Training and Visualising Word Vectors
In this tutorial I want to show how you can implement a skip gram model in tensorflow to generate word vectors for any text you are working with and then use tensorboard to visualize them.
By Priyanka Kochhar, Deep Learning Consultant
In this tutorial I want to show how you can implement a skip gram model in tensorflow to generate word vectors for any text you are working with and then use tensorboard to visualize them. I found this exercise super useful to i) understand how skip gram model works and ii) get a feel for the kind of relationship these vectors are capturing about your text before you use them downstream in CNNs or RNNs.
I trained a skip gram model on text8 dataset which is collection of English Wikipedia articles. I used Tensorboard to visualize the embeddings. Tensorboard allows you to see the whole word cloud by using PCA to select 3 main axis to project the data. Super cool! You can type in any word and it will show its neighbours. You can also isolate the 101 points closest to it.
See clip below.
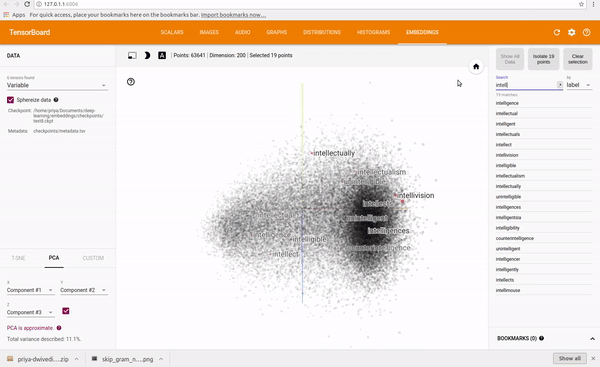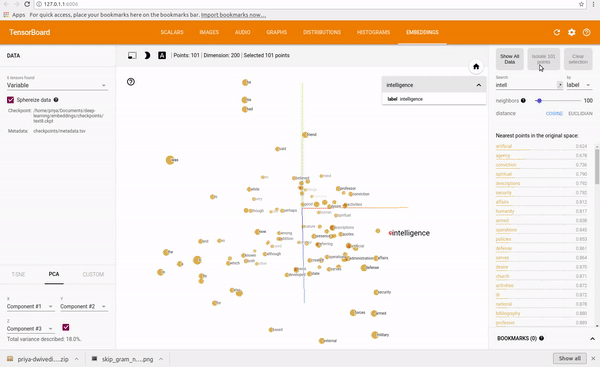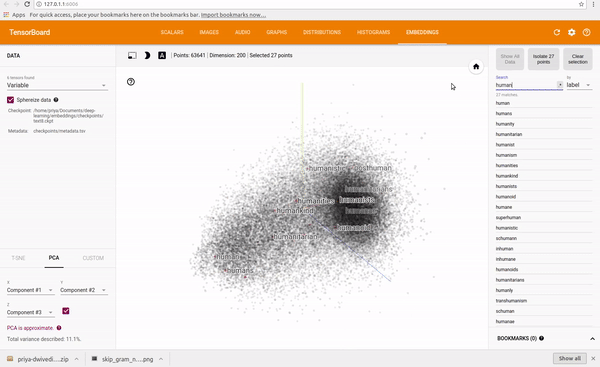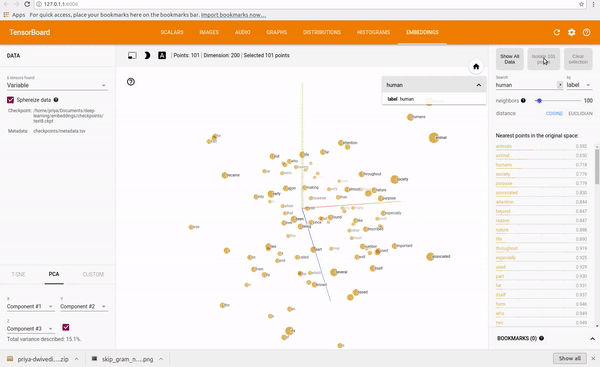
You can find the full code on my Github repo.
To visualize training, I also looked at the closest predicted word to a random set of words. In the first iteration the closest predicted words seem very arbitrary which makes sense since all word vectors were randomly initialized
Nearest to cost: sensationalism, adversity, ldp, durians, hennepin, expound, skylark, wolfowitz, Nearest to engine: vdash, alloys, fsb, seafaring, tundra, frot, arsenic, invalidate, Nearest to construction: dolphins, camels, quantifier, hellenes, accents, contemporary, colm, cyprian, Nearest to http: internally, chaffee, avoid, oilers, mystic, chappell, vascones, cruciger,
By the end of training, the model had become much better at finding relationship between words.
Nearest to cost: expense, expensive, purchase, technologies, inconsistent, part, dollars, commercial, Nearest to engine: engines, combustion, piston, stroke, exhaust, cylinder, jet, thrust, Nearest to construction: completed, constructed, bridge, tourism, built, materials, building, designed, Nearest to http: www, htm, com, edu, html, org, php, ac,
Word2Vec and Skip Gram model
Creating word vectors is the process of taking a large corpus of text and creating a vector for each word such that words that share common contexts in the corpus are located in close proximity to one another in the vector space.
These word vectors can get amazingly good at capturing contextual relationship between words (example vectors for black, white and red would be close together) and we get far better performance with using these vectors instead of raw words for NLP tasks like text classification or new text generation.
There are two main models for generating these word vectors — Continuous Bag of Words (CBOW) and Skip Gram Model. The CBOW model tries to predict the center word given context word while skip gram model tries to predict context words given center word. A simplified example would be:
CBOW: The cat ate _____. Fill in the blank, in this case, it’s “food”.
Skip-gram: ___ ___ ___ food. Complete the word’s context. In this case, it’s “The cat ate”
If you are interested in a more detailed comparison of these two methods, then please see this link.
Various papers have found that Skip gram model results in better word vectors and so I have focused on implementing that.
Implementing Skip Gram model in Tensorflow
Here I will list the main steps to build the model. Please see the detailed implementation on my Github
1. Preprocessing the data
We first clean our data. Remove any punctuation, digits and split the text into individual words. Since programs deal much better with integers than words we map every word to an int by creating a vocab to int dictionary. Code below.
counts = collections.Counter(words)
vocab = sorted(counts, key=counts.get, reverse=True)
vocab_to_int = {word: ii for ii, word in enumerate(vocab, 0)}
2. Subsampling
Words that show up often such as “the”, “of”, and “for” don’t provide much context to the nearby words. If we discard some of them, we can remove some of the noise from our data and in return get faster training and better representations. This process is called subsampling by Mikolov. For each word in the training set, we’ll discard it with probability given by inverse of its frequency.
3. Creating inputs and targets
The input for skip gram is each word (coded as int) and the target is words around that window. Mikolov et al found that performance was better if this window was variable in size and words closer to to the center word were sampled more frequently.
“Since the more distant words are usually less related to the current word than those close to it, we give less weight to the distant words by sampling less from those words in our training examples… If we choose window size=5, for each training word we will select randomly a number R in range between 1 and window size, and then use R words from history and R words from the future of the current word as correct labels.”
R = np.random.randint(1, window_size+1) start = idx — R if (idx — R) > 0 else 0 stop = idx + R target_words = set(words[start:idx] + words[idx+1:stop+1])
4. Building the model
From Chris McCormick’s blog, we can see the general structure of the network that we will build.
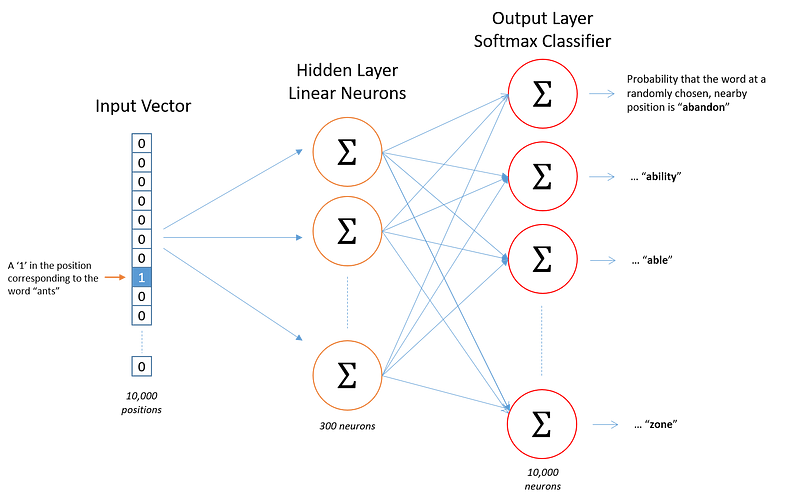
We’re going to represent an input word like “ants” as a one-hot vector. This vector will have 10,000 components (one for every word in our vocabulary) and we’ll place a “1” in the position corresponding to the word “ants”, and 0s in all of the other positions.
The output of the network is a single vector (also with 10,000 components) containing, for every word in our vocabulary, the probability that a randomly selected nearby word is that vocabulary word.
At the end of training the hidden layer will have the trained word vectors. The size of the hidden layer corresponds to the num of dimensions in our vector. In the example above each word will have a vector of length 300.
You may have noticed that the skip-gram neural network contains a huge number of weights… For our example with 300 features and a vocab of 10,000 words, that’s 3M weights in the hidden layer and output layer each! Training this on a large dataset would be prohibitive, so the word2vec authors introduced a number of tweaks to make training feasible. You can read more about them in the link. The code on Github implements these to speed up training.
5. Visualizing using Tensorboard
You can using the embeddings projector in Tensorboard to visualize the embeddings. To do this you need to do a few things:
- Save your model at the end of training in a checkpoints directory
- Create a metadata.tsv file that has the mapping for each int back to word so that Tensorboard displays words instead of ints. Save this tsv file in the same checkpoints directory
- Run this code:
from tensorflow.contrib.tensorboard.plugins import projector summary_writer = tf.summary.FileWriter(‘checkpoints’, sess.graph) config = projector.ProjectorConfig() embedding_conf = config.embeddings.add() # embedding_conf.tensor_name = ‘embedding:0’ embedding_conf.metadata_path = os.path.join(‘checkpoints’, ‘metadata.tsv’) projector.visualize_embeddings(summary_writer, config)
- Open tensorboard by pointing it to the checkpoints directory
That’s it!
Give me a ❤️ if you liked this post:) Hope you pull the code and try it yourself. If you have other ideas on this topic please comment on this post or mail me at priya.toronto3@gmail.com
Other writings: https://medium.com/@priya.dwivedi/
PS: I have a deep learning consultancy and love to work on interesting problems. If you have a project that we can work collaborate on then please contact me at priya.toronto3@gmail.com
References:
- Udacity Deep Learning Nanodegree
Bio: Priyanka Kochhar has been a data scientist for 10+ years. She now has her own deep learning consultancy and loves to work on interesting problems. She has helped several startups deploy innovative AI based solutions. If you have a project that she can collaborate on then please contact her at priya.toronto3@gmail.com
Original. Reposted with permission.
Related:
- A Framework for Approaching Textual Data Science Tasks
- A General Approach to Preprocessing Text Data
- Beyond Word2Vec Usage For Only Words