MetaMind Mastermind Richard Socher: Uncut Interview
In a wide-ranging interview, Richard Socher opens up about MetaMind, deep learning, the nature of corporate research, and the future of machine learning.
Tuesday, at CrowdFlower's Rich Data Conference in San Francisco, I had a chance to sit down with MetaMind CEO Richard Socher for an interview. Dr. Socher was recently a highly coveted faculty candidate among elite computer science departments before pivoting to found MetaMind with eight million dollars in venture capital backing from Marc Benioff and Khosla Ventures. As a prominent deep learning researcher and Silicon Valley CEO, Socher sits at the intersection of several recurring themes here (deep learning, machine learning as a service, and the interplay between academia and industry).
For half an hour we discussed deep learning and MetaMind's business model. He described in some detail the mechanism of MetaMind's new dynamic memory model, which has set benchmarks on three fundamental NLP tasks. The following text is a transcription of an audio recording and has been lightly edited for stall words, readability, and to excise minor digressions, but is otherwise presented in full.
The interview begins informally, and recording commences as we discuss my January 2015 article about the hype and anti-hype of deep learning as typified by the commotion over deep learning's susceptibility to adversarial examples. ((Deep Learning’s Deep Flaws)’s Deep Flaws).

Richard Socher (RS): A similar case arises when it comes to classifying objects that weren't in the training data set. So, a user may train a dog vs cat classifier and then they give it a kangaroo and they expect that they'll get something other than dogs and cats as labels back. In some ways the demo we have on our website actually educates people in the sense that it shows them what's possible and what is not. Seeing limitations of a classifiers helps to some degree with hype-busting. I like that aspect of the on-line demo.
For instance, one journalist trained a cat vs dog classifier. And her three cat images, which is very little already, were all the same gray cat on the same brown grass background. A novice user might expect it to care about the cat and not about the brown grass background. Of course, the algorithm just tries to categorize the pictures in any way it can. Given an image of a dog on a brown grass background it will return the label cat. Especially if none of the handful of dog images had a brown background.
ZL: There were multiple valid separators of the data.
RS: Exactly. There's no magic. It doesn't know that you care about one specific object in the image.
ZL: That brings up a question I had wanted to ask during your talk. Earlier, you gave a very impressive demo. You take just 7-10 pictures of a Tesla and an already trained classifier, trained on the massive ImageNet dataset, which contains one million images from one thousand categories. On the spot, you produce a new classifier which recognizes Teslas.
So there's clearly a powerful transfer learning effect here. What kind of magic is going on under the hood? Do you use data augmentation to make those 7-10 examples superficially appear to be a much larger dataset?
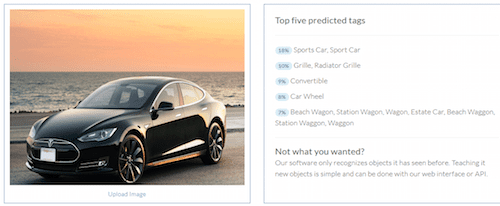
RS: There are some clever ways of adaptively training different parts of the model depending on how much data is provided. You're also right, that we use transfer learning. But there is no magic. For instance, if you only give it 5-10 images of cars from the outside, and then a test image of the inside of a car, it will be very confused.
The demo gives users a chance to see what's possible. You can quickly see if there's enough visual information in your dataset or not.
ZL: One thing that seems to be an obvious hack would be to take the 10 images and recognize the very specific subcategory they belong to. Then you only need to learn to differentiate among the small number of similar classes.
RS:There are lots of smart things that you could do, if you have other kinds of classes that are similar to what somebody is training. I think in the future, we'll get better and better at this. We've only implemented about half of all the tricks we can think of.
As a company, we are currently focused on bringing enterprise-grade image classifiers to market. In some cases, we provide full turn-key solutions where we collect relevant training data, run lots of experiments and at the end the customer has an on-prem package that just works.
In some ways where I think it's really exciting for us as a company is enterprise grade classifiers. So we actually create the whole classifier for somebody. We had a lot of folks reach out about food classification. It seemed very gimmicky in the beginning but it's actually a real thing. A lot of companies want to enable users to classify their food.
ZL: Is this processed food and you want to recover the ingredients?
RS: Oh that would be impossible in some cases. There's some potential information loss there when you look at an energy bar for instance. But if I take a picture of a pear or a sandwich it should tell me what's visible in the image.
ZL: So this brings us to what might have been my first question. MetaMind's business model seems to be that you've trained large scale deep learning systems on massive amounts of data. Then customers come with their more narrowly defined problems and you provide a solution as a service.
There are other companies like Google. And they're doing lots of machine learning, including deep learning, but bringing it to bear on search, or more cynically advertising. Either way, they're attacking a direct-to-consumer $400 billion problem. How did you come to settle on the business to business model of machine learning as service?
RS: To be perfectly honest, We're just starting to create our suite of AI-powered product offerings and this is only the start. Right now we're focused on enterprise-grade custom image classification. Because we've seen a lot of interest in that and our technology is ready.
One of the reasons why we've put this platform up is that we want to see how people actually use deep learning. If you could literally just drag and drop images in your browser, what would you do? That helped us to build the right technology that users really want. Food classification is one of them. Medical image classification is another. Other verticals are coming up.
ZL: Was it difficult to work with medical partners given privacy concerns?
RS:The medical industry does come with a special set of needs and restrictions and you have to be conscious of that. For instance, we need to provide on-prem [on-site] solutions.
ZL: You presented a new model in the talk, called a "dynamic memory network". For this audience it didn't get super technical, but the way you described it had the feeling of a neural Turing machine approach. Then when you showed a diagram it looked like a bidirectional recurrent net. Could you elaborate on how it works?
RS: You're right, there is actually a bidirectional sequence model inside several of the modules. The main research novelty is two-fold.
The first idea is to describe any NLP task as a question answering task over some input. It's an almost trivial insight, one you may have over drinks with friends at NIPS. By itself it's not that useful
ZL: The question being "what is the correct label?"
RS: Right, or "what is the answer?"
It becomes interesting, once you think of that generality and you try to build a model that solves a wide variety of different tasks. We applied this model to a question answering task that FaceBook published, to a sentiment analysis task that lots of researchers (including friends from Google) worked on and to part of speech tagging, which is one of the most studied tasks in NLP. The dynamic memory model actually gets better performance on these three tasks than anyone else in the world. I was excited when I saw what it can do.
The main modeling idea is that you take a question and use it to condition a neural attention mechanism that goes over some text. The text is represented in terms of hidden states of a bidirectional sequence model. Conditioned on the question, that attention mechanism goes over inputs at each time step, and connects them to an episodic memory module. That is, it opens a gate that lets the vector at a time step be fed into the episodic memory.
One important aspect for some tasks is that the model goes over the input multiple times. After each time it classifies the memory state by asking "do I know enough to answer the question?" And if not, then it goes over the input again, but conditioned on the question and also the previous memory state. That way it can reason over multiple facts. Once it classifies "yes I know enough", it gives that memory vector to an output sequence model which generates the answer.
ZL: This idea of confidence comes up a lot. The two notions that I've seen with softmax outputs are the probability given to the highest rated class and the entropy of the outputs. Do you have an opinion on which is better?
RS: I try not to have too strong of an opinion about things for which I can run experiments quickly. If you have a metric you want to optimize on a validation set, I usually try multiple hyperparameters. I've tried both of those. You can also sum up the probabilities of the top classes and if that sum gets above a certain threshold, that means the algorithm is pretty certain. It's a scientific question and sometimes the answers differ depending on your data set or your task.
ZL: I'd like to ask about the tension in the machine learning community between academia, which until recently was where virtually all machine learning research took place and industry. Specifically, you obviously had a very prolific PhD. You had faculty offers coming out of school before deciding to start MetaMind. Everyone in this field knows your work, largely through your published work and participation in conferences. It's clearly what's gotten you in a position to start MetaMind and also to attract top talent to the company.
And now you're in a position where you're also creating intellectual property which is owned by a company with stakeholders. Even given a purely capitalistic objective, there's seems to be a tension between doing the thing that gave you your mojo in the first place and defending your IP / having a competitive edge against your competitors. How do you balance these?
RS: I think there's only some mild tension. We want to continue publishing at MetaMind but we don't publish everything right away as an arXiv paper. We also wait on some inventions and ideas. We use a similar model to a lot of other really great companies, which is to first submit a patent and then put out a paper. With that, you have some protection.
The abstract idea or algorithm is in most cases only part of what makes a great product. You also need the people, engineering, packaging and data to actually put together a product. That's why some companies like Cloudera can exist on top of a largely open source stack.
ZL: This raises the issue of reproducibility in scientific research. Where do we draw the line for how much detail can be withheld from publication?
RS: I don't think anybody should withhold information from a paper that they know is important to getting the experimental results. Researchers should try to do the best job possible to describe their method.
ZL: Speaking of patenting, I just participated on a deep learning panel at a conference hosted by Yandex in Berlin. The first day had a focus on deep learning, but then on the third night Professor Vladimir Vapnik had the stage. And he gave an hour long talk and then debated the audience for a while. And he took a very critical stance on deep learning.
One point that he brought up a number of times is that deep learning does not fall under what he considers machine learning in the sense of not coming with a theoretical framework, or an understanding of mechanism. He suggested that it belonged more to the field of engineering. Generally, there was this tension between the idea of engineering and invention on one side and mathematics and nature on the other. The topic of patents seems relevant here. We don't really patent math. But neural network techniques increasingly are patented now, like drop-out for instance. Maybe you can comment on if machine learning is something that we invent or are these algorithms there in nature? What does it mean to patent a machine learning model?
RS:These are great questions. Why do we call our field computer science or why some departments call it computer engineering. A similar question arises over data science vs data engineering.
Vapnik, who came up with the concept of VC dimensions, had deep insight into learning theory. Some neuroscientists really look at the brain and try to understand how we as humans learn and how other animals learn. For the field of AI we need to also ask ourselves how we define intelligence? It seems to be a moving definition, as soon as we can do a certain task, we often don't call it AI anymore. It is then just about engineering a system to do speech recognition, for instance.
Long story short, I think a large part of machine learning is an engineering discipline. For instance, I don't think the recursive neural tensor network I invented was in nature. It was an idea, based on experience and intuition. The goal was to create an algorithm with high accuracy and good performance in terms of speed. Generally, I love working on models that are very general. Models that can be applied to a large set of different AI tasks. It's great when these models are inspired by neuroscience. That's how we ended up calling one module the episodic memory [in the dynamic memory model], but it's usually a very loose inspiration. Most of the time is spent on engineering the algorithms, to enable them to make lots of accurate predictions.
ZL: On the topic of neuroscience inspiration. I feel as though in the deep learning community, there's a tendency to downplay the biological connection. Then you look at all the popular news coverage and there's a lot of hype about systems that work like brains. When you choose the name MetaMind, do you tactfully play off that hype?
RS: The definition of "mind" is much fuzzier and abstract than the definition of "brain." The reason we're called MetaMind is that eventually we want to have different types of "minds" which focus on different solutions.
ZL: Very last question. I know you're used to speaking at academic conferences, which are long on mathematical detail. And now you're speaking at a business conference, where the only equation I've seen all day was surprisingly in Nate Silver's talk when he showed a slide with a photograph of a neon Bayes' theorem sign. How's the experience for you? And what's your objective in speaking here?
RS: It's a different experience with different objectives. In an academic conference you're trying to get people excited about your intellectual ideas, you want them to replicate your models and then build on them. You have to explain how and why it works. In a business conference you get people excited about using your product because your product is easy to use and abstracts away a lot of the underlying complexity. Both are interesting in their own ways.
 Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. Funded by the Division of Biomedical Informatics, he is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, is a Contributing Editor at KDnuggets, and has signed on as an author at Manning Publications.
Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. Funded by the Division of Biomedical Informatics, he is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, is a Contributing Editor at KDnuggets, and has signed on as an author at Manning Publications.
Related:
- Does Deep Learning Come from the Devil?
- MetaMind Competes with IBM Watson Analytics and Microsoft Azure Machine Learning
- Deep Learning and the Triumph of Empiricism
- The Myth of Model Interpretability
- (Deep Learning’s Deep Flaws)’s Deep Flaws
- Data Science’s Most Used, Confused, and Abused Jargon