as well endowed. Yosinski's work is a great step in this direction.
 Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. Funded by the Division of Biomedical Informatics, he is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs.
Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. Funded by the Division of Biomedical Informatics, he is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs.
Related:
- Deep Learning and the Triumph of Empiricism
- Not So Fast: Questioning Deep Learning IQ Results
- The Myth of Model Interpretability
- (Deep Learning’s Deep Flaws)’s Deep Flaws
- Data Science’s Most Used, Confused, and Abused Jargon
- Differential Privacy: How to make Privacy and Data Mining Compatible