 Making Sense of Machine Learning
Making Sense of Machine Learning
 Making Sense of Machine Learning
Making Sense of Machine LearningBroadly speaking, machine learners are computer algorithms designed for pattern recognition, curve fitting, classification and clustering. The word learning in the term stems from the ability to learn from data.
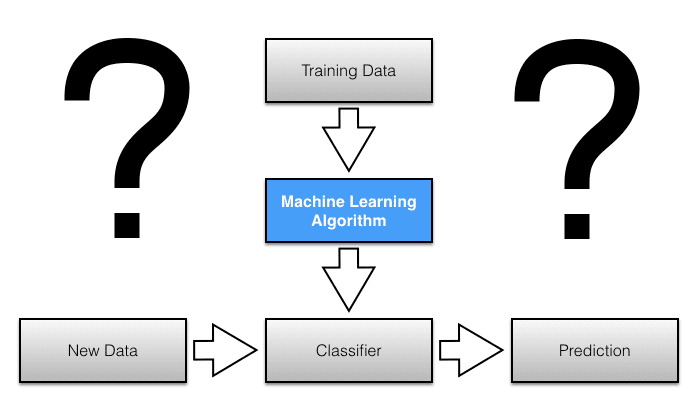
Source: Sebastian Raschka (sebastianraschka.com/Articles/2014_intro_supervised_learning.html)
Machine learning gets a lot of buzz these days, usually in connection with big data and artificial intelligence (AI). But what exactly is it? Broadly speaking, machine learners are computer algorithms designed for pattern recognition, curve fitting, classification and clustering. The word learning in the term stems from the ability to learn from data. Machine learning is also widely used in data mining and predictive analytics, which some commentators loosely call big data. It also is used for consumer survey analytics and is not restricted to high-volume, high-velocity data or unstructured data and need not have any connection with AI.
In fact, many methods marketing researchers are well acquainted with, such as regression and k-means clustering, are also frequently called machine learners. For examples, see Apache Spark's machine learning library or the books I cite in the last section of this article. To keep things simple, I will refer to well-known statistical techniques like regression and factor analysis as older machine learners and methods such as artificial neural networks as newer machine learners since they are generally less familiar to marketing researchers.
Machine learning is used for many purposes such as in seismology, medical research, computer network security and human resource management. The following are some of the more common ways machine learners of any vintage are used in marketing:
- predicting how likely a customer is to buy a certain product;
- estimating how much a customer will spend in a product category;
- identifying relatively homogenous consumer groups – consumer segmentation;
- finding the key drivers (What service elements best predict customer satisfaction?);
- in marketing mix modeling (identifying marketing activities with the biggest payoff);
- for recommender systems (e.g., people who bought John Grisham also bought Scott Turow);
- for individually targeted ads; and
- in social media analytics.
Types of machine learners
There are literally hundreds of machine learners and many are used for multiple purposes. Some machine learners are extremely complex and others are ingeniously simple and they can be categorized in numerous ways. Here are a few examples:
- Supervised methods are used when there is a dependent variable. Regression and discriminant analysis are supervised methods. The dependent variable is often called a label by data scientists.
- Supervised methods are further subdivided by whether the label is a category, such as purchaser/non purchaser, or a quantity, such as amount spent. Discriminant analysis is appropriate in the first case, which statisticians call a classification problem, and regression analysis in the second, known as a regression problem.
- Unsupervised methods are used when there are no dependent variables, as in clustering and factor analysis.
- Time-series methods such as ARMAX and GARCH are needed when the data have been collected at many points in time, for instance weekly or daily sales figures. Marketing researchers are generally better acquainted with cross-sectional research, such as one-time consumer surveys. Regression, discriminant analysis and factor analysis are techniques commonly used to analyze cross-sectional data.
- Association pattern mining, used to rationalize shelf placement, and for recommender systems.
- There are also many specialized methods for text analytics, social network analysis, Web analytics, mining streaming data and anomaly detection (e.g., for detecting credit card fraud).
Popular machine learners
Let’s take quick peek under the hood of four of the newer machine learners. Please keep in mind that many lengthy books have been written about machine learning and my intention here is to give you a flavor of how a few of the more popular approaches work.
Artificial neural networks (ANN) are sophisticated and versatile learners used for a wide range of purposes. Though hard to describe simply, ANN have been inspired by notions of how the human brain functions. They come in many flavors and are used for classification, regression, clustering, text mining and for assortment of real-time analytics. ANN are also frequently a core part of artificial intelligence and deep learning. Downsides can include long runtimes, the tendency to overfit (predict new data poorly), and that they are hard to interpret owing to their complexity. Neural networks and AI are sometimes used synonymously, which is misleading since other machine learners are also used in AI software.
Support vector machines (SVM) were originally proposed in the Soviet Union in the early 1960s. Though first developed for binary (two-group) classification problems, these machine learners have been extended to multi-group classification and quantitative dependent variables and are now used for a variety of applications. Like ANN, SVM are complex but the basic idea – shown in this image – is to construct a hyperplane or set of hyperplanes that can be used for classification, regression and other tasks. Runtimes can be quite long, especially with very large data files, and choices the modeler makes can have a big impact on the results (also true of ANN and many other tools). SVM attract considerable interest in the machine learning community and there have been many recent advances in this area.
Random forests and AdaBoost – short for adaptive boosting – are highly popular among data scientists. Their most common implementations employ a committee of fools’ strategy. Random forests is fast and well-suited for parallel computing. It's easy to use and works well for predicting either group memberships or quantities. Random selections of cases (e.g., consumers) and variables are used to build hundreds or sometimes thousands of weak learners – mini-models that predict poorly but better than chance – and the modal or median result used as the prediction for each case. Most often random forests are based on decision trees but other methods can be used as base learners. One downside is that random forests is perhaps too easy and less experienced modelers may be tempted to choose it over other methods that would perform better.
AdaBoost, likewise, is versatile and not restricted to decision trees as the base learner, though decision trees are fast to run and usually adequate. A major point of differentiation from random forests is that all cases are used and weighted up or down depending on how difficult they are to predict accurately, with hard cases receiving more weight as the algorithm passes through the data. With very noisy data, AdaBoost can perform poorly by chasing outliers. As is true of random forests, there are variations of boosting and one kind, stochastic gradient boosting, has become especially popular in recent years.
Key points to remember
There are a vast number of machine learners that come in handy for all sorts of analytics in many fields. Some have only appeared in the past few years while others were developed decades ago and, as I've noted, the meaning of machine learning itself is not clear-cut. It's best to ask for specifics when you are not certain how the term is being used.
No single machine learner will work best in all situations and it's not unusual for multiple algorithms to be combined. The chief advantages of what I am calling the newer methods are that they can be faster, easier to use or more accurate in certain situations. Examples include:
- when there are a very large number of variables;
- when there are strong curvilinear relationships or interactions in the data; and
- when the statistical assumptions of older methods are seriously violated.
Older methods can still be used effectively in these circumstances but model-building can sometimes become quite time-consuming. In addition, some newer software has been designed for specific purposes – such as text analytics – and will nearly always be the better choice for those purposes.
A downside of the newer methods is that they are typically less helpful for understanding the mechanism that gave rise to the data (for example, why certain types of consumers behave as they do). Most newer machine learners do not use equations that can be readily understood by non-specialists or easily put into words. Older methods, on the other hand, are usually more informative. That said, it's not always either/or and in some projects we can enjoy the best of both worlds by using newer machine learners for predictive modeling and older ones to shed light on the why and how.
Another advantage of the older machine learners is that they generally require smaller training samples to achieve the same level of accuracy on new data. Most were developed during an era in which data collection and processing were much more expensive. This can be a big advantage as most marketing researchers analyze small data.
Whatever method or combination of methods used, I should stress that machine learning is not simply a matter of pressing ENTER. Defining the goals and objectives of the project and having a team of people with the right mix of skills and experience is still essential. Likewise, machine learners are only part of the whole process, and data setup and cleaning usually absorb a substantial part of an analyst's time. “Data, data, data: Understanding the role of predictive analytics” gives a snapshot of this process as well as some tips on things to do and things to avoid.
Additional resources
If you're interested in learning more about this subject there are many resources, including massive open online courses and formal degree programs in data science offered by some universities. A strong background in statistics (by the usual definition) will also prove to be invaluable and – in my opinion – that's really the place to begin.
Two popular data science Web sites are KDnuggets and Data Science Central. Many excellent textbooks have also been published. Here are a few I've found helpful: Data Mining Techniques (Linoff and Berry); Applied Predictive Modeling (Kuhn and Johnson); Elements of Statistical Learning (Hastie et al.); Data Mining: The Textbook (Aggarwal); and Pattern Recognition and Machine Learning (Bishop). Probabilistic Graphical Models(Koller and Friedman) and Artificial Intelligence (Russell and Norvig) are massive volumes and also authoritative references on machine learning and AI.
Bio: Kevin Gray is president of Cannon Gray, a marketing science and analytics consultancy.
Original. Reposted with permission.
Related: